はじめに
初めまして。マイクロアド24年新卒インフラエンジニアの齊藤( id:saitoperf )です。 今回は、インフラ研修で取り組んだ「自作PCの性能評価」について紹介します。
インフラ研修では、パーツ選定 → 組み立て → WordPressのデプロイ → 評価実験までの流れを体験しました。 マイクロアドではオンプレが主流のため、 インフラエンジニアは「コストを意識したサーバ調達 → ラッキング → 構築後のパフォーマンスチェック」の一連に対応できる必要があります。 また、これらの作業が終わった後にも、メモリやストレージの故障といった断続的に発生するインシデントにも対応していく必要があります。
そこで本研修では、今後これらのタスクへ対応できるようになるため、以下の素養を習得することを目的としています。
- 調達の予算を10万円に設定することで、コストへの意識を育む
- 実際に組み立てを行うことで、計算機を構成する装置の概要や設置方法を知る
- パフォーマンスをチェックすることで、収集すべきメトリクス・チューニング方法・テストに関する技術を養う
環境構築
自作PCパーツの選定
24卒のインフラ配属は2人で、1人10万円以内の予算での好きにパーツを選定できたので、異なる特徴を持ったPCを2台組むことにしました。
- 案1: とにかくCPUに予算を全振りする
- 案2: メモリとSSDに予算を全振りする
コンピュータを構成する5大装置は、 演算装置、制御装置、記憶装置、入力装置、出力装置ですが、性能に大きく影響を及ぼすのは演算装置(CPU)と記憶装置(メモリ・SSD)になります。 そこで今回は、演算装置と記憶装置にそれぞれ性能を特化させて、パフォーマンスを比較することにしました。
パーツの購入は、基本的には価格.comを使って価格の安いショップ順にソートして購入しました。 途中で案2のSSDの価格が5千円上昇するなどのトラブルもありましたが、少しスペックダウンさせた別の商品を選ぶなどして無事10万円以内に収めました。 こちらは購入したパーツと購入時の値段になります。
表. 購入パーツ
| 案1(CPU性能重視案) | 案2(I/O性能重視案) | |
|---|---|---|
| CPU | Intel Core i7-13700K/64,480円 | Intel Core i5 12400/24,980円 |
| メモリ | ADATA AD4U266616G19-RGN/4,550円 | Kingston KVR48U40BS8-16/6,280円 |
| SSD | ADATA LEGEND 700 ALEG-700-256GCS/3,480円 | CFD PG5NFZ CSSD-M2M1TPG5NFZ/23,210円 |
| CPUグリス | MoneyQiu HY-883-2g/509円 | JLJ TP-133/799円 |
| 電源 | MSI MAG A650BNL/6,980円 | 玄人志向 KRPW-L5-400W/80+/REV2.0/6,045円 |
| CPUクーラー | Thermalright Assassin X 120 V2/2,049円 | Thermalright Assassin X 120R SE/2,299円 |
| マザーボード | MSI PRO B760M-G DDR4/14,300円 | ASRock Z790 Steel Legend WiFi/30,885円 |
| PCケース | ZALMAN T8 ミドルタワーPCケース/3,506円 | ZALMAN T8 ミドルタワーPCケース/3,506円 |
| 合計価格 | 99,854円 | 98,004円 |
