はじめに
初めまして。マイクロアド24年新卒インフラエンジニアの大泉です。
今回は新卒研修で教わったマイクロアドが利用している監視ツールや監視の仕組みについてお話していきます!
マイクロアドではオンプレミスで重要なサーバが稼働しており、監視がとても重要な役割を担っています。
インフラエンジニアがいち早くシステムの異常に気付き、対応するために「監視」は欠かせません!
監視の種類
マイクロアドで重要な役割を担う監視ですが、監視は大きく分けて外形監視と内部監視の2種類があります。
外形監視
外形監視は、ネットワークの外側からアクセスし、接続状況を監視することを指します。
目的
- システムの外側(ネットワークの外側)から応答性やアクセスの可否を確認することで、実際のユーザと同じ視点でシステムを監視すること
監視方法とツール
- Datadog
- Uptime monitors
- Ping
- 外部からのヘルスチェックAPI
内部監視
内部監視は、ネットワークの内側からアクセスを行い、システムを監視することを指します。
目的
- システム内部のリソース状態やパフォーマンスを深く理解する
監視方法とその関連ツール
モニタリング:リアルタイムでのパフォーマンスデータやメトリクスの収集・可視化
- ツール例:Prometheus、Grafana
ロギング:システムの動作やエラーの詳細な記録
- ツール例:Grafana Loki、Elasticsearch、Logstash、Kibana (ELK stack)、Fluentd
- マイクロアドでのロギング・監視については以下の記事をご参照ください。
アラーティング
上記の外形監視・内部監視で異常を検知した場合にアラーティングを行います。
目的
- 監視によって異常を検知した場合に通知し、迅速な対応を可能にする
ツール
- Alertmanager (Prometheusのアラート管理コンポーネント)
- PagerDuty
マイクロアドで使用している監視ツール
マイクロアドでは、大きく分けて4つの監視ツール(Nagios・Prometheus・Datadog・Cacti)を使用しています。 それぞれの監視ツールに対し、マイクロアドでの立ち位置は以下の図になります。
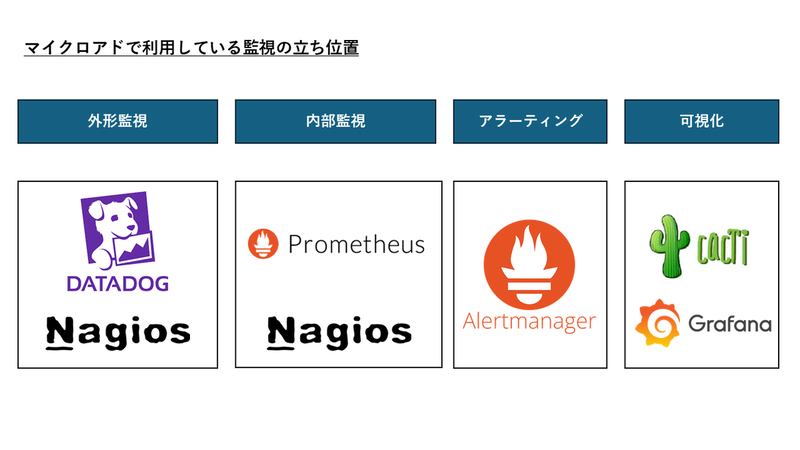
アラーティングについて、長年使い続けているNagiosと、この後に説明するPrometheusのAlertmanagerを併用しています。
理由としては、PrometheusのAlertmanagerに完全移行するための工数が確保できていないため、現状の併用が続いています。
将来的には、PrometheusのAlertmanagerへの移行を進めていく予定ですが、Nagiosの安定性を維持しつつ、段階的に進める方針です。
それでは、それぞれの監視ツールについて、マイクロアドではどのように使われているかを踏まえて説明していきます。
