はじめに
こんにちは。マイクロアドで機械学習エンジニアをしている大庭です。
マイクロアドの機械学習チームでは機械学習関連のバッチ実行に Vertex AI Pipelines というGoogle Cloud Platformが提供するマネージドのワークフロー実行サービスを利用しています。
Vertex AI Pipelinesを利用した機械学習プロジェクトはワークフローを管理するためにディレクトリ構成を工夫する必要があるのですが、新しいサービスなため設計関連の情報が少ないと感じています。
そこで今回の記事ではディレクトリ設計の一例としてマイクロアド運用している構成を紹介します。
Vertex AI Pipelinesとは
Vertex AI Pipelinesは前述した通りGCPが提供するワークフロー実行サービスです。
Vertex AI PipelinesではKubeflow Pipelinesのドメイン固有言語で処理の最小単位のコンポーネントを記述し、それを組み合わせることでパイプラインと呼ばれるMLワークフローを定義します。
定義したパイプラインの実行結果は GUI から確認できコンポーネント間の依存関係を視覚的に把握できます。

マイクロアドでは以下の点にメリットを感じ Vertex AI Pipelines をMLワークフローの実行基盤に採用しました。
- Kubeflow をワークフローエンジンとしているためパイプラインの再実行や実行結果のキャッシュが容易
- Kubeflow では本来必要になる Kubernetes クラスタの管理が不要
- BigQueryなどの他のGCPサービスとの連携が容易
ディレクトリ構成
本題のディレクトリ構成です。ディレクトリ構成の全体像は以下になります。
├── components │ ├── comp1 │ │ └── comp1.py │ └── comp2 │ └── comp2.py ├── pipelines │ ├── pipeline1 │ │ ├── pipeline1.py │ │ └── conf1.yaml │ └── pipeline2 │ ├── pipeline2.py │ └── conf2.yaml ├── src │ ├── module1 | | └── file1.py │ ├── comp1_impl.py │ └── comp2_impl.py ├── tests │ ├── module1 | | └── test_file1.py │ ├── test_comp1_impl.py │ └── test_comp2_impl.py ├── cloudbuild.yaml ├── Dockerfile ├── Jenkinsfile └── requirements.txt
このディレクトリ構成は大きく分けて5つのパートに分かれています。
| ディレクトリ | 記述するファイル |
|---|---|
| components | Kubeflow Pipelines SDK でのコンポーネント定義 |
| pipelines | Kubeflow Pipelines SDK でのパイプライン定義 |
| src | Pythonでコンポーネント内のロジックを定義 |
| tests | srcに記述したロジックのテストを記述 |
| ルート直下 | README、CI、Dockerイメージ関連などを記述 |
以下ではこの5つのパートのそれぞれの役割について紹介しながらこの構成を採用している意図や背景について説明します。
components
componentsはKubeflow Pipelines SDKによるコンポーネント定義を記述するディレクトリです。
Kubeflow Pipelines SDK v2 でコンポーネントを定義する方法は大きく分けて以下の2種類あります。
- Pythonで処理を記述する Python Components
- ベースイメージと実行コマンドで処理を記述する Containerized Components
その内比較的利用する頻度が高い Python Components でMLモデルの学習をコンポーネントで定義した場合の実装例が以下になります。
@dsl.component(base_image=f'asia.gcr.io/{PROJECT}/{REPOSITORY}:latest') def train( train_dataset: Input[Dataset], valid_dataset: Input[Dataset], model: Output[Model], metrics: Output[Metrics], ): """学習コンポーネント Args: train_dataset: 学習データ valid_dataset: 検証データ Returns: model: 学習した機械学習モデル metrics: 学習時の評価指標 """ import pickle import polars as pl from train_impl import train_impl # データセットの読み込み train_dataset_ = pl.read_parquet(train_dataset.path) valid_dataset_ = pl.read_parquet(valid_dataset.path) # 学習ロジックの実行 model_, metrics_ = train_impl(train_dataset_, valid_dataset_) # 機械学習モデルの書き込み with open(model.path, 'wb') as f: pickle.dump(model_, f) # 評価指標の記録 metrics.metadata = metrics_
この例のように、componentsディレクトリ内ではKubeflow Pipelines SDKでのアーティファクトの読み込みと書き込みだけを行うようにしています。これにより、Kubeflowに依存した処理とKubeflowに依存しない学習処理のロジックを分離できます。学習処理のロジックは後述のsrcディレクトリに定義しています。
pipelines
pipelinesはKubeflow Pipelines SDKで記述したパイプライン毎の定義を配置するディレクトリです。
pipelines配下はパイプライン毎にディレクトリを分け、その中でパイプライン定義と入力パラメータを設定ファイルで管理しています。複数パイプラインの定義を許容することで、複雑なパイプラインの分割や機械学習モデルのABテストに対応しています。
pipelines
├── pipeline1
│ ├── pipeline1.py
│ └── conf1.yaml
└── pipeline2
├── pipeline2.py
└── conf2.yaml
パイプラインを定義する .py ファイルでは以下のように、componentsディクレトリで記述した各componentsを組み合わせてMLパイプラインを記述します。
@dsl.pipeline(name=f'{REPOSITORY}_training_pipeline') def training_pipeline(): """機械学習モデルの学習パイプライン""" # データの読み込み ... # 前処理 pp_task = preprocess(raw_dataset=ld_task.output) # 学習 tr_task = train( train_dataset=pp_task.outputs['train_dataset'], valid_dataset=pp_task.outputs['valid_dataset'], ) # 評価 ev_task = evaluate( eval_dataset=pp_task.outputs['eval_dataset'], model=tr_task.outputs['model'], ) # 学習結果の保存 ...
