はじめに
こんにちは。マイクロアドで機械学習エンジニアをしている津野です。 21卒でマイクロアドに入社し、現在はUNIVERSE Adsというプロダクトで KPI達成確率予測の研究開発および実装を担当しています。 この記事では、自分が現在担当しているKPI達成確率予測について紹介させて頂きます。
問題設定
KPI達成確率予測(以下、KPI予測)とは、ユーザが新規セッションにおいて特定のKPI行動を達成するかどうかを予測するタスクです。
ここで言うセッションとは、ユーザが特定のウェブサイト上で行った一連の操作のことです1。 例えば、1回のセッションには、ページビュー、イベント、ソーシャルインタラクション、eコマーストランザクションなどの複数のユーザ行動(アクション)が含まれます。 セッションはユーザがサイトから離脱した場合や一定時間操作を行わなかった場合に終了し、そのユーザが再度ウェブサイトの操作を行なった場合は新しいセッションとして記録されます。
KPIとは、サービスごとに顧客が目標達成のために設定している指標のことで、例えば、課金やアプリインストールなどが挙げられます。
KPI予測は、KPIが紐づくサービス × ユーザ × セッション粒度の入力特徴量に対して推論するタスクです。 このため、同じユーザのデータであってもサービスやセッションが違う場合、別のデータとして扱っています。 特徴量は、推論対象となる新規セッションより以前のセッションで行ったユーザのアクションとユーザのデバイス情報を使用しています。 このような昔のセッション情報を用いて行動予測を行うタスクは、session-awareと呼ばれています2。
KPI予測の入出力データのイメージを示したのが下図です。 緑が学習時のデータ、青が推論時のデータを表しています。白い箱はセッションを表しており、箱の左辺がセッション開始、箱の右辺がセッション終了を表しています。 黒の縦棒は何らかのユーザのアクション、緑の縦棒はKPI達成を表しています。

学習の図(緑)は、session1、session2、session3はKPI達成が起きていないということを意味しており、反対に緑の縦棒が存在するsession4はそのセッション中にKPI達成が起こったことを示しています。 また、学習データ1、学習データ2、学習データ3は同じユーザのデータであってもセッションが異なるので、違うデータとして扱っています。学習データ2は学習データ1のセッション中のアクションを、学習データ3は学習データ1と2のアクションを含んだ特徴量になっています。
推論の図(青)は、学習時と推論時のデータの乖離を示しています。Real Time Bidding(RTB)においてKPI予測を利用するにはユーザがサイトに訪問したタイミングで推論を行う必要があります。 そのため、新規セッションの開始かどうかはリアルタイムには判断できず、新規セッション開始から推論時(RTBリクエスト時)の間に行ったアクションも特徴量として含んだ状態で推論してしまう可能性があります。 この学習時と推論時のデータの乖離はKPI予測の課題の1つですが、今回は特に考慮せず推論を行っています。
最後に、KPI予測はKPIの達成有無(CV)を予測するタスクであるため、広義のCVR予測とみなせるかもしれません。しかし、CVR予測は特徴量に広告情報を用いている点や、セッションではなく特定期間内(30日以内など)のCV達成有無を予測するタスクとして考えている点など、いくつか違いが存在しています。
入力
入力は、KPIが紐づくサービス × ユーザ × セッションの粒度の特徴量です。 具体的には、推論対象の新規セッションよりも過去のセッションで行ったユーザのアクション特徴量やユーザのデバイス特徴量になります。
ユーザのデバイス特徴量は、ユーザがどのようなデバイス(PCやスマホなど)やブラウザ等を使っていたかの情報です。
