マイクロアドの京都研究所からリモートで働いているインフラ開発ユニットの永富 id:yassan0627 です。
3/1に開催されたOpen Table Format Study GroupのMeetupの第2回目にて、「Kafka ConnectのIceberg Sink Connector」をテーマに話してきました。 今回は、その紹介です。
Open Table Format Study Group(OTFSG) について
Open Table Format Study Groupは、以下を目的とする勉強会です。
Open Table Format Study Group Tokyo (OTFSG Tokyo)はHudi、Iceberg、Delta等データレイクのためのデータフォーマットに関する知見や知識を共有する勉強会です。
勉強会で発表することの出来るテーマはこれらデータフォーマットだけに限らず、その周辺技術(Parquet、Arrowなどより低レイヤーのデータフォーマットや、或いはデータインテグレーションやデータガバナンスなどのデータレイク周辺技術)も含まれます。
本勉強会の目的はオープンテーブルフォーマット周辺技術に関わる技術者や研究者の交流を活性化し、参加者全員の今後の実務に役立てる知見、知識の共有の場を設けることにあります。
また、私も運営に参加しており、OTFをネタに濃ゆい話が出来る楽しい勉強会です。
第1回目の様子は、Youtubeにアーカイブがあるので是非御覧ください。 残念ながら今回の第2回目では諸般の事情でアーカイブ配信はありません(期待していた方には申し訳ないです)。
また、Meetupは講義形式を主体とせず、発表後のQAだけでなく、発表者を含めた参加者とディスカッションの時間を多めに取っています。 今回は特に多めに取ったつもりでしたが各所で議論が尽きず、全然時間が足りない様子でした。そして、その後の懇親会でも色々な話で盛り上がりました。
1回目のMeetupを含め過去の発表のスライドは以下のConnpassに挙がっているので是非ご覧ください。
私の発表について
今回の発表スライドはこちら。
今回のネタは、KafkaのSink先を単純にデータストレージ(HDFSまたはS3)にSinkするのではなく、Icebergテーブルに直接Insert出来る、Kafka Connect1のSink ConnectorのIceberg Sink Connector2の紹介をしました。
調べるきっかけとなったのは、スライドにもあるようにデータ基盤の移行の際にApache Flumeで行っているKafkaからのIngestをどうするかといった検討事項があります。
データストアがHDFS→S3互換のストレージに変更するため、現状のApache Flumeの仕様ではS3にSink出来ない為3、代案としてIceberg Sink Connectorも検討しています。個人的にKafka✕Icebergが気になったので調査してみました。
以下から、当日の発表で時間が足りずに端折ってしまった箇所を補いつつ発表内容について紹介します。 まずは、Iceberg Sink Connectorの前に、ベースとなるKafka Connectとについて紹介した後、Iceberg Sink Connectorについて紹介します。
また、前提として、 Apache Iceberg v1.4.3・Iceberg Sink Connector v0.6.0時点の状態をもとにした話となっています。
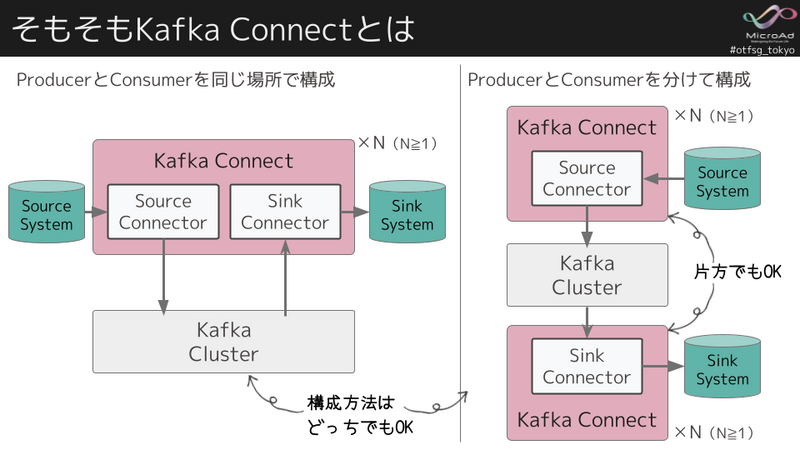
Kafka Connectとは
Kafka Connectとは、Apache Kafkaの一部で、データパイプライン4を実行・管理するラインタイムです。
Kafka Connectは、複雑なデータパイプラインを構築しやすいようにプラグイン形式になっていて、それらをコネクタプラグインと呼ばれます。また、コネクタプラグインには以下の種類があります。
- 外部システムからKafkaにデータをImportする Source Connector
