はじめに
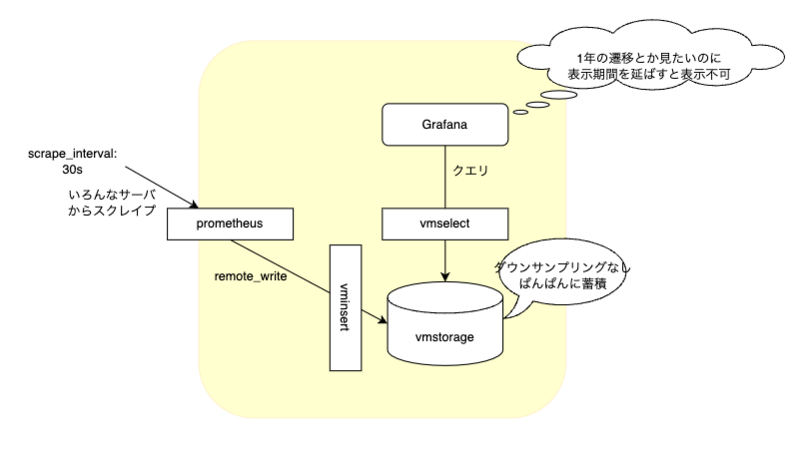
インフラエンジニアのN村です。 マイクロアドではPrometheusとオープンソース版VictoriaMetricsを使って、データセンターにあるサーバ約1000台強をモニタしています。 利用開始からそろそろ4年。そこそこ安定稼働しています。
ですが、いま課題を抱えています。おそらくVicky1にありがちな話です。
目次
長期間グラフが表示できない
運用をはじめて2、3年たった頃から、Grafanaダッシュボードの表示期間を半年以上に設定すると、エラーになるケースが増えてきました。2 仕方ないので期間を分割して表示させたりしています。
導入当初、各サーバのメトリクスを1年以上遡った遷移を見たくなるかも、という声があったので、vmstorageでのデータ保持期限は1.5年分としています。が、せっかくこれだけ蓄積しているのにダッシュボードでまとめて気軽に表示できないのでは宝の持ち腐れです。
というわけで、なんとか長期間グラフを表示できないものか試行錯誤した事を書きます。
ダウンサンプル機能がない
VictoriaMetricsにはダウンサンプル機能が実装されていません。正確にはオープンソース版のVictoriaMetricsには、ですが。
ダウンサンプルされないvmstorage には、スクレイプ間隔(マイクロアドでは30秒ごと)のままの間隔でサンプルがギッチリ詰まっています。そこから数ヶ月という長期スパン分の大量のメトリクスを、ダッシュボードによっては全サーバ分集計しながら検索するのは大層な負荷になることは容易に想像できますね。
VictoriaMetrics導入時、ダウンサンプル機能がないことは認識していたのですが、そのうち対応するだろうという淡い期待をもっていました。グラフ表示の不調よりもデータ容量の方を気にしており、VictoriaMetricsは圧縮率が高いので当面問題は出ないだろうと高をくくっていました。
そしてついにv1.71.0で実装!なんとEnterpriseEdition3のみでの実装でした。 Cactiではダウンサンプルがデフォルトで実装されておりほとんど意識することなく長期期間のグラフ表示できるので、ここはオープンソース版のVictoriaMetricsの残念な点です。
方法はないのか
とはいえ、やり方はあるはず。蓄積済みのサンプルを有効活用するため方法を探りました。
1.スクレイプ頻度を落として集計サンプル数を減らす
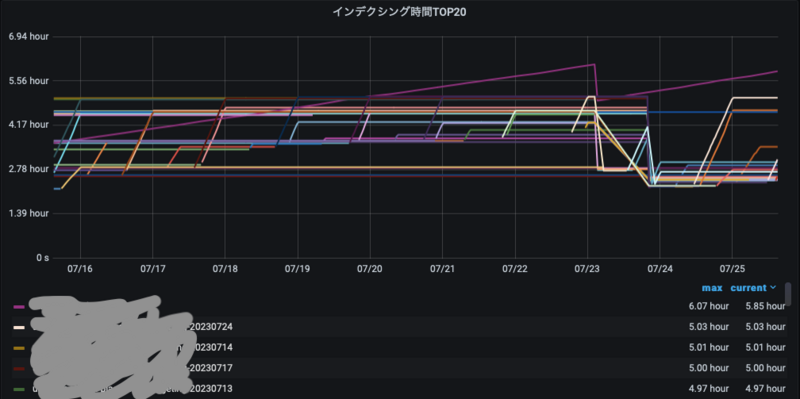
ElasticSearchのインデックス毎のモニターを始める際に検討しました。何千とあるインデックスのサイズやインデクシング時間を30秒ごとにスクレイプしそれを集計するのは酷です。要件として即時性が求められなかったので、10分ごとのスクレイプとする事にしました。また、グラフの表示負荷を下げるため、topk()した上位20のみの表示に限定しました。
2.さらにレコーディングルールも使う
さらに topk()した結果をPrometheusの recording rule で記録しました。VictoriaMetricsに追加格納するサンプルをなるべく少なく抑えるべく、レコーディングルール評価は10分間隔としました。Grafana表示のタイミングでElasticSearchの全インデックスのサンプルに対する集計処理が走らないので、Grafana表示は早くなりました。
このダッシュボードは一年分くらいは表示可能なものになりました。
3.GrafanaでQueryOptionを調整して荒く検索する
時間の経過とともに、上記のダッシュボードの表示可能期間が短くなって来ました。
Grafanaからクエリ発行する際にクエリ結果を荒目に取得するように設定すればいいのでは?と考えGrafanaでQueryOptionを調整。Grafanaが自動で調整してくれているところを固定値に調整しました。
荒目に検索するなら長期ダッシュボード表示用vmselectを別途作成し、そのオプションで調整する手もあります。 重複メトリクスとして認識する時間 dedup.minScrapeInterval4を10分など大きく設定します。この時間よりも短い間隔のサンプルは重複として無視されるので、10分おきのサンプルが利用されることになります。
ここまで結構がんばったのですが、結局はパンパンのvmstorageを検索しに行く訳で、一度はうまく調整できても一時しのぎにしかなりませんでした。もはや長期表示用のストレージを用意するしかなさそうです。
4.ダウンサンプル機能があるストレージに変える?
