はじめに
マイクロアドでサーバサイドエンジニアをしているタカギです。
今回はPythonアプリから参照するデータをMySQLからBigQuery1へ切り替えた話になります。
背景
マイクロアドでは様々なデータを扱っています。
広告配信で発生するログはCDH2に蓄積および集計され、その後MySQL、Redis、分析用CDHクラスタ、BigQueryなど別のデータベースに転送され、分析や請求など様々な用途に利用されます。
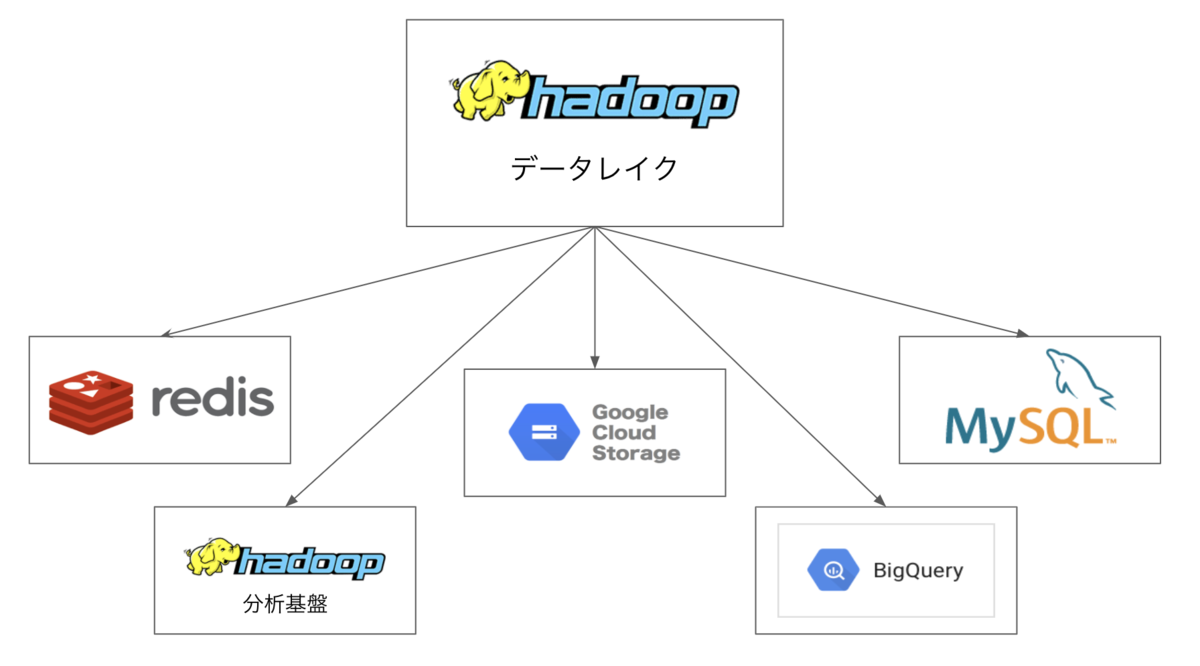
その中の1つに、1日で1500万件弱のレコード数を扱うMySQLのテーブルがあり、とあるapiからの参照クエリのレスポンス速度が問題になっていました。
その対応策として、データソースをMySQLからBigQueryへ切り替えることになりました。
これまでもBigQueryへデータ転送することはありましたが、アプリケーションからBigQueryを参照するという点で新しい試みでした。
やったこと
やるべきことはシンプルでした。
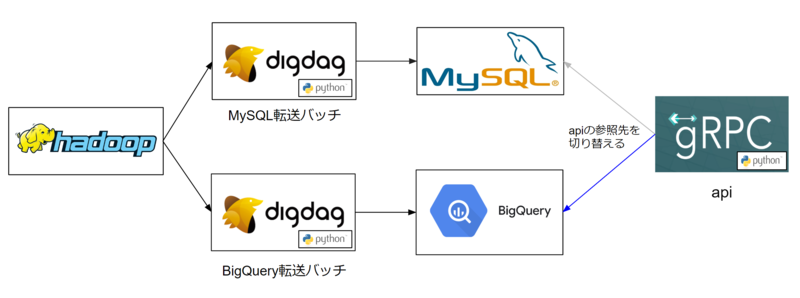
- DigdagバッチでCDHからBigQueryへのデータ転送とテーブルロードを行うバッチを新規作成
- apiから参照するデータをMySQLからBigQueryへ変更
困った点とその対応
テーブルロード時のlocation指定
データ転送先となるGCPのlocationはデフォルトのusではなくasia-northeast1(東京)にするという要件がありました。
しかしながら、Digdagのbq_loadoperator3ではlocationを指定する設定項目が現状存在しません。
そのため、GCPのPython用ライブラリgoogle-cloud-bigquery4を使用して、locationを指定しつつテーブルロードを行えるようにしました。
この件についてはマイクロアド内で実績があったため、比較的スムーズに進みました。
BigQueryの制限問題①
BigQueryでは、相関サブクエリを使用できないようです。5
Correlated subqueries that reference other tables are not supported unless they can be de-correlated, such as by transforming them into an efficient JOIN.
