はじめに
こんにちは。マイクロアドで機械学習エンジニアをしている新卒の簀河原です。
この記事では、イタリアはバーリ(Bari)で開催されました ACM RecSys'24 の参加レポートと、広告業界のMLエンジニア目線で興味を持った研究発表を紹介します。
ACM RecSysとは
ACM RecSys(The ACM Conference on Recommender Systems)は、推薦システム分野に特化した国際会議です。 2007年にスタートしたRecSysでは、現在の推薦システムの中核をなす技術が数々発表されています。 研究や実務で推薦システムを専門としている方は、RecSysで発表された論文を1度は目にしたことがあるのではないでしょうか。 採択率は例年20%前後と狭き門で、競争力の高い研究結果や技術が毎年発表されているトップカンファレンスの位置付けです。
RecSys の大きな特徴は、推薦システムという研究ドメインの特性上、大学の研究者・学生だけでなく、世界中から多くの実務家が発表者や聴講者として参加している点です。 通常のトラックに加えて「Industry Track」(実務的な課題や解決策に焦点を当てたトラック)が活発で、スポンサーには業界をリードする名だたる企業が入っているのもその特色を表しています。
2024年のRecSysは、10/14-10/18 の5日間に渡ってイタリアのバーリで開催されました。 地理的には、「ブーツに足を入れたら踵の位置にあたるところ」という説明が理解しやすいはずです(?)。 5日間の内、中3日間が本会議、初日と最終日が併設Workshopやチュートリアルが行われる形でした。

本会議は、歴史的な劇場(Petruzzelli Theater)で口頭発表が行われ、Coffee Break の時間に徒歩圏内の別の会場(Chamber of Commerce)でポスター発表が行われました。 いわゆるシングルトラックの形式で、すべての発表を漏らさないように聴講できるよう導線が整備されており、聴講体験としてはとても良かったと感じました。
参加経緯
LBR(Late-Breaking Results)Trackに採択された、私が大学院時代の研究成果を発表するために参加しました。 発表内容は以下の記事で解説していますので、興味があればご覧ください。
今回はマイクロアドを代表した参加ではありませんでしたが、業務ストップの許可をいただき、送り出していただいたチームの皆さんには感謝しかありません!
ぜひ紹介したい研究発表
LLMを用いた推薦システムから古典的な協調フィルタリング手法の再考研究まで、興味深い発表が豊作の年だと感じました。 すべて紹介したいところですが、この技術ブログの趣旨にも合わせて、広告領域の立場で特に面白かったものに絞って紹介します。
Low Rank Field-Weighted Factorization Machines for Low Latency Item Recommendation
Field-Aware な FM (Factorization Machines) は、一般的なFM よりも精度が良いことで知られていますが、フィールド数の増加による推論コスト増の観点でスケールしません。
伝統的には、pruning(刈り込み)=貢献度の低いフィールドをヒューリスティックに除去することで耐え凌いできましたが、精度悪化が問題視されています。
彼らは、FwFM(Field-weighted FM)のフィールドインタラクション行列 を「Diagonal Plus Low-rank Decomposition」と呼ばれる方法で低ランクに近似することで、精度と推論速度のバランスを試みています。