- Kafkaから外部システムにデータをExportする Sink Connector
- Kafka Connectと外部システム間でデータを変換する Converter
- Kafka Connectを流れるデータを変換する Transformation
- 条件付きで変換を適用する Predicate
さらにREST APIが備わっていて設定変更や操作などはRESTを使って行えるので自動化と相性が良いです。
Kafka ConnectはKafka Brokerとは独立して動作します。デプロイ構成については、スタンドアロンアプリケーションとして単一のホスト上に配置することも、分散クラスターを形成するために複数のホスト上に配置することも出来ます。 また、Kafka Connectを実行するホストはWorkerと呼ばれます。
分散モードでデプロイする場合、別途、Zookeeperなどは不要でBroker側に制御用のTopicを作成して、各Workerはその制御Topicを使ってやり取りをします。
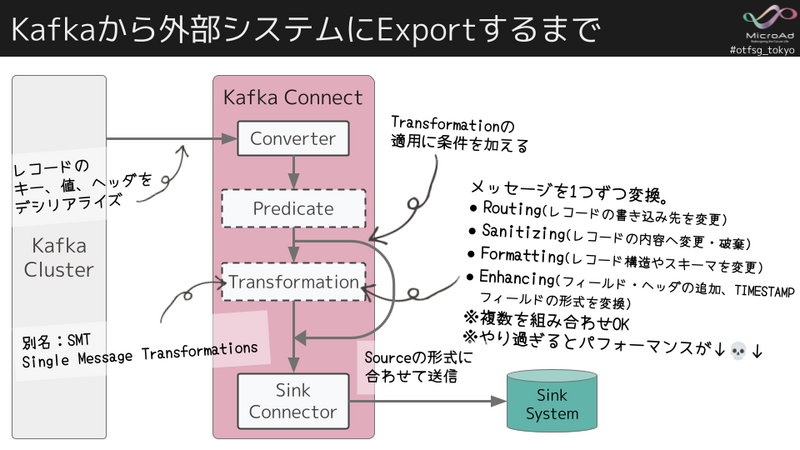
次に、Iceberg Sink Connectorが関連するSink側について簡単にデータパイプラインについて補足します。
Kafkaのメッセージは、単なるKeyと中身がバイトのValueのペアになっています。そのため、まず、Connectorが、Topicからメッセージをkey、value、ヘッダーのレコードとしてデシリアライズします。また、このレコードのスキーマ構造は、KafkaにImportする際、JSON、Avro、Protobufなどのシリアライズ形式を持たせるように指定が必要です。
次にPredicateによってTransformationに渡すか確認し、対象の場合はTransformationに渡します(例えばJSONのネスト構造をフラット化5するなど)。
Transformationでは、メッセージを1つずつ、変換します。色々なパターンがあり、複数の組み合わせが可能です。ただ、やりすぎるとパフォーマンス劣化につながるのでシンプルに留める方が良いです6。
また、PredicateやTransformationはオプションなので必須ではないです。
最後に、Sink Connectorに渡されて、外部システムに合わせてExport、書き込みされます。
Iceberg Sink Connectorとは
では、今回のメインテーマについて触れていきます。
Iceberg Sink Connectorは、名前のまんま、KafkaのTopicをConsumeして、Icebergテーブルに取り込むSink Connectorです。 もともと、Tabularの製品でしたが、現在Apache Icebergに合流しています7 。
また、Iceberg Sink ConnectorのリポジトリにはSink Connector以外に専用のTransformationとして以下の3つが用意されています(但し、Experimental)。
- 特定のフィールドをコピーするCopyValue
- Sink先のCDC機能8で使用するためにAWS DMSフォーマットのメッセージ向けのDmsTransform
- Debezium9フォーマットのメッセージ向けのDebeziumTransformも用意されています10。
Iceberg Sink Connectorとしての主な特徴は以下の通り。
- Icebergテーブルへのコミットを一元化するためのコミット調整
- Exactly-once(正確に1度だけ)にSinkが可能
- 一度に複数のテーブルにSink出来る
- 行の変更(update/delete)、Upsertに対応
- テーブルの自動作成とスキーマの進化
全部紹介するとかなり長くなってしまうので、いちばん大事な1つ目の特徴について紹介します。

上図は Iceberg Sink Connectorのデザインドキュメント11から拝借した概要図です。
Iceberg Sink Connectorでは、各タスクはKafkaから読み込み、Icebergテーブルに書き込みます。しかし、すべてのタスクがテーブルに対してIcebergコミットを実行することは避けたいです。
