
こんにちは、マイクロアド機械学習エンジニアチームの河本(@nnkkmto)です。今回、モデル学習における課題解決に向けて GCP における機械学習基盤に AI Platform Pipelines (Kubeflow Pipelines) を導入しました。今回はその内容について紹介します。
従来の方法
マイクロアドでは学習実行基盤として GCP (Google Cloud Platform) を採用しています。
定期的な学習が必要な推論モデルは、 AI Platform Training の単一の job として学習処理の含まれるイメージを cron 実行することで行っていました。
デプロイ・実行をまとめると以下のような構成になっています。
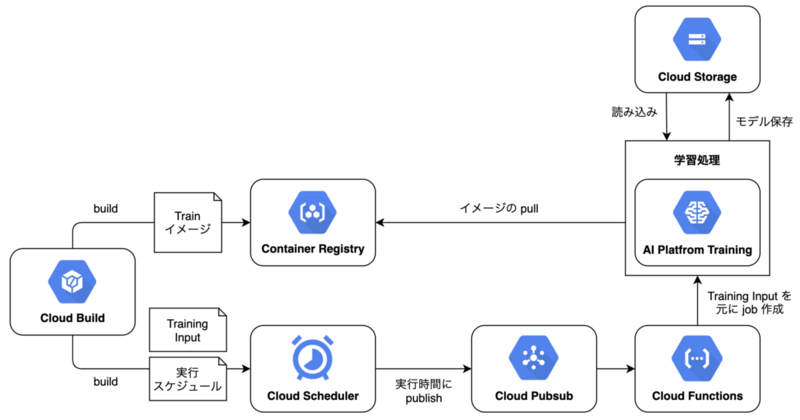
抱えていた課題
まず、上記構成に由来して「並行に学習を実行することが難しい」ことが課題として存在していました。 例えば、同じ学習処理を複数のサービスに対して行う場合に、学習処理を並行に走らせることができないため対象のサービスの増加に従い学習処理全体で必要な時間も増えてしまうというようなことが発生していました。
また、機械学習モデルの開発に由来する課題として「コードの再利用が難しい」ということがありました。
具体的には、
- 検証用コードを本番用コードとして使用できない
- 検証ごとにコードを書く必要がある
- 検証間で成果物を再利用できない
といったことが挙げられます。前者は検証完了から本番導入までの開発コストの増加、後者2つは検証ごとのコストの増加に繋がります。
検証サイクルを回すことに時間がかかる一方、そこから本番環境にモデルを導入するのにも時間がかかるという状況になっていました。
手段:AI Platform Pipelines
上記のような課題を抱え調査する中で、以下のような記事から解決手段として GCP における Kubeflow Pipelines のマネージドサービスである AI Platform Pipelines が適切なのではないかと考えました。
ここでは AI Platform Pipelines の概要説明は省略しますが、
- 一連の学習処理をワークフローとして記述できること
- コンポーネントとしてコードの再利用が可能であること
- コンポーネントにおいて前回と同じインプットで実行する場合、キャッシュされた前回実行時の結果を再利用できること
が、上記の課題を解決する特徴となっています。
これにより、学習処理の並行実行、検証を本番導入用コードに書き直すための開発コストの削減、検証サイクルの高速化が期待できます。
また、マイクロアドでは機械学習エンジニアが本番環境での運用も担当しているのですが、GKE 及び Kubernetes の知見がまだ蓄積されていないという背景があります。そのため、他の GCP のサービスと連携が可能(重い処理を Kubernetes 上で実行しなくて済む)という点も選定理由となっています。
導入時の方向性
新規サービスの導入となり、影響範囲が他のチームメンバーにも及ぶことから
- 学習コストを最小化すること
- 処理を実装する人視点での既存の構成との差分を最小化すること
まず前者に関しては、前述の通りチームに GKE (Kubernetes) の導入実績がないため、できるだけ Kubeflow Pipelines のみ学習すればいいように、他サービスに処理を委譲することで GKE 上での処理を最小化するようにしました。
また、後者に関しては
- Cloud Build 経由での CI / CD を最初から導入しておくこと
- 共通のデプロイ処理を学習処理から分離した形で用意しておくこと
を導入前に方向性として設定していました。
導入内容
実際に導入した内容については以下となります。
実行処理
実行処理としては、以下のように
- Component は Container Registry に格納
- Kubeflow Pipelines の Recurring Run による cron 実行
- 生成物は Cloud Storage に格納し Component 間で受け渡す
という形で行っています。
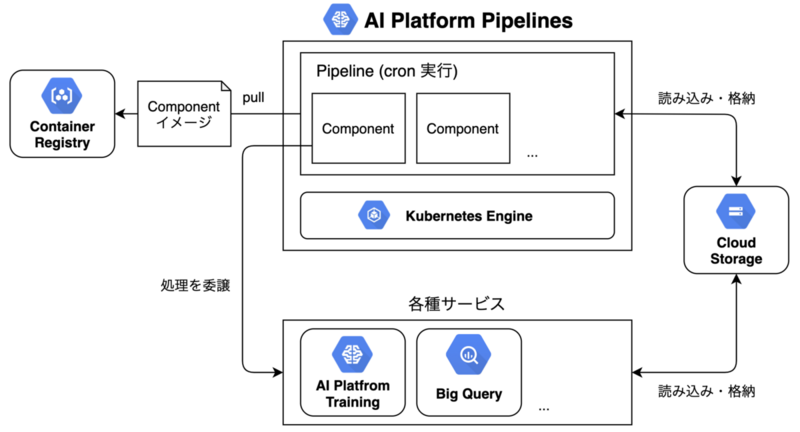
