はじめに
初めまして。マイクロアド21年新卒インフラ担当の森( id:bosq )と申します。
7月に新卒研修を終えてからは、基盤開発グループにて日々勉強しています。 配属後は新しいことのインプットが多いため、今回は学んだことの整理とアウトプットを兼ねて、マイクロアドのデータ基盤で利用しているHadoopについて紹介したいと思います。
- はじめに
- 分散処理基盤 Hadoop / CDH とは
- Hadoop エコシステム
- データストレージ (HDFS) と リソース管理 (YARN)
- 分散処理エンジン (MapReduce, Tez, Spark)
- クエリエンジン (Hive, Impala)
- まとめ
- マイクロアドのデータ基盤に関する記事
- 参考文献
分散処理基盤 Hadoop / CDH とは
Hadoopは、大規模データを複数台のサーバで分散処理するための基盤となるミドルウェアです。 複数のサーバを用いるクラスタ構成のため、大規模データを処理することが可能となります。 また、クラスタ構成のため、サーバを増築するだけで容易にスケールアウトができます。
HadoopはApacheプロジェクトのOSSですが、様々な企業によるディストリビューションが存在します。
- Apache Hadoop: Apache コミュニティによる管理
- CDH (Cloudera's Distribution including Apache Hadoop):Cloudera社の製品(現在は保守のみ)
- HDP (Hortonworks Data Platform):Cluodera(旧Honrtonworks)社の製品(現在は保守のみ)
- CDP (Cloudera Data Platform):Cloudera社の製品(CDHとHDPの後継となる製品)
- MapR CDP (MapR Converged Data Platform):MapR Techonologies社の製品
- BigInsights:IBM社の製品
- Pivotal HD:Pivotal社の製品
この中でマイクロアドでは、Cloudera社のCDH (Cloudera’s Distribution of Apache Hadoop) を利用しています。
通常のApache Hadoopは、HDFSやHiveなどのコンポーネントと共に利用されるため、それぞれのコンポーネント毎で構築・管理が必要となります。 一方、CDHではHadoopに加えて、Apache HiveやApache Impalaなど各種コンポーネントが1つのパッケージとして配布されているため、エコシステムの構築が容易になります1。 また、Cloudera Manager2というGUIのソフトウェアで各コンポーネントを管理できるため、運用しやすいことがメリットとなります。 デメリットとして、各コンポーネントをまとめて1つのパッケージとして配布されるため、一部のコンポーネントのみバージョン変更することはできません。
Hadoop エコシステム
Hadoopが分散処理基盤として提供する機能として、HDFS・YARN・MapReduceがあります。 しかし実際にHadoopを利用する際には、要件に応じて他にも様々なソフトウェアをコンポーネントとして組み合わせます。 様々なコンポーネントによって構築された分散処理基盤は、Hadoopエコシステムと呼ばれ、以下のような関係となっています。
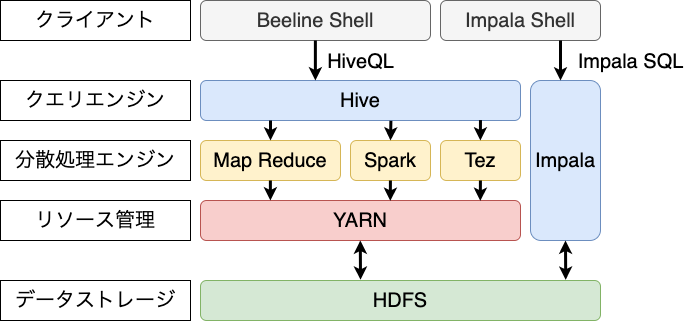
本記事では、Hadoopエコシステムの一例を示し、各コンポーネントについて解説します。
データストレージ (HDFS) と リソース管理 (YARN)
HDFS (Hadoop Distributed File System)
Hadoopでは、データストレージにはHDFS (Hadoop Distributed File System)が用いられます。 HDFSは、通常のファイルシステムと異なり、ファイルを一定サイズのブロックという単位で分割し複数サーバで分散して保存します。 この特徴から以下の利点があります。
- フォールトトレランス設計
- 高スループット