なぜなら、その場合、Icebergテーブル側に「タスク数」✕「コミット間隔」個のスナップショットが発生することになります。 そして、過剰な数のスナップショットはメタデータファイルの肥大化やパフォーマンスの課題につながります。
また、Icebergカタログへのイベントも過剰に発生します。テーブルへのIcebergコミットを常に並行して実行すると、競合や再試行が発生し、パフォーマンスに影響を与えたり、他のジョブを妨害したりする可能性があります。
その為、複数のWriterからIceberg Writer API を使って直接Icebergへデータファイルを書き込み、カタログにCommitするのはCoordinatorからの1箇所だけとしています。 こうする事で、複数のWriterから並列でデータを書き込みつつ、Icebergテーブルへのコミットを必要最小限に留めることが出来ます。
では複数のWorkerとCoordinatorはどの様に連携しているのでしょうか。次にこれを支える大事なControl topicについて説明します。
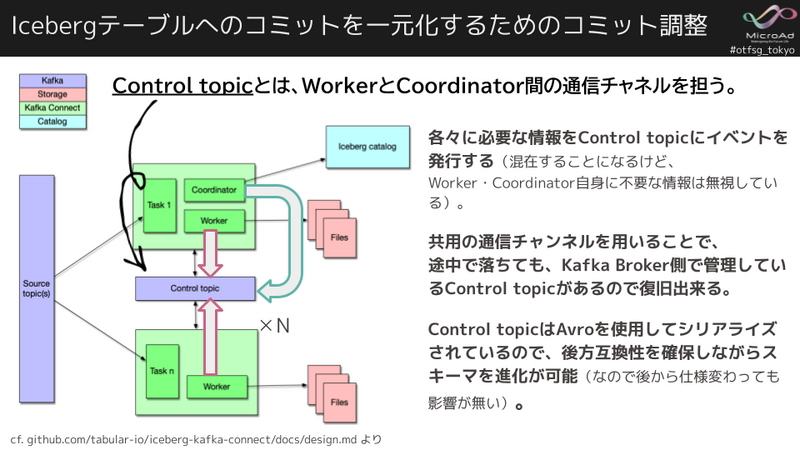
実は、Kafka Broker側にControl topicを作成し、WorkerとCoordinator間の通信チャネルとして利用しています。
Control topicには、WorkerとCoordinatorに必要な情報をイベントとして発行します。イベントが混在することになるがWorker・Coordinator自身に不要な情報は無視して各々で処理されます。
共用の通信チャンネルを用いることで、各々で必要な情報を取捨選択することが出来るので効率的で、また、可用性の向上にも役に立っています。 つまり、Control topicはKafka Broker側で管理しているので、Workerが途中で落ちても、Control topicを使って復旧が出来ます。
また、Control topicはAvroを使用してシリアライズされているので、後方互換性を確保しながらメッセージのスキーマ進化が可能です(なので後から仕様変わっても影響が無い)。
次に当日の発表で時間の都合で省略した「Iceberg Sink Connectorのコミットプロセス」について説明します。
下図は、Source topicからConsumeしたメッセージがどの様にしてIcebergテーブルにデータを追加しコミットされるのかを大まかにシーケンス図にしました12 。
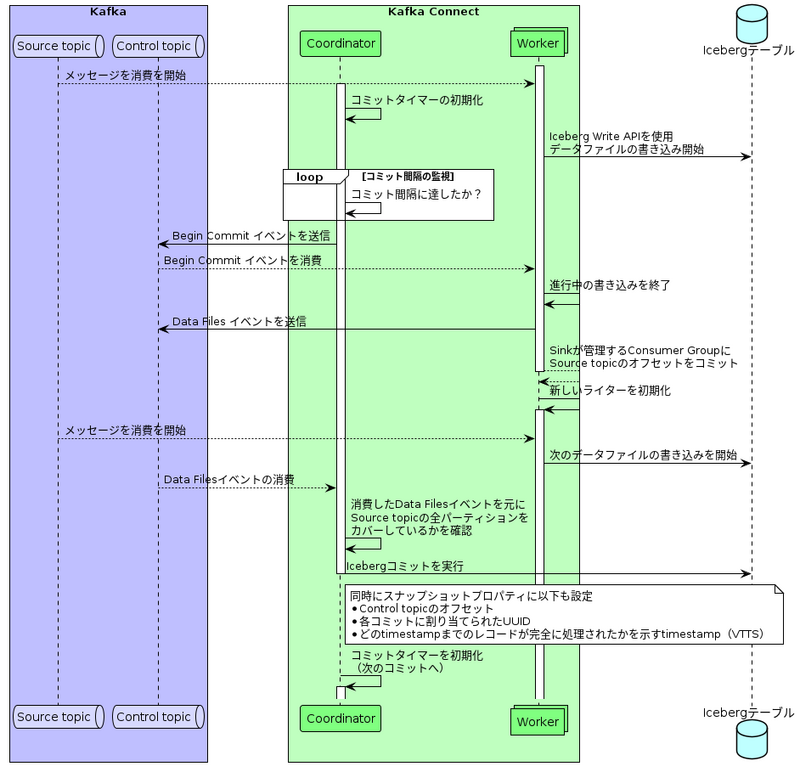
大事なポイントは、Icebergテーブルへのコミットと、Icebergテーブルのデータファイルの書き込みが別々で実行されている点と、CoordinatorとWorkerがKafka Topicを使って通信して解決しているという点です。 この特徴は、Kafka ConnectとIcebergテーブルの特徴をうまく活用していてとても面白いです。
また、この辺りの動きはConfluentのKafka Connectに関する以下のドキュメントも参考にするとより理解が深まると考えます。
以上が、「Icebergテーブルへのコミットを一元化するためのコミット調整」の説明でした。 その他の特徴について、説明するとかなり長くなってしまうので、後はスライドを参照ください。
お試し環境について
実際に動かしてみて挙動を確認すると分かりやすいです。
Docker Composeを用いてKafkaに流すデータ生成からIcebergテーブルの用意まで一連の流れをお試し出来る環境が以下の通りあるので、そちらを使って是非お試ししてみてください。
Kafkaの環境にRedpanda13を使っているのでUIが付いていて操作が非常に便利です。また、実際の操作もJupyter Notebookを使ってWebブラウザから実行可能です。 さらに、この手の検証で一番めんどくさいテストデータの作成は、Benthosを使って自動生成出来るのでとても楽です。 スライド中にはもっとフレキシブルにFakeデータを使って生成する方法も紹介してるので良かったら利用ください。