Nagios
1つ目がNagiosです。
Nagiosとは、オープンソースのネットワーク監視ツールです。 NagiosQLというWebUIツールを使用して、Nagiosの設定管理をしています。
マイクロアドでは、外形監視と内部監視の両方で使用しています。
アラート発報までは、以下の通りです。
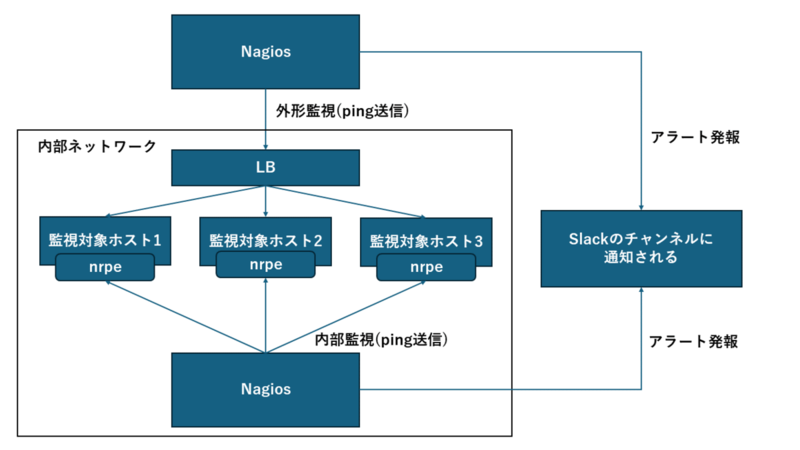
外形監視の場合
監視対象ホストにpingを送信し、応答に問題があればアラートを発報します。
内部監視の場合
マイクロアドの内部監視は2パターンあります。
1パターン目は、内部リソース監視のためにNRPE(Nagios Remote Plugin Executor)を各ホストで使う監視です。
- 監視対象ホストに
nrpeというエージェントをインストールする - Nagiosに監視対象ホスト、サービスを追加
- Nagiosが監視コマンドをキック
- 監視対象ホスト内
nrpeがホスト内でNagiosプラグインのコマンドを実行し、Nagiosに応答を返す - Nagiosで監視対象からの応答に問題があるかを判断してアラートを発報する
2パターン目は、ping監視やポート監視などnrpeを使わない監視です。
- Nagiosに監視対象ホスト、サービスを追加
- Nagiosが監視コマンドをキック
- Nagios内でNagiosプラグインのコマンドを実行して監視対象に接続
- Nagiosで監視対象からの応答に問題があるかを判断してアラートを発報する
Prometheus
2つ目がPrometheusです。
Prometheusとは、オープンソースのシステム監視およびアラートツールキットです。
マイクロアドでは、内部監視で使用しています。
監視対象のサーバに、exporterと呼ばれる物理マシン内の様々なメトリクスを開示するプログラム(例:node_exporter, cadvisorなど)をインストールしておく必要があります。 1
アラート発報までの流れは、以下の通りです。
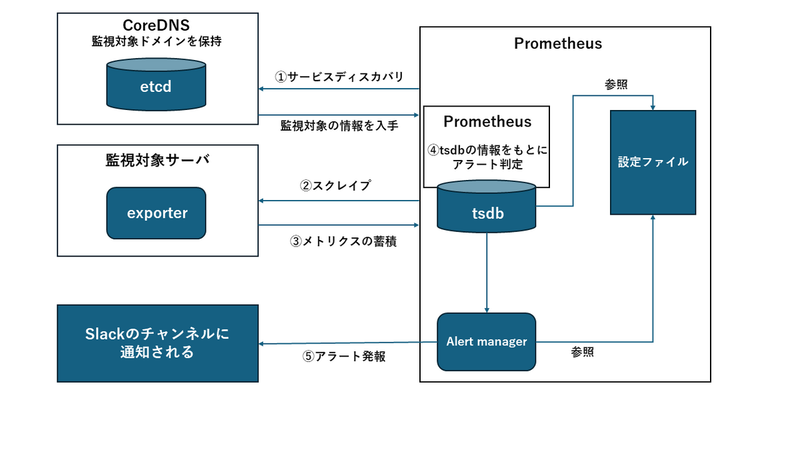
- サービスディスカバリを行うことで、監視対象サーバの情報を入手する
- 監視対象サーバのexporterに対してスクレイプを行う
- 監視対象サーバのメトリクスをPrometheusがアラートルールをもとにアラートを判定する
- Alertmanagerにより、アラートを発報する
監視対象サーバのメトリクスはPrometheus内のtsdb2に蓄積されます。
データの可視化にはGrafanaを使用します。 Grafana自体にもアラート機能はありますが、マイクロアドのインフラチームでは使用していません。
Datadog
3つ目がDatadogです。
Datadogとは、アラートツールを兼ね備えた監視サービスです。