フォールトトレランスは、一部が故障・停止しても機能を保ち、正常に稼働させ続けるための仕組みです。 HDFSでは、分割したブロックを複数のノードで保存することで冗長性を持たせます。 保存するノードの数は、複製係数 (replication factor) として設定可能であり、デフォルトでは3ノードに保存されるようになっています。
HDFSが分散してブロックを管理するために、HDFSではノード毎に以下のような役割があります。
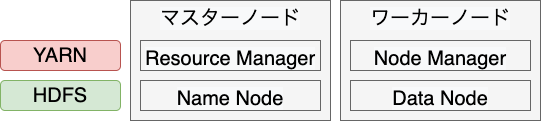
- NN (Name Node): 各ノードを管理する
- DN (Data Node): 実際にデータを格納する
YARN (Yet Another Resource Negotiator)
YARN(Yet Another Resource Negotiator)は、Hadoopクラスタに属する各ノードのリソース管理をするための汎用的なフレームワークです。 YARNが独立してリソース管理をしているため、MapReduce以外にApache SparkやApache Tezなどの分散処理エンジンをエコシステムに同居させることができます。
YARNは、以下のサービスによって構成されます。
- Resource Manager: 利用可能な計算リソースやData Nodeの状態を管理する
- Node Manager: ワーカーノードで実際にタスクを実行する
ノードの役割
Hadoopクラスタは、マスターノードとワーカーノードによって構成されます。 マスターノードは、Hadoopを利用するクライアントと実際にやりとりをし、要求された仕事をワーカーに割り当てます。 ワーカーノードは、名前の通りマスターから割り当てられた仕事をする役割を持ちます。
マスターとワーカーで、HDFSとYARNの役割をまとめると以下のようになっています。
分散処理エンジン (MapReduce, Tez, Spark)
分散処理エンジンは、大量のデータを扱うために複数のワーカーで並列で処理するための仕組みです。 元々はHadoopの分散処理エンジンとしてMapReduceが利用されていましたが、YARNによるリソース管理によって、要件に合わせた分散処理エンジンが利用できるようになりました。 ここでは、3つの分散処理エンジンについて紹介します。
MapReduce
MapReduceはHDFSのように複数サーバに分散されたデータを並列処理するための計算モデルです。 MapとReduceと呼ばれる処理から成り立ち、各処理は独立しているため分散処理が可能となります。
具体的な処理について、解説によく用いられるWord Countの処理を例に説明します。 Word Countは文章中の各単語の出現回数を計算する処理です。
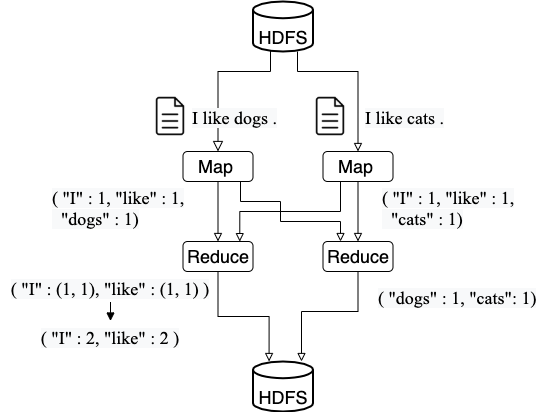
Map処理では、HDFSから入力値を受け取り、key-valueの形式に変換し出力します。 例では、「I like dogs.」という文から ("I": 1, "like": 1, "dogs": 1)という各単語の出現数のデータを生成します。 次に、Keyに応じてデータを分けて、Reduce処理をしていきます。共通のKeyを持つデータは、図の左側のReducerのように足し合わせることで単語の出現回数が計算されます。 最後に、各Reduceで出力値をHDFSに書き出します。
重要な点は、MapとReduceで実行されるそれぞれの処理が完全に独立しているため並列実行できることです。 これにより、逐次処理では扱えない大規模なデータを扱えるようになるため、データ基盤ではバッチ処理に使用されています。
Apache Tez
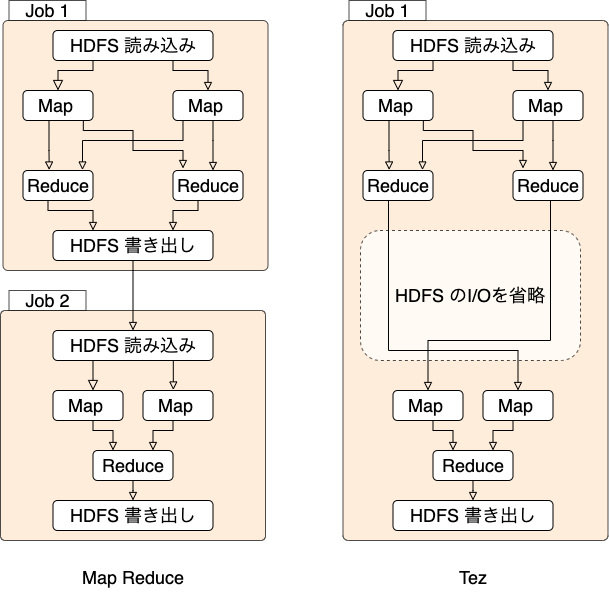
MapReduceでは毎回必ずHDFSへの読み書きをするため、MapReduceを何回も繰り返すジョブの場合はHDFSへの読み書きが何度も発生します。 Tezでは、MapとReduceの処理を組み合わせた1つのジョブとして定義することができ、毎回発生していたHDFSへの書き込みのオーバーヘッドをなくす事ができます。 Tezは、後述するApache Hiveの内部でジョブを効率良く実行させるために利用されています。