CI / CD
AI Platform Pipelines の CI / CD に関しては、パイプラインとその引数を格納したファイルをどのようにデプロイするかを決定する必要がありました。
今回は認証周りの実装をしたくなかったこと、前述の通りデプロイ処理を切り出したかったことから、Cloud Pub/Sub への publish をトリガーとする Cloud Functions を用意し、
- Cloud Storage にパイプラインと設定ファイルを保存
- Cloud Pub/Sub へ実行情報を publish
- Cloud Functions が起動、パイプライン・設定ファイル・実行情報を元に AI Platform Pipelines にデプロイ
という手順でデプロイするようにしています。
以下が具体的な構成となります。
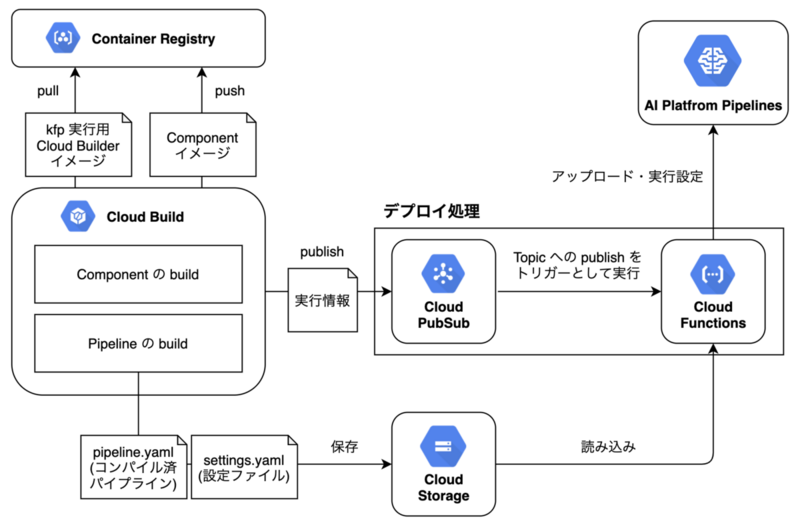
ここで、Kubeflow の Python 用 SDK である kfp を実行するための Cloud Builder はデフォルトで存在しないため、以下を参考に実装し Cloud Registry に格納しています。
Cloud Functions 内部での処理は以下のようにシンプルなものになっています。
import os import json import base64 import datetime import kfp import kfp.dsl as dsl import yaml import gcsfs def get_current_pipeline(client, pipeline_name): exist_pipelines = client.list_pipelines(page_size=1000) exist_pipeline = None for pipeline in exist_pipelines.pipelines: if pipeline.name == pipeline_name: exist_pipeline = pipeline return exist_pipeline def load_yaml_from_gcs(file_path): fs = gcsfs.GCSFileSystem() with fs.open(file_path, 'r') as f: obj = yaml.safe_load(f) return obj def deploy_pipeline(event, context): # pub/sub経由のmessageの読み込み payload = json.loads(base64.b64decode(event['data']).decode('utf-8')) gcs_path = payload["gcsPath"] pipeline_name = payload["pipelineName"] pipeline_host = payload["pipelineHost"] experiment_name = payload["experimentName"] schedule = None if 'schedule' in payload: schedule = payload["schedule"] # GCSからpipeline.yamlとsettings.yamlを取得 setting_file_path = os.path.join(gcs_path, "settings.yaml") settings = load_yaml_from_gcs(setting_file_path) pipeline_file_path = os.path.join(gcs_path, "pipeline.yaml") pipeline = load_yaml_from_gcs(pipeline_file_path) client = kfp.Client(host=pipeline_host) # 同じpipeline_nameのパイプラインが存在すればその情報を取得 exist_pipeline = get_current_pipeline(client, pipeline_name) # ローカルにあるものでないとアップロードできないため一時ディレクトリに保存 