マイクロアドでは、プロダクトの管理画面の外形監視として使用しています。
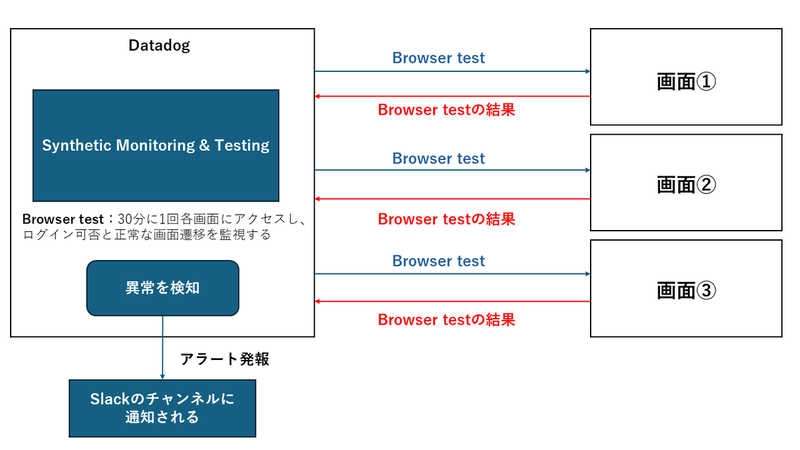
DatadogのSynthetic Monitoring&Testing機能を使用し、定期的な時間間隔でBrowser testを行います。
Browser testでは、各管理画面のログイン可否と正常な画面遷移ができることを監視します。
アラート発報までは、以下の通りです。
Cacti
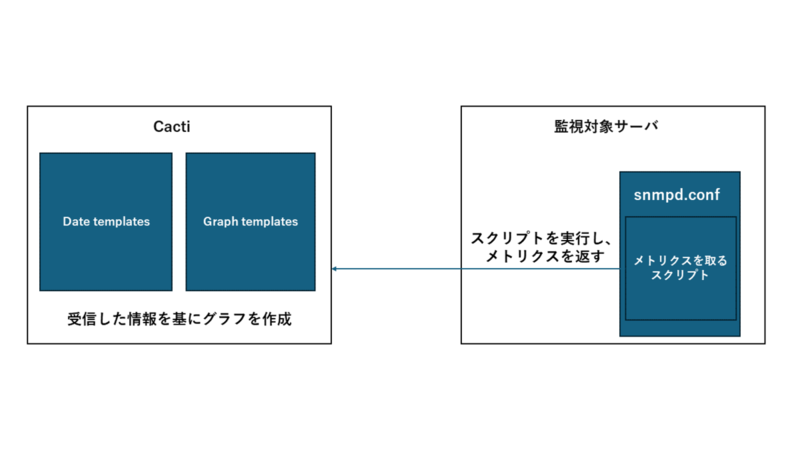
4つ目がCactiです。 Cactiとは、オープンソースのシステム監視とグラフ化を行うツールです。
- SNMPを使用して監視対象の情報を取得し、RRD(Round Robin Database)形式でグラフ化を行う
- 長期的なトラフィックの監視に適している
マイクロアドでは、Cactiを年単位の長期的なグラフの表示に使用しています。
監視対象サーバにSNMPをインストールし、snmpd.confにメトリクスを収集するスクリプトを配置します。
監視対象で収集した情報は、SNMPを用いてCactiに送信します。
Cactiでのグラフ表示方法は以下の通りです。
※マイクロアドではVictoriaMetricsで年単位のメトリクスを保持しています。
しかし、利用しているOSS版VictoriaMetricsにダウンサンプリング機能がないため、年単位のグラフ化がGrafanaでは困難です。
そのため、RRD形式でダウンサンプリング出来るCactiを長期モニタリング用として併用しています。
ただ、VictoriaMetricsを用いた改善にも取り組んでいます。詳細については、以下の記事をご参照ください。
おわりに
今回は、マイクロアドで使用している監視ツールや監視の仕組みについてお話しました。
研修前の監視のイメージは、「異常を検知したらアラートが発報されて通知がくる」というざっくりした印象でした。
しかし、監視ツールの内部ではエージェントを起動させたりという複雑な構成をしていることを知りました。
今後業務を遂行するにあたって、上記で紹介した監視ツールを活用し、障害対応を迅速に行うことがインフラエンジニアとして大切だと学びました!
新卒インフラエンジニア絶賛採用中
マイクロアドでは技術への探究心があり、最新の技術・動向について積極的に学び活かす意欲を持った仲間を募集しています!またインフラエンジニアだけでなく、サーバサイド、機械学習エンジニアなど幅広く募集しています! 気になった方は以下からご応募ください!
- openmetrics形式でメトリクスを吐き出すアプリについてはexporterなしでスクレイプしています↩
- Prometheus内部のtsdbに短期保存すると同時にVictoriaMetricsというtsdbをもつクラスタにも書き込み、こちらは長期保存しています。↩