Apache Spark
MapReduceやTezは大量のデータを時間をかけてバッチ処理するのに適した仕組みですが、 システムログや広告配信システムなどのリアルタイム処理には不向きです。 そこで、リアルタイムでデータ分析基盤にデータを取り込むストリーミング処理にはApache Sparkが利用されます。
Sparkは、HadoopのYARN上で構築することでHadoopエコシステム内に構築することができます。 そのため、Hadoopの利点を持ったまま、HDFS上のデータに対してSparkを利用することができます。
Sparkには標準で、用途に応じた以下のようなライブラリが入っています。
- Spark SQL: 構造化データを処理
- Spark Streaming: ストリーミング処理
- MLlib: 簡易的かつスケーラブルな機械学習をサポート
- GraphX: 大容量のグラフデータを分散処理
Sparkは、MapReduceやTezと比べて、インメモリで処理するため高速です。 データは、RDD(Resilient Distributed Datasets)と呼ばれる単位でメモリに保持します。
リアルタイムで処理したい場合はSparkを利用し、メモリに乗り切らないようなデータを対象としたバッチ処理はMapReduceかTezが向いています。
クエリエンジン (Hive, Impala)
クエリエンジンは、クエリに応じてHDFSに格納されているデータの抽出や変換を行います。 クライアントからの操作には、RDBで使われるSQLに似たクエリ言語を用います。 主なクエリエンジンとして、Apache Hive と Apache Impala が用いられています。
Apache Hive
Hiveは、HiveQLと呼ばれるSQLに似たクエリ言語を用いることでデータの操作をします。 クエリは、Hiveの内部でMapReduce か Spark のジョブとして実行されます。 Hiveでは、データ処理が終わる度にディスクI/Oが発生し、時間がかかってしまいます。 そのため、時間のかかるようなバッチ処理に向いています。
アーキテクチャはHive Metastore ServerとHive Server2で構成されます。
Hive Metastore Serverは、Hiveテーブルというメタデータの管理をします。 メタデータとは、Hiveで扱うデータのスキーマ定義とName Nodeが管理するHDFSのブロックの場所のことです。
Hive Server2は、実際にクライアントとやりとりをするノードになります。 HiveのCLIツールとして提供されるBeelineなどからアクセスできるようになっています。 また、複数のHiveクライアントからの同時処理には、Apache Zookeeperという別のソフトウェアが必要になります。 Apache Zookeeperは、Apache Kafkaでも協調動作に利用されています。
HiveをOLAP(Online Analytical Processing)のように素早くレスポンスを返す用途では、Hive LLAPと呼ばれる機能がHive2.0から利用可能です。 LLAPを用いることでLLAPのデーモンにデータをキャッシュさせることができ、同じデータを短期間で何度も参照するような場合に高速化することができます3。
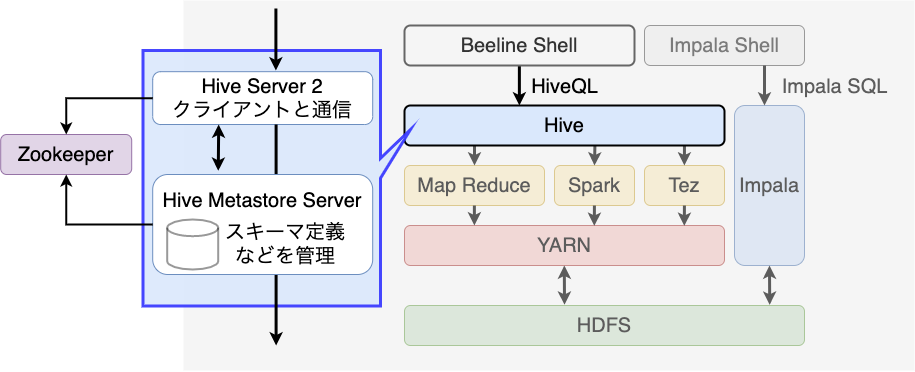
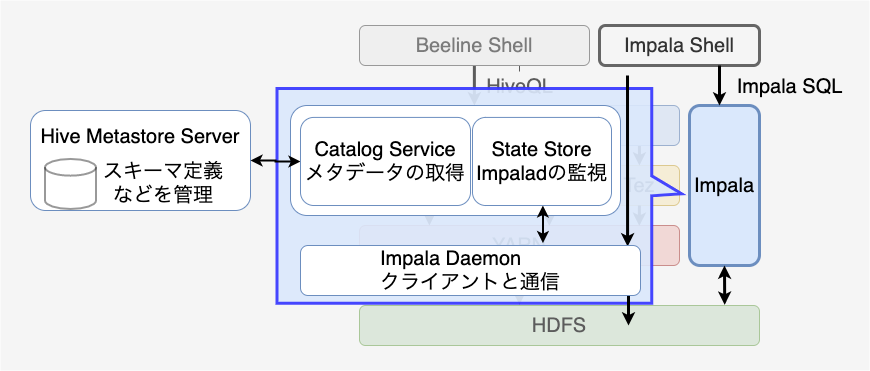
Apache Impala
Impalaは、Hiveと同じようにImpala SQLと呼ばれるSQLに似たクエリ言語が使用されます。 しかし、Hiveと異なり、MapReduceやSparkのジョブとしては実行されず、独自のエンジンで実行されます。 MapReduceなどでは各ノードからデータを集めて処理しますが、Impalaはデータのあるノードで処理を実行するように最適化されるためHiveよりも高速です。 そのため、アドホック分析のように短時間で何度も実行するような処理にはImpalaが適しています。