実験により、提案法はpruningを用いたFwFMよりも精度が高く、かつ、推論速度が優れていることが明らかになっています。

言うまでもなく、広告配信では高速な推論が求められています。FMは広告業界で広く使われており、精度を維持しつつ推論を高速化する彼らの取り組みはとても大きな貢献と言えます。
Exploring Coresets for Efficient Training and Consistent Evaluation of Recommender Systems
推薦システムは大規模なユーザのインタラクション履歴で学習される設定がほとんどで、当然、大規模な学習時間や計算リソースを要します。 彼らの研究では、コアセット選択(Coreset Selection)と呼ばれる、膨大なデータセットから代表的なサブセットを抽出するdata-centricな手法を、推薦システムの観点で統一的に比較しています。 Random + 4つの有名なコアセット選択法を用いた結果、YahooR4!データセットにおいては、全体のたった5%のデータで、全体で学習させた場合の80%以上の推薦精度を達成できることを実証しています。 一方で、データセットにより有効なコアセット選択法が異なり、コアセットのデータ構造に対する適応的な選択法の開発が急務だと言及されています。
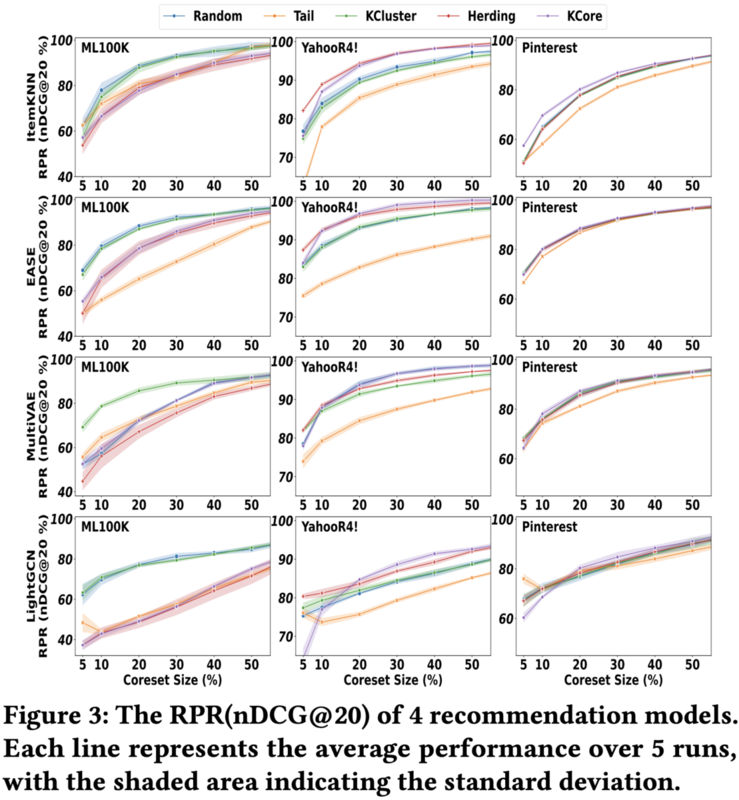
広告データも非常に膨大なため、限られた計算リソースの中で効率的に機械学習モデルを学習することが求められます。マイクロアドのサービスでも、有効なコアセット選択法を深堀ってみたいと思わせる面白い研究でした。
Data Augmentation using Reverse Prompt for Cost-Efficient Cold-Start Recommendation
LLMをレコメンドの推論に使用する立場のものはこれまでにいくつも提案されていますが、推論速度の観点から実用的なものとは言えません。
具体的には、ユーザ毎、候補アイテム毎に「このユーザがこの映画をどれくらい好みますか?」といったプロンプトでLLMから評価値を聞き出す必要があるためです。
この研究では、逆プロンプトと呼ばれる「このユーザが好む映画の特徴は何ですか?」によってLLMから疑似サンプル を収集しています。
そして、疑似サンプル
の学習を正則化項として損失関数に組み込むことでLLMの知識を活用し、推論時はLLMに依存しない、コールドスタートに頑健な推薦システムを実現しています。
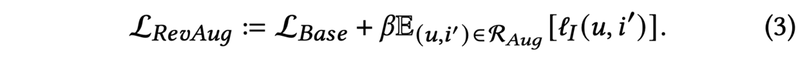
推論速度に関しては、ChatGPTを推論に使った場合と比較して、1000倍の高速化を実現しています。
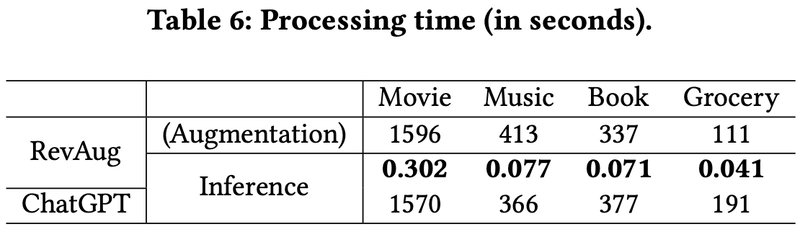
LLMを推論に直接活用するには時間的・金銭的コストがネックとなっており、実務目線では、特に推論速度が求められる広告配信ではLLMは敬遠されがちです。 学習時にコストを払うだけで済む「LLMによるデータ拡張」の方向性は、とても実用的な活用が期待できそうと納得させられました。
機械学習エンジニア絶賛採用中
最後に、マイクロアドでは問題設定からサーベイ、開発・運用まで裁量を持ってチャレンジしたいという機械学習エンジニアを募集しています。
ご興味あれば是非以下の採用ページからご応募ください!