お手軽にはInfluxDBでしょうか。クラスタ機能を求めると有償になるので要検討です。 VictoriaMetrics導入検討した際、どちらにするか迷ったThanosはどうか。あの頃はLocal Filesystemがベータ版というのと、コンポーネントが多いというので見送ったのでした。現在もストレージ部分5とコンポーネントの運用にハードルはありますが、無償版にもかかわらずクラスタ機能とダウンサンプル機能を持ち合わせている点はやはり魅力的です。
これは近い将来の乗り換え一番候補です。ですが、仕組みがだいぶ変わるので運用にのせるまで時間と手間がかかります。蓄積済みのサンプルの移行が可能かどうかも調べないといけません。すぐには移行できないです。
5.back to basic
なんとなくオライリーの入門Prometheus本6を眺めていたときの事。 ちょっと待てよ、Prometheusにfederateという機能があったではないか!そもそもは複数のPrometheusのスクレイプ済みサンプルを統合するための機能のはず。対象のメトリクスをフィルタする事に加え、feratateの頻度も30秒とか10分などと粗さを調整できます。
長期表示用VictoriaMetricsを用意して、長期表示が求められるメトリクスのみ荒目のインターバルで大元のVictoriaMetricsから新VictoriaMetricsにfederateすればよいのでは。 こんなイメージです。
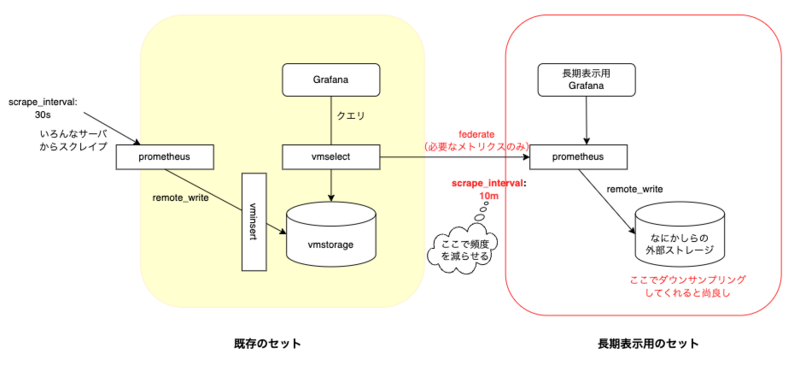
federateはvmagentでも可能なので、Prometheusのかわりにそちらを使っても良さそうですね。
新規にスクレイプされるサンプル分はこれで良さそうです。では過去の蓄積済みサンプルはどうするか。
6.蓄積されたサンプルの移行は?
VictoriaMetricsのデータ移行ツール vmctl7はメトリクス名と期間絞って移植できるのですが、粗さは指定できません。 一方、vmalert8には、過去に蓄積済みのサンプルをrecording rule 評価して記録しremote_writeする機能があります。サンプルの粗さはrecording rule定義の中で指定できます。 コマンド的には下記のように簡単です。
./vmalert -rule=recordingrule.yml \ -datasource.url=http://OLD-VMSELECT \ -remoteWrite.url=http://NEW-VMINSERT \ -replay.timeFrom=2022-12-01T00:00:00Z \ -replay.timeTo=2023-02-01T23:59:59Z
従来のダッシュボードでrecording ruleを使っていない場合は、長期表示用のダッシュボードでrecording rule利用の形に変更する必要はあります。ですがこれで蓄積済みサンプルも有効活用できそうです。
おわりに
中期的な対策として、長期表示用のVictoriaMetricsを準備する方針になりそうです。federateの段階で対象を最低限に絞る事で蓄積データを抑える9つもりです。 が、ここでも時間経過とともに同じ問題が発生することは否めません。 ダウンサンプル機能はやはり必要なので、長期的な対応としてThanosなどの他ストレージの調査検証を進める予定です。(本音はオープンソース版VictoriaMetricsへのダウンサンプル実装を強く希望していますが。VictoriaMetrics社の方針変更に期待しつつ!)
おまけ
本記事を書くのにissueを漁っていたところ、同様の内容をすでにVictoriaMetrics社員の方が記載していましたね。ただしvmalertへのrecording rule追加以前だったようです。
- VictoriaMetricsの愛称です。↩
- vmstorageやvmselectの各パラメタ上限を超えたりタイムアウトするなど。↩
- 機能提供のみのサポートなしプランの見積もりを頂きましたが、弊社ではちょっと難しいお値段でした。↩
- https://docs.victoriametrics.com/Cluster-VictoriaMetrics.html#list-of-command-line-flags-for-vmselect↩
- 現在Local Filesystem はStableですがTesting and Demo onlyです。S3互換のストレージが候補になりそうです。↩
- https://www.oreilly.co.jp/books/9784873118772/↩
- https://docs.victoriametrics.com/vmctl.html↩
- https://docs.victoriametrics.com/vmalert.html↩
- 既存のスクレイプ間隔が30秒で、federate間隔を5分にしたとすると、それだけで10分の1になりますね。↩