マイクロアドでサーバサイドエンジニアをしているタカギです。
今回はデータ基盤移行とPySparkについての話になります。
目次
データ基盤移行の概要
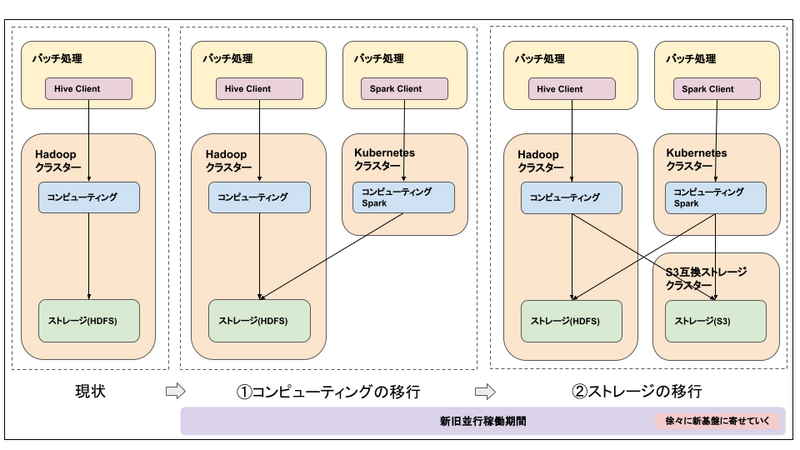
諸々の事情1により、データ基盤をHadoopから移行することになりました。
現在のデータ基盤でのETL/ELT処理はHadoopエコシステム(Hive、HDFSなど)を中心に構成されています。
※Hadoopについてはこちらの記事が参考になります。
これらをKubernetes、PySpark、S3互換ストレージ(詳細未確定)を組み合わせたデータ基盤へ移行する計画です。
すぐにすべてを移行するのは難しく、完全移行までは新旧並行稼働がそれなりの期間続く予定です。
今回の記事では、PySparkを使用したバッチ処理の部分に少しだけ触れていきます。
※その他にもさまざまなコンポーネントで新たなツールやアーキテクチャを導入していく予定ですが、そちらは割愛させていただきます。
データ基盤移行後のバッチ処理
データ基盤移行後はKubernetes上でPySparkを実行することで集計処理を行う予定です。
PySparkを実行するにあたって、Spark3.4で導入されたSpark Connect2を導入する方針で検証を進めています。
Spark Connectを使用することで、Spark3.3までとは異なる形でPySparkを実行できるようになりました。
Spark Connectを導入する
当初(Spark3.3を使用する前提での計画中)は、Kubernetes上でSpark用のカスタムリソース、カスタムオペレーターを使用してPySparkを実行する想定でした。3
事前準備として、PySpark用スクリプトを特定の場所に配置するか、Kubernetes上で起動するDockerイメージの中に含めるなどする必要があります。
マイクロアドではワークフローエンジンとしてDigdagを採用しており、DigdagでPySparkを使用したバッチ処理は以下のような流れとなります。
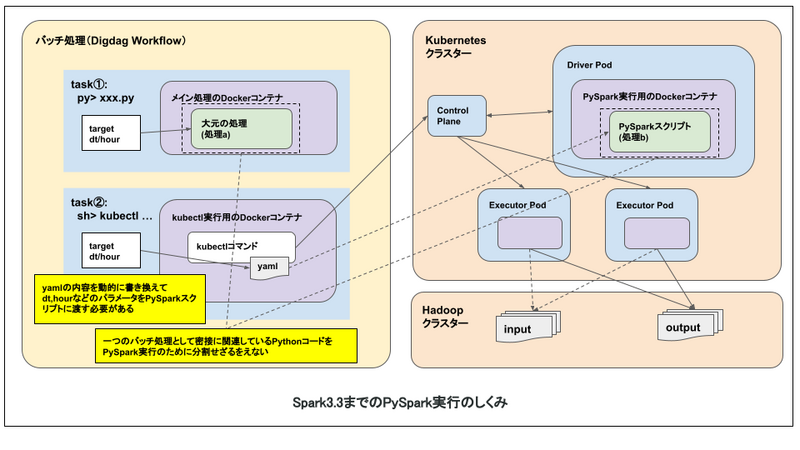
この方法だと、以下のような、(クリティカルではないとはいえ)若干悩ましい問題がありました。
- バッチごとにPySpark用スクリプトのパスを記載したKubernetesマニフェストファイルを用意する必要がある
- Pythonコードが大元の処理(処理a)とPySpark用スクリプト(処理b)に分割される(分割したくないケースもある)
- PySpark用スクリプトにパラメータが必要な場合、マニフェストファイル経由で渡す必要がある
- 集計処理は時間単位で行うことが多く、上記の例では dt(日付), hour(時間) をパラメータとして渡しています
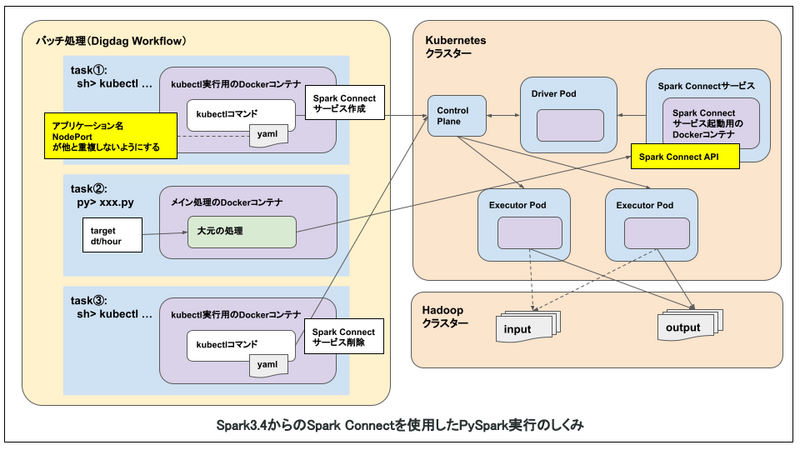
一方で、Spark Connectは、SparkをAPIサーバのように扱うことができる仕組みとなっており、大元のPythonコードから直接PySparkを実行できます。
from datetime import datetime from pyspark.sql import SparkSession def main() -> None: """ 大元の処理 """ # 処理対象日時 dt = "20230410" hour = "12" execute_pyspark(dt, hour) def execute_pyspark(dt: str, hour: str) -> None: """ pysparkの処理 """ spark_connect_url = "sc://test-k8s:31502" input_path = f"hdfs://test-cdh:8020/test_path/in_log/dt={dt}/hour={hour}" output_path = f"hdfs://test-cdh:8020/test_path/out_log/dt={dt}/hour={hour}" # SparkSession spark = SparkSession.builder.remote(spark_connect_url).getOrCreate() # ストレージからの読み込み df = spark.read.parquet(input_path) # 集計処理 # df = df.xxx(xxx) # ストレージへの書き込み df.write.mode('overwrite').parquet(output_path) spark.stop()
Spark Connectを導入することで、悩ましい問題をいくつか解消できそうです。
一方で、良いことづくめではなく、問題点もありそうでした。
Spark Connectの問題点
複数のバッチ処理からのリクエストが同時に発生した場合、Spark Connectサーバの負荷が上昇し、すべてのバッチ処理が影響を受けます。
※リクエストするたびにspark-submitされるわけではなく、常時稼動しているSpark ConnectサーバのDriverを使いまわしてExecutorが生成されるようなイメージです。
Driverが落ちてしまった場合も、すべてのバッチ処理が影響を受けることになります。
この問題を避けるため、バッチ処理のたびにSpark Connectサーバを作成/削除する方針にしました。
- 一連のバッチ処理の流れ
- Spark Connectサーバ作成
- PySpark実行
- Spark Connectサーバ削除
Spark Connectサーバを作成/削除するステップが毎回発生することになるわけですが、以下のような制約がありそうです。
- アプリケーション名をユニークにする必要がある
- NodePortが重複しないように制御する必要がある(Spark ConnectはNodePortサービス経由でアクセスする前提)
しかしながら、それでもメリットのほうが大きいと判断し、Spark Connectを導入する方向で進めることにしました。
まとめ
データ基盤移行の概要と、PySparkの検証について書きました。
Spark Connectは非常に便利な機能だと感じています。この記事が参考になれば幸いです。
また、PySparkに限らずですが、現在もデータ基盤移行の検証は進んでいます。
PySpark検証の記事第2弾もご期待ください。
補足
Spark ConnectではすべてのAPIがサポートされるわけではなく、利用可能なAPIは限られているようです。
すでにSparkを利用している状況でSpark Connectを導入する場合は注意が必要ですね。
Apache Spark 3.4でサポートされるAPI PySpark: Spark 3.4では、Spark ConnectはDataFrame, Functions, Columnを含むほとんどのPySpark APIをサポートしています。 サポートされているPySpark APIは、API referenceドキュメントで「Supports Spark Connect」と表示されるので、既存のコードをSpark Connectに移行する前に、使用しているAPIが利用可能かどうかを確認できます。 https://www.databricks.com/jp/blog/2023/04/18/spark-connect-available-apache-spark.html