案1のCPUはコンシューマ向けとしてはかなり高性能で、価格も64,980円と案2の倍以上の金額でした。 一方案2では、SSDとメモリの世代を最新にしました。 また、マザーボードはメモリとSSDの世代に対応するものを使わないと性能を充分に発揮出来ないので、案1の倍の金額になりました。
下記の表はスペックの比較になります。 CPU性能を比較すると、案1は案2より最大クロック周波数が1 GHz高く、コア数も倍以上あります。 一方で、メモリ性能は案2の方が2倍弱高く、ストレージ性能はRead/Writeともに5倍高いです。
表. 自作のスペック比較
| 案1(CPU性能重視案) | 案2(I/O性能重視案) | |
|---|---|---|
| CPUモデル | Core i7 13700K | Core i5 12400 |
| クロック周波数 | 5.4 GHz | 4.4 GHz |
| 物理コア数/スレッド数 | 16/24 | 6/12 |
| L3キャッシュサイズ | 30 MB | 18 MB |
| メモリ | DDR4-2666 16 GB | DDR5-4800 16 GB |
| ストレージ (read/write) |
M.2 SSD Gen3 (1.9/1.6 GB/s) |
M.2 SSD Gen5 (9.5/8.5 GB/s) |
OSとWordPressのインストール
OSはUbuntu 24.04を使います。マイクロアドのインフラにはUbuntuとCentOSが使われていますが、現在は全面的にUbuntuへの移行を進めています。
マイクロアドではデータセンタに自社サーバを所有しており、
基本的にMAASを使ってベアメタルのサーバにOSをインストールしています。
しかし、今回の自作PCは渋谷のオフィスに設置するためMAASが使えないことから、USBでOSをインストールしました。
OSのインストールが完了したら、Ansibleを使って環境を構築します。
また、AnsibleのPlaybookを適用する前に、作成したPlaybookが期待した動作になるかテストするためにMolecule1を使いました。
※作業の様子です。

実験では、自作PC(以下TargetServer)の他に、負荷をかけるためのサーバ(以下RequestServer)とAnsibleを実行するTestServerを用意します。
- TargetServer: Dockerエンジンを入れてWordPressコンテナを起動させる
- RequestServer: K6というOSSの負荷テストツールを入れて、TargetServerに対して負荷テストを実施する
- TestServer: Ansibleを実行したり、各サーバに対して実験のコマンドを流す

評価実験
実験ケース
K6は、実験のシナリオを記載したJavaScriptのコードを基に、負荷テストを実施します。 スクリプトには「リクエストを送るURL」「仮想ユーザ数(リクエストを送るスレッドのような概念)」「実験時間」のような様々な情報を記載することができます。 案1(CPU性能を重視)と案2(ディスクI/Oを重視)のパフォーマンスを比較するため、4つの実験ケースを用意しました。 ケース1から3は、データをアップロードすることでディスクへの書込みを発生させるため、 CPUとディスクの両方に負荷がかかるような実験となっています。 またケース1から3では、ディスクの読込みが発生しないので、ケース4でディスク読込みが発生するような実験を実施します。
- ケース1
- 実験名: submit_article (記事の投稿)
- API:
http://<TargetServer URL>/wp-json/wp/v2/posts - 概要: タイトルが「Sample articles」、コンテンツが「テスト投稿」という記事を投稿