ユーザのアクション特徴量は、過去にユーザが行ったアクションを異なる時間間隔で記録した時系列配列です。 ただし、実際にモデルに入力する際は後述の前処理で次元削減して利用しています。 また、アクションは複数種類存在しているので、最終的な入力特徴量数はアクション種類 × アクション特徴量 + ユーザのデバイス特徴量になります。 ここで、出現するアクション種類はサービスによって変わるので、KPI予測モデルごとに入力特徴量数が異なるのが特徴です。
出力
出力は推論対象の新規セッションのKPI達成確率で、教師ラベルはKPI未達成を0(負例)、KPI達成を1(正例)としたバイナリで学習します。 KPI達成判定は、サービス × ユーザ × セッションが同一なデータが24時間以内にKPI達成が発生している場合に、達成としています。 24時間に関しては、ユーザが同じセッションに24時間以上滞在するとは考えにくいため、この閾値にしています。
前処理
異なる時間間隔で計測されたアクションの時系列配列に対して、 セッション開始時間(推論時はRTBのリクエスト時間)と最後にアクションを行った時間の時差を0でパディングして補正した後に、固定長配列に圧縮しています。
ユーザのデバイス特徴量は、Label Encordingによってカテゴリ変換しています。
モデル
RTBとのレスポンス時間が5ms以内という制約があるため、高速に推論処理ができるlightgbmを採用しました。
精度検証
あるサービスの1日分のデータをモデルに学習させて、翌日の1日分のデータをテストデータとして与えた時のKPI予測のオフライン精度検証を行いました。ただし、今回モデルの学習にearly_stoppingを使用したため、実際はデータを8:2の割合で学習用と検証用に分割して利用しています。
| データ件数 | 正例数 | |
|---|---|---|
| 学習データ | 695,230 | 23,539 |
| 検証データ | 173,808 | 5,735 |
| テストデータ | 734,260 | 22,615 |
まず、学習データとテストデータに対して、log_lossとroc_auc_scoreの2種類の指標で精度比較したのが下の結果です。 結果から、テストデータに対してある程度汎化したモデルが得られていることが分かりました。
| log loss | roc_auc_score | |
|---|---|---|
| 学習データ | 0.0975 | 0.9184 |
| テストデータ | 0.0985 | 0.9008 |
次に、同じ学習済みモデルを使用して、KPI達成の実績とKPI達成確率のキャリブレーションカーブを確認しました。
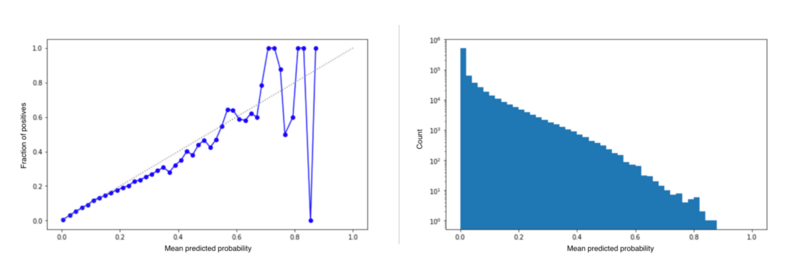
図の左がキャリブレーションカーブ、右がKPI達成確率(0〜1)のヒストグラムを表しています。 結果のキャリブレーションカーブから、実績とKPI達成確率がおおよそ比例しており、実績に沿ったKPI予測ができていることが分かりました(グラフの乱高下は、少数データが原因で発生)。
検証結果は以上です。 今回は1サービスのKPI予測しか試していませんが、KPI予測が有効なKPIが存在することが確認できました。
おわりに
この記事では、KPI達成確率予測という手法を紹介しました。 マイクロアドでは初めての試みではありますが、最近の検証でKPI予測結果がをCVR予測の特徴量として利用すると精度改善することが分かったこともあり、今後はKPI予測の適用範囲を拡充していく予定です。 一方で、問題設定の改善や、KPI予測に適したKPIの選別方法検討など課題も残っていますが、少しづつ改善していければと思っています。 ここまで記事を読んでくださり、ありがとうございました。
機械学習エンジニア絶賛採用中
マイクロアドでは、問題設定からサーベイ、開発・運用まで裁量を持ってチャレンジしたいという仲間を募集しています!また、機械学習エンジニアだけでなく、サーバサイド、フロント、インフラエンジニアなど幅広く募集しています! 気になった方は以下からご応募ください!