マイクロアドではデータ基盤に Hive が使われています。 データ基盤について、以下の記事をご確認ください。
MicroAdのデータ基盤
より使いやすいデータ分析基盤にするために
この一年間、Hive を使う機会が増えましたのでクエリパフォーマンスを改善する為に Hive 設定を試行錯誤しましたので、その中からいくつか紹介します。
前提条件
- Hive 1.1.0-cdh5.14.0
まず基本ですが
SET;
を実行すると、以下が表示されます。
- システム変数
- 環境変数
- Hadoop 設定(ユーザーが定義した・デフォルトプロパティ)
- Hive 設定(ユーザーが定義した・デフォルトプロパティ)
set,define,hivevarで定義した Hive 変数
それでは、本題に入りましょう!
1. Vectorization
デフォルトでは、Hive はデータを1行ずつ処理します。このアプローチでは
* Hive はオブジェクトインスペクターを使う
* 抽象化レベルを有効
* 内部ループの実行における重要なメタデータの解釈
* レイジーデシリアライゼーションに大きく依存
が要因で、CPU が非効率的な処理となり時間がかかります。これを解決するため、Vectorization1 を有効にします。有効になると、Hive は1024行をまとめて処理し、プリミティブデータ型のベクトルとして表される列全体に対して操作を実行します。実行の内部ループはこれらのベクトルを非常に高速にスキャンするため、CPU の使用量と時間が大幅に削減されます。但し、CDH 5.x.y では Vectorization は ORC形式のテーブルのみの対応です。
SET hive.vectorized.execution.enabled = true;
2. Cost-based Optimization (CBO)
このコアコンポーネントは、クエリのさまざまなプランのコストを最適化および計算し、クエリ実行時間とリソース使用量を削減するため、Cost-based Optimization2 と呼ばれています。このコンポーネントは Apache Calcite3 を使用しているので、さまざまな最適化(例:クエリの書き換え)が適用されています。作成された各論理計画には、カラムの統計情報を用いてコストベースの番号が割り当てられます。
その後、Calcite は最小の番号持っているクエリプランを選択し、Hive によって物理演算子ツリーに変換され、最適化されてジョブに変換されてから実行されます。
CBO を有効にする際は、併せて以下の設定を true にするべきです。
// CBO を有効 SET hive.cbo.enable = true; // INSERT OVERWRITE クエリ時、自動的に統計を集める SET hive.stats.autogather = true; // count,max,min などのクエリにメタストアにある統計によっての結果を返す SET hive.compute.query.using.stats = true; // カラムまでの統計を取得 SET hive.stats.fetch.column.stats = true; // パーティションまでの統計を取得 SET hive.stats.fetch.partition.stats = true;
テーブルのカラム数やパーティション数が多い場合に、統計情報の作成の際にパフォーマンスが下がる可能性があります。
CBO が作成した統計を表示するには、以下のクエリを実行します。
// テーブル統計を表示 DESCRIBE EXTENDED $table_name; // テーブルカラム統計を表示 DESCRIBE FORMATTED $table_name.$column_name
CBO で最適化に必要な計算コストに伴うパフォーマンス劣化と CBO による最適化によるパフォーマンス向上のどちらが一番影響するかは、実行するクエリ及び Hadoop クラスタ構成にも影響するので、自身の環境で実験の上、CBO を利用して下さい。
3. 並列実行
Hive クエリは、順次実行されるいくつかのステージに変換されます。 場合によっては、これらのステージは互いに独立しているため、並行して実行できます。 これらの独立したステージを並行して実行すると、ジョブの合計実行時間が短縮されます。
以下の設定を有効にします。
SET hive.exec.parallel = true;
デフォルトのスレッド数は8ですが、以下で設定を変更できます。
SET hive.exec.parallel.thread.number = {スレッド数};
並列実行ではリソースの使用率が増加するため、使用率が高い場合、この機能を有効にしてもパフォーマンスは向上しません。
4. MapJoin
この小さな機能により、テーブルをメモリにロードでき、MapReduce ジョブの map フェーズで高速結合を実行できるため、 reducer は不要で、reduce フェーズはスキップされます。
有効にする時、
SET hive.auto.convert.join = true;
または、クエリで MAPJOIN() を使います。
SELECT /*+ MAPJOIN(p) */ * FROM cities c JOIN prefectures p ON (c.city_id = p.id);
MapJoin が有効な場合、Hive は、hive.mapjoin.smalltable.filesize の値よりも小さいテーブルに対して MapJoin を実行します。 デフォルトのファイルサイズは25MBですが、以下で設定が変更できます。
SET hive.mapjoin.smalltable.filesize = {ファイルサイズ(byte)};