もう一つの重要な点として、ImpalaはHive Metastore Serverのメタデータを共有しています。 Impalaのアーキテクチャ4は、マスターで実行されるCatalog ServiceとState Store、ワーカーで実行されるImpalaデーモンで構成されています。 Catalog Serviceは、Hive Metastore Serverのメタデータを参照し、Impalaがデータを利用できるようにする役割を持ちます。 State Storeは、Impalaデーモンの状態を管理し、Catalog Serviceが得たデータを配布する役割を持ちます。 ワーカーで起動するImpalaデーモンは、クライアントとやりとりをします。 クエリを受けると他のワーカーで起動するImpalaデーモンと連携してクエリを実行します。 そのため、クライアントはどのワーカーにクエリを投げても構いません。
マイクロアドでは、用途に応じてHiveとImpalaを利用しています。 以下の記事では、クエリエンジンをHiveからImpalaにしたことで高速化したことを紹介しています。
まとめ
本記事では、CDH (Hadoop)で用いられる主要なコンポーネントについて紹介しました。 Hadoopエコシステムは、様々なコンポーネントから構成されており理解が難しく、用途に適したコンポーネントを使う必要があります。 また、マスターノード・ワーカーノード間のリソース管理の仕組みや、用途に応じたクエリエンジンの選び方など、 自分が学習する際に分かりづらかった点についてまとめました。 この記事が少しでも理解の助けになれば幸いです。
マイクロアドのデータ基盤に関する記事
参考文献
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料) https://www.slideshare.net/hamaken/hadoop-cloudera-world-tokyo-2014 (参照 2021-09-13)
Apache Hadoop YARNとマルチテナントにおけるリソース管理 https://www.slideshare.net/Cloudera_jp/apache-hadoop-yarn-107568692 (参照 2021-09-13)
Apache Tezの解説 | Hadoop Advent Calendar 2016 #07 https://dev.classmethod.jp/articles/hadoop-advent-calendar-07-tez/ (参照 2021-09-13)
Hadoop MapReduce入門 | Hadoop Advent Calendar 2016 #01 https://dev.classmethod.jp/articles/hadoop-advent-calendar-01-introduction-mapreduce/ (参照 2021-09-13)
Hadoopはどのように動くのか ─並列・分散システム技術から読み解くHadoop処理系の設計と実装 https://gihyo.jp/admin/serial/01/how_hadoop_works (参照 2021-09-13)
-
CDH(v6.3.3以降)やHDP(v3.1.5以降)、CDPは有償ライセンスですが、Apache BigtopとApache Ambariによるクラスタ構築であれば無償でお試し可能です。↩
-
https://jp.cloudera.com/products/product-components/cloudera-manager.html↩
-
Hive LLAP詳細は以下をご覧ください。
https://dev.classmethod.jp/articles/hadoop-advent-calendar-09-hive-llap/
https://community.cloudera.com/t5/Community-Articles/Hive-LLAP-deep-dive/ta-p/248893↩ -
より詳細についてはこちらが参考になります。
Apache Impalaパフォーマンスチューニング #dbts2018↩