はじめまして。サーバサイドエンジニアの前西と申します。主にETL処理*1のバッチ開発を行っています。
マイクロアドでは、広告配信ログやアクセスログなどのデータを元にして、様々な加工を行った上で蓄積を行なっています。
今回の記事では、私が普段業務で扱っているデータの蓄積処理について、生ログが加工されてデータの利用者側へと渡るまでの流れをご紹介できればと思います。
データ基盤
以前の記事でも紹介されていますが、マイクロアドではデータ基盤にHadoopを利用しています。
下図のように、Kafkaに集約された数TB規模の広告配信ログ・アクセスログはFlumeでHadoopクラスタへと転送された後、Hadoop内で加工や集計などの処理が行われています。
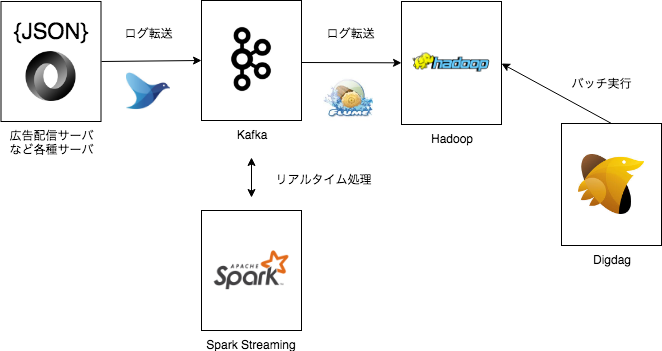
ログ変換
HadoopではJSON形式の生ログからParquet形式のデータへの変換がまず行われます。圧縮可能なフォーマットへと変換することで容量を削減でき、データの長期保存が可能となります。
圧縮可能なフォーマットにはいくつか種類がありますが、その中でParquetが選ばれた理由には、
などが挙げられます。
集計処理
Parquet形式に変換されたログを出発点として、様々な集計処理が行われます。これ以降の集計処理で生成されるデータも一部の例外を除き全てParquet形式で蓄積しています。
集計内容はビジネス要件に応じて多岐にわたります。
集計クエリの大きさも、軽くSELECTするだけのものもあれば、複数のテーブルをJOINしてまとめ上げる処理を何度も繰り返すような複雑なものまで様々です。ここ最近は、扱うデータが幅広くなってきたことで複雑な集計バッチが増えてきたように感じます。
集計は1時間単位でのバッチ処理で行われるものがほとんどです。過去は1日単位での集計が多かったのですが、データの複雑化や肥大化などから集計に掛かるリソースが上がってきたこともあり、実行単位を細かく分割する流れとなりました。
ジョブの管理ツールにはDigdagを利用しています。Digdagの採用に至った経緯や、Digdagバッチの構成の詳細については以前の記事で詳しくまとめられているので、そちらもぜひご覧いただければと思います。
上記の記事にもあるように、バッチ実行基盤にDigdagを採用したことによるメリットは非常に大きいです。
特に大きなメリットだと感じているのは、実際の実行時間に依存せず実行予定時間を担保するsession_timeの概念のおかげで、処理対象の時間が実際の実行時間に依存しないことです。このため、障害が発生した場合の過去分リカバリがとてもしやすくなっています。
また、s3_waitオペレータを利用したジョブ同士の依存関係の制御も、データの不整合を防ぐのに役立っています。
最近では、集計されたものがさらに別の複数の集計処理のインプットになっていたりと、ジョブ同士・データ同士の依存関係が非常に複雑になっています。ワークフローでこのような制御が可能なおかげで、保守・運用における手作業によるオペレーションが大幅に軽減されていると言えます。
Digdagが導入されて2年程が経過しますが、改めてDigdagは本当に素晴らしいと感じます。
利用用途に合わせたデータ転送
Hadoopで集計されたデータは、Hadoopクラスタ内でも適宜参照されていますが、必要に応じて別のクラスタやデータストアにも転送を行なっています。
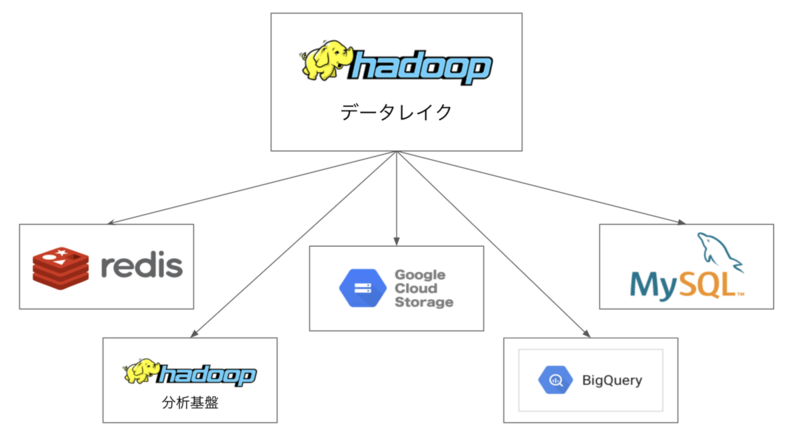
例えば、広告配信システムが入札額を算出するのに必要な特徴量のようなデータは、RTB*4にレスポンス速度が要求される都合上、高速に参照できることが求められます。そのため、このようなデータは高速アクセスが可能なKVSであるRedisに蓄積を行なっています。
また、データレイクに影響を与えることなく分析を行うためにデータレイクとは別に分析用のHadoopクラスタを構築しており、アドホックな分析や機械学習に用いられるデータはここに転送され蓄積されていきます。データ分析基盤については以下の記事で詳しく紹介されていますので、こちらも合わせてご覧ください。
他には、主に画面参照用のデータの蓄積用途にMySQL、ビジネス目的の分析や請求用のデータの蓄積用途にBigQueryやGoogle Cloud Storageなども利用されています。
保守・運用
データが常に正確で整備された状態を保つためには、日々の保守・運用作業が不可欠です。特に、障害の発生時にはデータの生成状況を目視で確認することも必要となります。
元データの生成が停止したり遅れたりすると、後続のデータ生成にも影響が生じてしまいます。いち早く異常を検知するための工夫として、以下のような取り組みも合わせて実施しています。
- バッチ処理失敗時・遅延時のSlackへのアラート通知
- Kafka転送状況のリアルタイム監視・グラフ可視化
- ストリーミング処理のリアルタイム監視・グラフ可視化
データ生成の処理速度や精度を高めつつも、手作業による運用作業をできる限り減らせるよう、検討と改善を日々進めています。
また、各データストアの容量は無限ではないため、データには保持期限を適切に設定し、古いデータの削除もバッチ処理で行なっています。
最後に
以上、マイクロアドで取り扱っているデータの加工・蓄積の流れを、ざっくりではありますがご紹介しました。
マイクロアドではこのようなデータ蓄積処理の開発・保守を担うデータエンジニアを募集しています。興味を持たれた方はこちらから是非ご応募下さい。
アドテク業界を進化させるビッグデータエンジニアWanted!! - 株式会社マイクロアドのWebエンジニアの求人 - Wantedly