- ケース2
- 実験名: submit_comment (コメントの投稿)
- API:
http://<TargetServer URL>/wp-json/wp/v2/comments - 概要: ある記事に対して、20文字のランダム文字列のコメントを投稿
- ケース3
- 実験名: submit_picture (画像のアップロード)
- API:
http://<TargetServer URL>/wp-json/wp/v2/media - 概要: 画像(2MB)をWordPress上にアップロード
- ケース4
- 実験名: download_picture (画像のダウンロード)
- API:
http://<TargetServer URL>/wp-content/uploads/2024/06/image-xxx.png - 概要: 予め投稿しておいた1000枚の画像をランダムでダウンロード
WordPressでは、デフォルトのパーマリンク設定ではAPIが叩けないのでPost nameに変更します。
パーマリングの設定はWebの管理画面からでも変更できますが、
WordPressのCLIツールのwp使って変更することもできます。
wp option update permalink_structure '/%postname%/'
実験の流れ
各実験ケースに対して以下の処理を実施します。
- まず、TargetServerでページキャッシュをクリアしてから、
sarコマンドを実行して1秒置きにリソース状況をresult_sar.binに記録する - 次に、K6でRequestServerからTargetServerに1分間負荷をかける
- K6の負荷テストが終わったら
sarコマンドを終了させ、TargetServer上でresult_sar.binをjson形式に成型してscpでTestServerにコピーする
TargetServer上でjsonへの変換まで実施する理由は、sarコマンドが入っているsysstatパッケージのバージョンが異なると、
バイナリファイルから正しくjsonに変換できないためです。
また、vm.dirty_ratioというページキャッシュに関するカーネルパラメータをデフォルトの20から0に変更した場合の実験も実施します。
ページキャッシュ内のダーティなデータの割合がvm.dirty_ratioを超えるとディスクへの書込みが発生します。
TargetServer2台、4つの実験ケース、2つのvm.dirty_ratioで、計16回の負荷テストを行いました。
事前調査
K6による負荷テストを実施する前に、メモリI/OとディスクI/Oを調べます。
メモリI/Oの計測にはsysbenchを使いました。
メモリI/Oは、案1の方が良いパフォーマンスとなりました。
メモリは案1がDDR4なのに対して案2がDDR5なので、案2の方が高いメモリI/O性能となることが予想されましたが、予想とは異なる結果となりました。
原因として、CPUキャッシュ容量が大きい事や、CPUクロックに引張られて性能が出ていない、といったことが考えられます。
また、BlockSizeを大きくするとスペック値を超えることが分かりました。
これは、シーケンシャルなアクセスが増えるため、CPUキャッシュにヒットしている可能性が考えられます。
表. メモリI/O [GiB/sec](Read/Write)
| スペック値 | BlockSize=64B | BlockSize=1kiB | BlockSize=1MiB | |
|---|---|---|---|---|
| 案1 (CPU性能重視) | 20.8 | 0.94/0.93 | 13.8/11.7 | 57.2/43.8 |
