はじめに
マイクロアドのシステム開発部でインフラエンジニアをしているキガワです。現在マイクロアドではデータプラットフォーム事業を支える大規模な基盤(以下データ基盤)を移行計画中です。 現在のデータ基盤はHadoopエコシステムで実現されており、次期データ基盤ではコンピューティングとストレージを分離する構成を検討中です。
コンピューティング部分についてはマイクロアドで書かれた以前のブログ記事があるので、興味がある方はそちらをご覧ください。 ストレージ部分についてはS3互換のストレージ製品を検討しており、今回はその中で検証したApache Ozoneについて概要をご紹介します。
Apache Ozoneとは
Apache OzoneとはHadoop用のスケーラブルで冗長性のある分散オブジェクトストアです。S3プロトコルをサポートしているため、Hadoop以外のシステムでも利用可能です。
※AWS CLIのオプションでエンドポイント URLを指定することでAWS CLIでも利用可能。
HadoopのHDFSではオブジェクトのメタデータ(名前空間、ブロックマップ)を持つNameNodeにはスケールアップ以外のスケール方法がありませんでした。そのためメモリサイズの限界により生じる、スモールファイル問題やオブジェクト数の上限等の問題がありました。 Ozoneでは名前空間の管理(後述するOzone Manager)とブロックマップの管理(後述するStorage Container Manager)に役割を分離することで、上記問題を根本的に解決しています。 またそれぞれの役割毎にスケールアウトも可能となっており、スケーラビリティの問題も同時に解決しています。
Ozoneの主要コンポーネントについて
Ozoneでは以下3つの主要コンポーネントで構成されます。
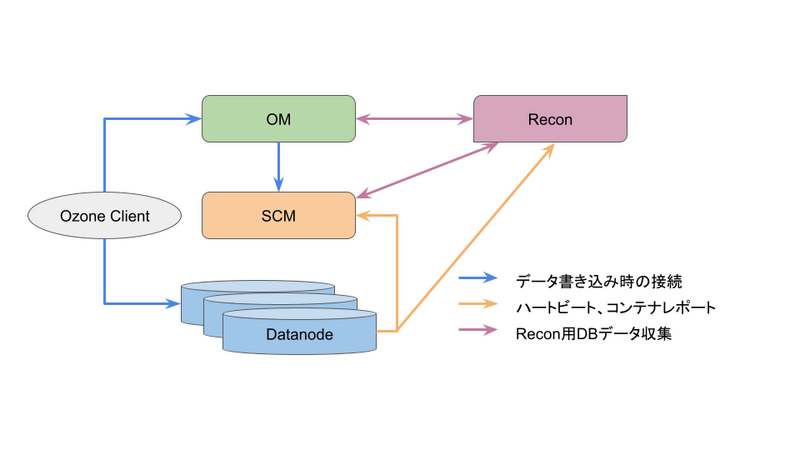
OMはクライアント(図中Ozone ClientはCLI想定)がデータ読み書きをする際の最初の問い合わせ先です。クライアントはOMに問い合わせることで、書き込み先のブロック情報や読み取るブロックリストを取得します。その後取得したブロック情報を元に、クライアントは直接Datanodeに対してキーを読み書きします。 OM自体はブロックを割り当てず、SCMにリクエストすることでSCMがDatanodeのブロックの割り当てを実施しています。
SCMはクライアントからは直接アクセスされず、Datanodeから定期的にハートビートやコンテナの状況といった情報を受け取ります。また、SCMは受け取った情報を元にブロックの割り当てやデータ(Container)のレプリケーション管理をします。そして、実際にOzoneクラスタを構築する際は一番最初にSCMの構築が必要です。
DatanodeはOzoneのデータ格納先です。SCMによって管理されており、SCMへ定期的にハートビートやノードのステータス、コンテナレポートなどを報告します。また後述するReconにも同じ情報を定期的に送付します。
OMとSCMについてはRAFTによるHA構成にできます。ただ注意事項としてSCMのHA構成ではPrimordial Nodeと呼ばれるノードが1台存在し、当該ノードが停止している間はOzoneに新規ノード追加などができない状態になるため注意が必要です。
またこれらコンポーネントの他に、Ozone全体の状態を把握できるモニタリング用としてReconが存在します。
Reconには各コンポーネントを管理する機能はありませんが、DatanodeやPipeline、Containerの状態やOzone全体のデータ使用量などを確認できます。
データのレプリケーション
Containerについて