私以外の発表について
私以外にも、ktksqさんの 「Delta Lake: Liquid Clusteringについて理解する」や、べりんぐさんの「Apache Iceberg Catalog選択のポイント」といった発表がありました。
べりんぐさんはApache Icebergの記事14 がとても素晴らしいので、Xで発表をお願いして実現できました🙌
発表スライドはこちら。
当日の発表はIcebergのCatalogについて紹介し、どれ使ったら良いか迷っている人には参考になったのではないでしょうか。個人的にはREST Catalogの重要性は納得でMuti-Table Transactionの機能は早く完成して欲しいところ。また、スライドにあった実験環境も良いのですが、べりんぐさんのハンズオン環境もオススメです😍
次に、同じ運営メンバのktksさんのDelta LakeのLiquid Clusteringの紹介も面白かったです。普段はDelta Lakeを使っていないもののLiquid Clusteringの機能自体は気になっていたので参考になりました。 発表スライドはこちら。
最後に
言語化してみると自分の解像度の低さが確認出来て、今回の発表の準備で大分理解が深まりました。
また、Meetupの参加者から「この界隈のオフラインイベントが全く無かったので、今日はとても楽しかった」と喜んでもらえたので開催してとても良かったです。運営として今後も続けていきます。ひとまず3回目はやります!
そして、機会があれば、引き続きIceberg Sink Connectorについて取り上げます! それではまたMeetupで。
-
Apache Kafka公式のKafka Connectのドキュメント もありますが、Confluentのドキュメントも参考になります。
docs.confluent.io↩ -
現時点ではTabularのリポジトリにあるドキュメントが参考になります。
github.com↩ -
解決策としてはHadoop-AWSモジュール を使って、 S3 over HDFS として対応することも出来るが色々課題はあります。これはまたどこかで機会があれば。
また、HDFS直接Sinkする対応チケット自体はあるけど、進んでいない様子。
[FLUME-951] Implement a direct S3 Sink for Flume - ASF JIRA↩ - https://www.confluent.io/ja-jp/learn/data-pipelines/↩
- docs.confluent.io↩
-
込み入った処理をしたい場合は、Kafka Streamの出番だそうです。
docs.confluent.io↩ - github.com↩
- CDCとはChange Data Captureの事。例えば、RDBMSの行レベルの変更をKafkaを通じて別のシステムにSinkする機能の事。↩
-
KakaとKafka Connectorをベースにして必要なConnectorを同梱しCDCを提供しやすいよう環境を提供する製品です。
debezium.io↩ -
気になる方はこちら。
iceberg-kafka-connect/kafka-connect-transforms at main · tabular-io/iceberg-kafka-connect · GitHub↩ - iceberg-kafka-connect/docs/design.md at main · tabular-io/iceberg-kafka-connect · GitHub↩
- デザインドキュメント をベースに作成したのでSourceまでは追えていないので認識違いしているかもしれないです。気になる点があれば、 X( @yassan168 )で教えて下さい🙏↩
-
JavaではなくC++実装のKafka互換のデータストリーミングプラットホーム
redpanda.com↩ -
べりんぐさんの記事
bering.hatenadiary.com
bering.hatenadiary.com↩