src
srcはPythonで処理のロジックを記述するディレクトリです。
src ├── module1 | └── file1.py ├── comp1_impl.py └── comp2_impl.py
src直下にはコンポーネントから呼び出すロジックをコンポーネントと1対1になるよう {呼び出し元コンポーネント名}_impl.py のファイル名で記述しています。
componentsディレクトリで紹介したMLモデルの学習コンポーネントのロジックの実装は以下のようになります。Kubeflow関連の記述をcomponentsディレクトリに分離することで、学習ロジックはデータを入力として受け取り学習したモデルと学習時の評価指標を返すシンプルなものになっています。
def train_impl(train_df: pl.DataFrame, valid_df: pl.DataFrame) -> tuple[Any, dict]: """学習コンポーネントの実装 Args: train_df: 学習データ valid_df: 検証データ Returns: model: 学習した機械学習モデル metrics: 学習時の評価指標 """ # モデルを処理 model = ... # 学習・検証データでの評価指標を計算 metrics = { 'train_loss': ..., 'valid_loss': ..., } return model, metrics
また、ロジック内の処理は極力モジュール化し src ディレクトリ内に子ディレクトリを作成する形で定義するようにしています。これにより、コンポーネント間での処理の共有やPickle形式でのオブジェクトの受け渡しが容易になります。
tests
testsディレクトリはテストコード用をまとめるディレクトリでsrc内のロジックの対してテストを作成します。
Kubeflow Pipelines SDKによる記述をcomponentsに分離したメリットがここにもあり、srcはロジックのみのためKubeflow関連のモックなしでテストできるようになっています。
├── src
│ ├── module1
| | └── file1.py
│ ├── comp1_impl.py
│ └── comp2_impl.py
└── tests
├── module1
| └── test_file1.py
├── test_comp1_impl.py
└── test_comp2_impl.py
マイクロアドの機械学習チームではテストフレームワークとして pytest を利用しています。以下が単体テストの例になるのですが 極力 pytest.mark.parametrize を利用したテーブルテスト形式で記述するようにしています。
class TestModel: @pytest.mark.parametrize(('pred_df', 'want'), [ (pl.DataFrame([[1, 2, 3]]), np.array([1, 1, 1])), (pl.DataFrame([[2, 3, 4]]), np.array([1, 1, 1])), ]) def test_predict(self, pred_df, want): """推論処理の単体テスト""" model = models.Model() got = model.predict(pred_df) assert (got == want).all()
ルート直下
ルート直下にはREADME、CI、Dockerイメージ関連などのファイルを設置しています。
CI
CIはマイクロアドで広く利用し知見のあるJenkinsとGCPの連携が容易なCloud Buildを組み合わせて構築しています。 こちらは試行錯誤中で固まりきってはいないのですが現在は以下のような構成を利用しています。
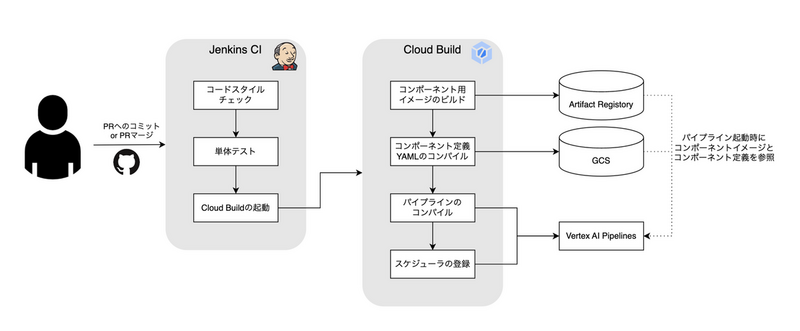
Dockerイメージ
このディレクトリ構成ではsrc内のファイル全てのコンポーネントから参照するため、基本的には以下のようなDockerfileをルートに配置し、プロジェクト毎に1つのイメージを作成するようにしています。
FROM python:3.10.12-slim
WORKDIR /app
COPY requirements.txt /app
RUN pip install -U pip && \
pip install -U setuptools && \
pip install -r requirements.txt
COPY src /app/src
WORKDIR /app/src
パイプライン毎にパッケージのバージョンを分けたい場合など複数のイメージを利用したくなるケースも稀にあるため、その場合は以下のようにdockerディレクトリ内に複数イメージを作成するようにしています。
docker
├── image1
| ├-- Dockerfile
| └── requirements.txt
└── image2
├-- Dockerfile
└── requirements.txt
おわりに
今回の記事ではマイクロアドで実践しているVertex AI Pipelinesを用いたMLバッチの設計について紹介しました。
この記事がVertex AI Pipelinesの導入を検討している方の参考になれば幸いです。