Ozoneでは読み書きするファイルをブロックという単位で分割して管理します。また実際に読み書きする際はチャンクと呼ばれるさらに小さいサイズ(デフォルトで最大4MB)に分割してデータを受け渡します。 従来のHDFSではブロック単位でレプリケーションされていたため、多くのブロックレポートが発生していました。 OzoneではブロックをContainerという単位(デフォルトで5GB単位)でまとめ、Container単位でレプリケーションしています。
ContainerにはOpenとClosedの状態が存在し、それぞれ大きな違いとして以下があります。
- Open
- Read/Write共に可能。
- レプリケーションの整合性はRaftを用い、Apache Ratisによって実装されています。
- RAFTアルゴリズムによってリーダー選出し、リーダーがコンテナのレプリケーション状態を同期的に管理。
- Closed
- Read Only。
- コンテナ内の変更がなくなるため、レプリケーションは非同期で行われる。
Pipelineについて
DatanodeのレプリケーショングループとしてPipelineという概念が存在します。SCMによって管理され、ファイルを読み書きする際にPipelineの情報を元に、割り当てるコンテナ/ブロックを払い出します。 Pipeline毎にRAFTによるリーダーの選出が行われ、レプリケーション状態が管理されています。
以下ReconのPipelinesの画面を見ていただくとイメージしやすいです。
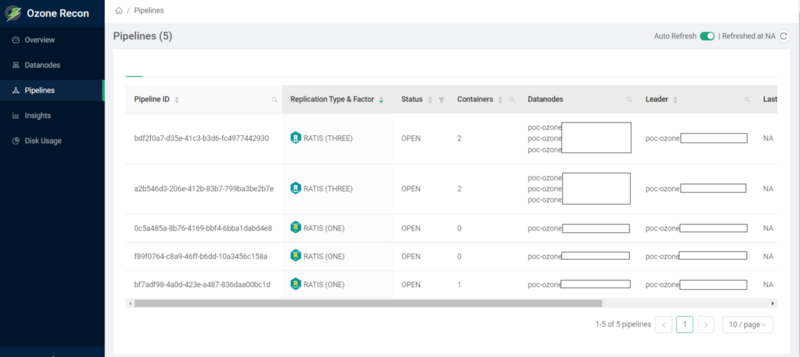
ちなみに以前Datanodeは1つのPipelineにしか所属できなかったようですが、Multi RAFTによって複数のPipelineへ所属できるようになり、パフォーマンスの向上などが図られたようです。
※Cloudera社のブログでも取り上げられております。
レプリケーションタイプについて
HDFSのレプリカの様にデータを3ノードで保管するRATIS/THREEでは、データサイズに対して3倍のストレージサイズが必要でした。
OzoneではRATIS/THREEに加え、Erasure Codingも対応しています。
推奨設定のRS-6-3-1024kでは6ノードがデータブロック、3ノードがパリティブロックとして使用されます。
そのため必要なストレージサイズはデータサイズの1.5倍で済み、3ノードの同時障害へ耐えられるようになります。
Erasure Codingにも2パターン存在し、コンテナレベルとブロックレベルでErasure Codingにするものがあります。 今回の検証時点ではそれぞれどういう挙動をするのかまで細かく検証はできておらず、興味のある方はOzoneに関するJIRA内の議論やドキュメントが参考になります。
おわりに
今回はS3互換ストレージのApache Ozoneについて紹介しました。 Apache Ozoneについてはまだ理解しきれていないところもありますが時間の都合上、現在マイクロアドではまた別のストレージを検証中です。 そちらについてもいずれブログで記載できたらと考えています。
Qiita Advent Calendar 2023参加
今年もQiitaのAdvent Calendarイベントに参加します!例年通り25記事埋める予定ですので、是非、購読ください! 2017年以降参加していますので、興味のある方は過去のアドカレもご覧ください!
新卒インフラエンジニア絶賛採用中
マイクロアドでは技術への探究心があり、最新の技術・動向について積極的に学び活かす意欲を持った仲間を募集しています!またインフラエンジニアだけでなく、サーバサイド、機械学習エンジニアなど幅広く募集しています! 気になった方は以下からご応募ください!