| 案2 (I/O性能重視) | 37.5 | 0.76/0.76 | 11.3/9.64 | 53.6/36.4 |
ディスクI/Oは、案2の方が良いパフォーマンスとなりました。
案1のhdparmとbonnie++の結果がスペック値を超えている原因は、メモリのページキャッシュを使っている可能性が考えられます。
表. ディスクI/O [GiB/sec](Read/Write)
| スペック値 | hdparm | dd seq | dd rand | bonnie++ | |
|---|---|---|---|---|---|
| 案1 (CPU性能重視) | 1.9/1.0 | 2.2/- | -/0.82 | -/0.49 | 1.8/1.6 |
| 案2 (I/O性能重視) | 9.5/8.5 | 3.7/- | -/1.5 | -/0.49 | 3.4/2.7 |
K6による負荷実験
リクエスト・レスポンスの時間
submit_picture以外のリクエストでは、案1の方が良いパフォーマンスとなりました。 特にsubmit_commentでは、ほとんどの統計値に置いて倍近くの差がありました。 事前調査では、案1の方がCPU性能とメモリI/O性能の実測値においてパフォーマンスが優れていたので妥当な結果でした。
表. 応答時間の統計値 [ms] (CPU性能重視案/I/O性能重視案)
| 中央値 | 平均値 | 最小値 | 最大値 | p(95) | |
|---|---|---|---|---|---|
| submit_article | 32.4/40.5 | 36.6/42.8 | 22.9/25.3 | 130/150 | 61.0/62.3 |
| submit_comment | 26.5/51.3 | 27.8/52.0 | 13.8/33.0 | 82.4/146 | 43.0/64.8 |
| submit_picture | 586/714 | 586/716 | 520/642 | 726/912 | 612/782 |
| download_picture | 53.4/63.6 | 72.0/71.8 | 17.7/23.7 | 682/730 | 183/118 |
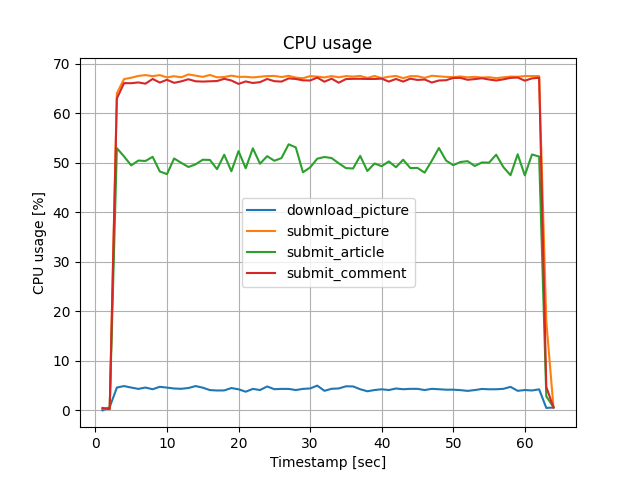
CPU使用率
download_pictureは、他と比べてCPUリソースを使わないことが分かりました。 そのために、前述のリクエスト・レスポンス時間が案1と案2で唯一拮抗していたと考えられます。

ロードアベレージ
ロードアベレージ一般的に、以下のように言われています。
- コア数の半分: 穏やか
- コア数と同じ: フル活用
- コア数より多い: 過負荷
案1はロードアベレージがコア数の半分程度なのでCPUは穏やかに稼働している一方で、 案2ではコア数よりロードアベレージが2~3多くCPUは過負荷状態でした。


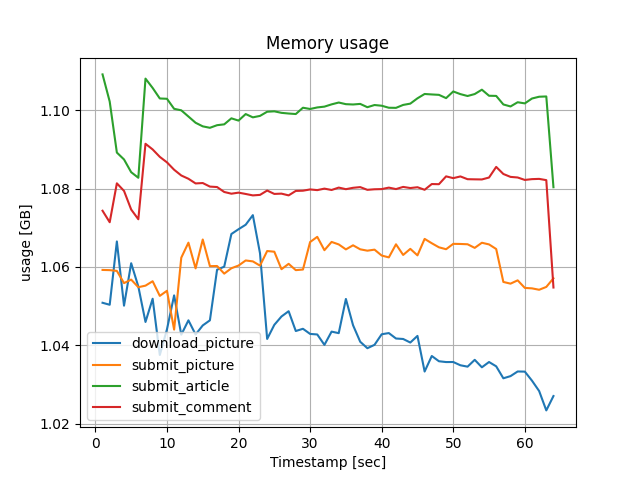
メモリ使用量
メモリはどちらの案においてもほとんど使われないことが分かりました。
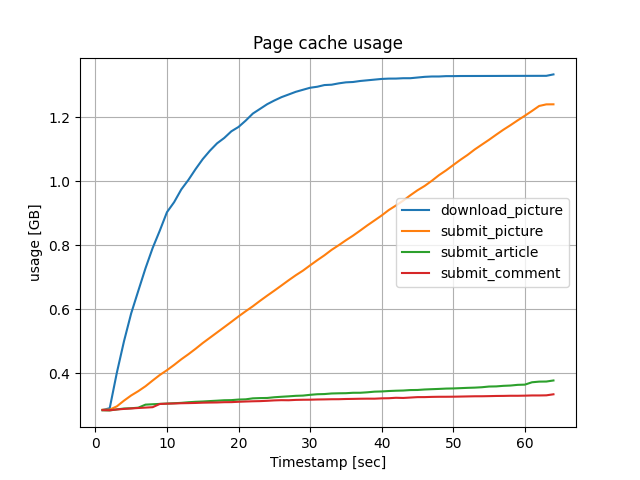
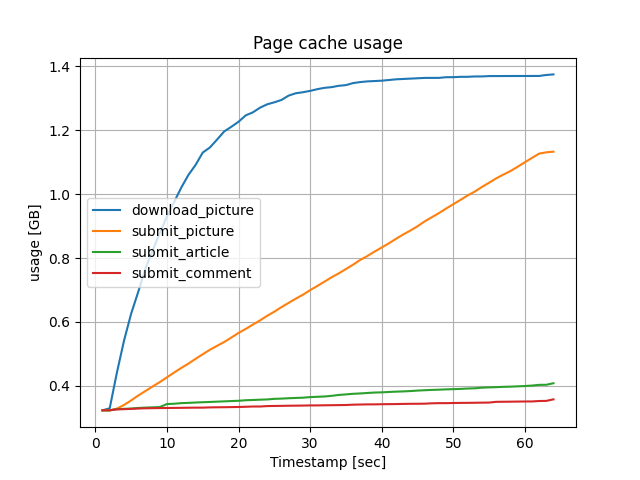
ページキャッシュは、download_pictureとsubmit_pictureで大きく使われることが分かりました。
download_pictureは、予めアップロードしてある1000枚の画像をランダムにダウンロードするので、
最初の30秒程度で、ディスク上にあるほとんどの画像データがキャッシュされています。
submit_pictureは、次々に画像をアップロードするリクエストなので、線形的に増加しています。