with open("/tmp/pipeline.yaml", "w") as f: yaml.dump(pipeline, f) upload_time = datetime.datetime.now().strftime('%Y%m%d-%H%M%S') if exist_pipeline is None: # 同じpipeline_nameが存在しない場合は新規パイプラインとしてアップロード pipeline = client.upload_pipeline( pipeline_package_path="/tmp/pipeline.yaml", pipeline_name=pipeline_name) pipeline_id = pipeline.id else: # 存在する場合はパイプラインに新規versionとしてアップロード pipeline_version = upload_time client.upload_pipeline_version( pipeline_package_path="/tmp/pipeline.yaml", pipeline_name=pipeline_name, pipeline_version_name=upload_time ) # versionのアップデートの場合versionにひもづくidが返ってくるため pipeline = exist_pipeline pipeline_id = pipeline.id # experimentの作成 experiment = client.create_experiment(name=experiment_name) experiment_id = experiment.id run_id = 'run-' + upload_time if schedule is None: response = client.run_pipeline( experiment_id, job_name=run_id, pipeline_id=pipeline_id, params=settings) else: # scheduleが設定されている場合はrecurring run response = client.create_recurring_run( experiment_id, cron_expression=schedule, job_name=run_id, pipeline_id=pipeline_id, params=settings)
終わりに
マイクロアドの機械学習エンジニアチームは、スピード感を持った課題解決・改善を行うことを目的に、以下のようなチームを目指しています。
- 問題設定から検証・開発・運用まで一貫して機械学習エンジニアで担当すること
- スピード感を持って課題解決・改善に向けたサイクルを回すこと
- ボトムアップでの課題解決
今回の機械学習基盤の改善に関しては改善サイクルの高速化に対応した課題の解決になっています。
以上のように、開発・モデル検証含めて、機械学習周りの課題解決を進めていきたい方を募集しています。
参考
- Machine Learning Operations (MLOps): Getting Started | Coursera
- pipelines/samples at master · kubeflow/pipelines · GitHub
- kubeflow-examples/kfp-cloudbuild at master · ksalama/kubeflow-examples · GitHub
- https://github.com/kubeflow/examples/blob/cookbook/cookbook/pipelines/notebooks/gcf_kfp_trigger.ipynb
- AI Platform Pipelines (Kubeflow Pipelines)による機械学習パイプラインの構築と本番導入 - ZOZO TECH BLOG
- GCP AI Platform Pipelines 選定時の観点と運用した所感 - Atrae Tech Blog
- KARTEにおけるKubeflow Pipelineの活用 | PLAID engineer blog