MapJoin のメカニズムを以下に示します。
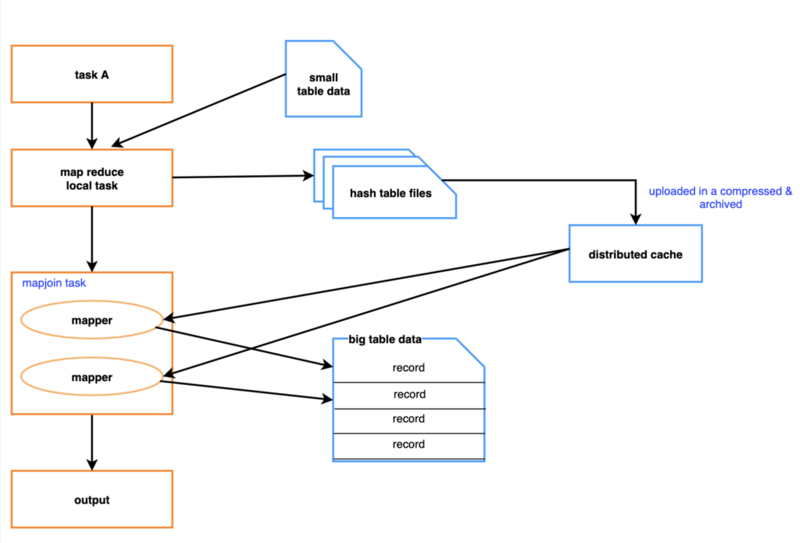
最初に、MapReduce ローカルタスクが作成されます。 HDFS から小さなテーブルのデータを読み取り、メモリ内のハッシュテーブルに保存してから、ハッシュテーブルファイルに保存します。 次に、ハッシュテーブルファイルは Hadoop Distributed Cache に移動されますが、元の結合 MapReduce タスクは実行を開始し、ファイルが各マッパーのローカルディスクに読み込まれます。
結合条件に関係するテーブルが3つ以上ある場合、Hive はこれらのテーブルのサイズが小さいという仮定で3つ以上の map 結合を生成します。
さらに、これらの n-1 テーブルのサイズが hive.auto.convert.join.noconditionaltask.sizeの値よりも小さい場合、これらの3つ以上の mapjoin を1つの mapjoin に結合できます。 これを使うためには、以下の設定が必要です。
SET hive.auto.convert.join.noconditionaltask = true;
もちろん、このルールのサイズ条件を変更できます。
SET hive.auto.convert.join.noconditionaltask.size = {サイズ};
これらは、Hive のパフォーマンスを最適化し、作業を高速化する、私のお気に入りの Hive 設定のほんの一部です。 Hiveのバージョンによっては、これらの設定が既に有効になっている場合があります。 もちろん、これらの設定の Hive バージョン、デフォルト値と他の設定を Hive Configuration Properties4 確認できます。
次回は、非常に興味深いトピックである Apache Calcite と Hive の統計について説明します。 最後に、クエリを調整する前に、まずベストプラクティスに従っていることを確認してください。
参考リンク
- docs.cloudera.com. (n.d.). Chapter 5. Using the Cost-Based Optimizer to Enhance Performance - Hortonworks Data Platform. [online] Available at: https://docs.cloudera.com/HDPDocuments/HDP2/HDP-2.6.5/bk_hive-performance-tuning/content/ch_cost-based-optimizer.html [Accessed 15 Mar. 2020].
- docs.cloudera.com. (2020). [online] Available at: https://docs.cloudera.com/documentation/enterprise/5-9-x/PDF/cloudera-hive.pdf [Accessed 15 Mar. 2020].
- Philip, N., (2020). Hive Performance - 10 Best Practices For Apache Hive | Qubole. [online] Available at: https://www.qubole.com/blog/hive-best-practices/ [Accessed 15 Mar. 2020].
- wyukawa's diary. (2020). Hiveのjoinの最適化 - Wyukawa's Diary. [online] Available at: https://wyukawa.hatenablog.com/entry/20110818/1313670105 [Accessed 15 Mar. 2020]
- cwiki.apache.org. (2020). Vectorized Query Execution - Apache Hive - Apache Software Foundation. [online] Available at: https://cwiki.apache.org/confluence/display/Hive/Vectorized+Query+Execution [Accessed 15 Mar. 2020].↩
- cwiki.apache.org. (2020). Cost-Based Optimization In Hive - Apache Hive - Apache Software Foundation. [online] Available at: https://cwiki.apache.org/confluence/display/Hive/Cost-based+optimization+in+Hive [Accessed 15 Mar. 2020].↩
- calcite.apache.org. (2020). Apache Calcite • Dynamic Data Management Framework. [online] Available at: https://calcite.apache.org/ [Accessed 15 Mar. 2020].↩
- cwiki.apache.org. (2020). Configuration Properties - Apache Hive - Apache Software Foundation. [online] Available at: https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties [Accessed 15 Mar. 2020].↩