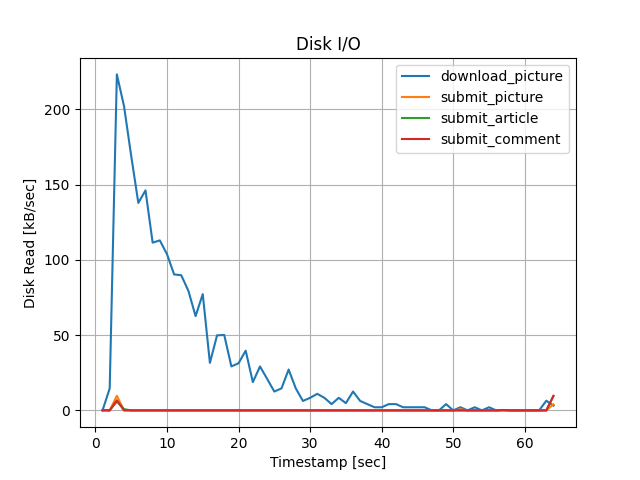
ディスクI/O:読込み
download_picture以外のリクエストでは、ディスク読込みはほとんど発生しませんでした。 一方で、download_pictureでは、ディスク読込みが開始30秒あたりまで発生しています。 これは、実験開始から30秒程度でページキャッシュにキャッシングされたことが原因だと考えられます。 また、どのリクエストにおいてもTargetServer間での差は見られませんでした。

ディスクI/O:書込み
submit_pictureに関しては、案1の方が10 [kB/sec] 程度大きくなりました。 これは、K6で送ったリクエスト数が単純に多かったことが考えられます。 K6の仮想ユーザは、レスポンスを受け取ってから次のリクエストを発行するため、 応答時間が長いとその分送るリクエスト数も減少します。
特定のタイミングでスパイクしているのは、ある程度メモリ(ページキャッシュ)に書き込まれたタイミングで一気にストレージに書込むためです。
カーネルパラメータvm.dirty_ratioの値を変更することで、
ページキャッシュとストレージの齟齬が何%になったらストレージへ書込むかを変更できます。
vm.dirty_ratioを0にすると、スパイクは発生せず継続的にストレージへの書込みが発生しました。


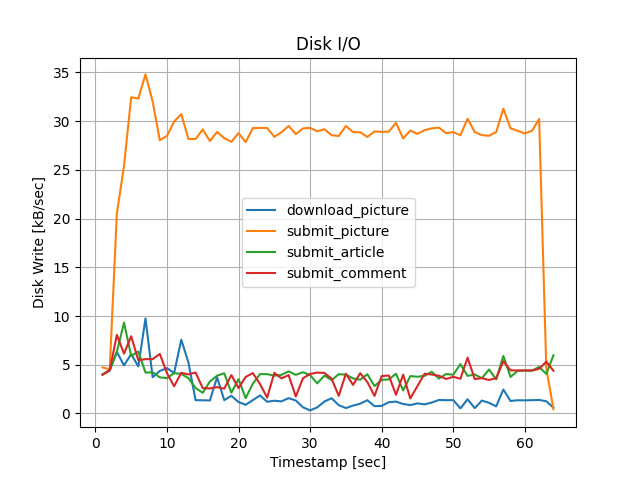
表. リクエスト・レスポンス数
| 案1: 成功 | 案2: 成功 | 案1: 失敗 | 案2: 失敗 | |
|---|---|---|---|---|
| submit_article | 13063 | 11189 | 0 | 0 |
| submit_comment | 17098 | 9199 | 0 | 0 |
| submit_picture | 822 | 673 | 0 | 0 |
| download_picture | 6615 | 6615 | 0 | 7 |
実験のまとめ
WordPressを動作させる場合、CPU性能重視案(案1)の方がI/O性能重視案(案2)よりもパフォーマンスが良くなるという結果になりました。 ただし今回の場合、CPU性能が低くメモリ性能を充分に発揮できていない可能性があるため、 一概にI/O性能よりもCPU性能の方が重要だとは断言できません。
また、画像ダウンロードなどのストレージ読込みが多く発生するようなワークロードの場合、 ページキャッシュの恩恵が大きいということが分かりました。 ただし、ページキャッシュに乗り切らなくなるような状況は、本実験では実現できなかったので、 そのようなケースディスクI/O性能がどのように効いてくるのかは要調査です。
おわりに
インフラ研修では、自作PCのパーツ選定から負荷実験までを行いました。 自作PCを組み立てるのは初めてだったので、楽しく作業を進めることができました(最近はノートパソコン生活です)。 パーツの選定では、限られた予算の中で最良のパーツを選んでいくという作業を経験したので、 今後業務でサーバ選定をする機会に役立てられたら良いです! 実は、組み立ての際にCPUピンを曲げてしまったり、PCケースが不良品でボタンが押せなかったり色々ありましたが、 最終的には結果のグラフ化までできてこうしてブログが書けてよかったです!
新卒インフラエンジニア絶賛採用中
マイクロアドでは技術への探究心があり、最新の技術・動向について積極的に学び活かす意欲を持った仲間を募集しています! またインフラエンジニアだけでなく、サーバサイド、機械学習エンジニアなど幅広く募集しています! 気になった方は以下からご応募ください!