修正前のクエリでは相関サブクエリを使用していたため、相関サブクエリを使用せずに既存のクエリと同じ結果になるような修正が必要でした。
こちらは、WITH句による一時テーブルへの切り出しと、IN句やJOINなどでクエリを書き換えることで対応しました。
修正前後のクエリのサンプルを記載します。
- 修正前のクエリ
SELECT COUNT(DISTINCT id) AS count FROM test_db.test_table WHERE target_date = '2022-05-01' AND id IN ( SELECT id FROM test_db.test_table t1 WHERE target_date = '2022-05-01' AND EXISTS ( SELECT id FROM test_db.test_table t2 WHERE target_date = '2022-05-01' AND aaa = 'xxx' AND t1.id = t2.id ) )
- 修正後のクエリ
WITH sub1 AS ( SELECT id FROM test_db.test_table WHERE DATE(_PARTITIONTIME) = '2022-05-01' AND id IN ( SELECT id FROM test_db.test_table WHERE DATE(_PARTITIONTIME) = '2022-05-01' AND aaa = 'xxx' ) ) SELECT COUNT(DISTINCT id) AS count FROM test_db.test_table WHERE DATE(_PARTITIONTIME) = '2022-05-01' AND id IN ( SELECT id FROM sub1 )
BigQueryの制限問題②
BigQueryでは、クエリの大きさや複雑さが一定値を超えるとクエリの実行に失敗してしまうようです。6
Resources exceeded during query execution: Not enough resources for query planning - too many subqueries or query is too complex.
回避方法としては、下記のような方法がありそうです。
WITH句で表現している一時テーブルを、一度明示的に中間テーブルとして保存する
擬似的に1クエリ内で中間テーブルを作る
この問題にはまだ対応できていません。
そのため、エラーとなるケースではまだ移行が完了していない状況ですが、apiは複数箇所から参照されており、エラーとなるケースが発生しない一部の機能では移行が進んでいます。
改修後
データ転送
GCPへのデータ転送とテーブルロードの処理は、処理時間5分前後と、非常に良いパフォーマンスとなっています。
apiのレスポンス
移行前に20分前後かかっていた処理が30秒に短縮されるなど、劇的な改善が見られました。
サンプルコード
BigQuery関連のサンプルコードを記載します。
バッチ側(GCSにデータを転送して、BigQueryにテーブルロードする)
requirements.txt
google-cloud-bigquery==2.34.2 gcsfs==2022.3.0
xxx.py
import gcsfs from google.cloud import bigquery from google.oauth2 import service_account import subprocess def push_google_cloud_storage_impl(target_date: str, gcp_credential_file_path: str) -> None: """ Google Cloud Storageへdistcpを行う :param target_date: :gcp_credential_file_path: :return: """ source_path = "hdfs://source-cdh-host/test_db/test_table" destination_path = "gs://destination-gcs/test_db/test_table" auth_option = f"-Dfs.gs.auth.service.account.json.keyfile={gcp_credential_file_path}" command = '/usr/bin/hadoop' \ ' distcp' \ f' {auth_option}' \ ' -Dmapreduce.framework.name=local' \ ' -m 12' \ ' -bandwidth 100' \ ' -overwrite -delete' \ f' {source_path}/dt={target_date}' \ f' {destination_path}/dt={target_date}' subprocess.run( command, shell=True, check=True, encoding='UTF-8', universal_newlines=True) def bq_load_impl(target_date: str, gcp_credential_file_path: str) -> None: """ BigQueryへのインポートを行う :param target_date: :gcp_credential_file_path: :return: """ source_path = f'gs://destination-gcs/test_db/test_table/dt={target_date}/*' target_bigquery_table = f'test_db.test_table${target_date}' credentials = service_account.Credentials.from_service_account_file( gcp_credential_file_path, scopes=["https://www.googleapis.com/auth/cloud-platform"], ) client = bigquery.client.Client(credentials=credentials, location='asia-northeast1', project=credentials.project_id) # パーティションの有効期限を7日に設定 # 604800000 = 7*24*60*60*1000 job_config = bigquery.LoadJobConfig( source_format=bigquery.SourceFormat.PARQUET, write_disposition=bigquery.WriteDisposition.WRITE_TRUNCATE, time_partitioning=bigquery.TimePartitioning(type_="DAY", expiration_ms=604800000) ) client.load_table_from_uri( source_path, target_bigquery_table, job_config=job_config).result()
api側(BigQueryのテーブルから件数を取得する)
requirements.txt
google-cloud-bigquery==2.34.2
xxx.py
import textwrap from google.cloud import bigquery from google.oauth2 import service_account class BigqueryTestTableDao: """ BigQueryのデータ操作オブジェクト """ def __init__(self, gcp_credential_file_path: str) -> None: """ イニシャライザ :gcp_credential_file_path: :return: """ credentials = service_account.Credentials.from_service_account_file( gcp_credential_file_path, scopes=["https://www.googleapis.com/auth/cloud-platform"], ) client = bigquery.client.Client(credentials=credentials, project=credentials.project_id) self.client = client def get_count(self, target_date: str) -> int: """ BigQueryのtest_db.test_tableの対象日の件数を取得する :param target_date: yyyy-mm-dd :return: test_db.test_tableの対象日の件数 """ query = textwrap.dedent(f""" SELECT COUNT(DISTINCT id) AS cnt FROM test_db.test_table WHERE DATE(_PARTITIONTIME) = @target_date """).strip() job_config = bigquery.QueryJobConfig(query_parameters=[ bigquery.ScalarQueryParameter("target_date", "STRING", target_date) ]) print('execute query:', query) print('param:', job_config.query_parameters) query_job = self.client.query(query, job_config=job_config) results = query_job.result() record = next(iter(results)) return record.cnt
今後の課題
BigQueryの制限問題を解消するべく、対応が必要です。
現状問題となっているBigQueryの制限と上手く付き合う為に、TEMP TABLE7を使用した方式の検証はある程度進んでおり、解決できる見込みです。
TEMP TABLEを使用する方法として、クエリスクリプト8を検討していますが、そのサンプルを記載します。
xxx.py
# 検証中 # client生成は省略 sql_script = """ CREATE TEMP TABLE sub1 (id String); CREATE TEMP TABLE sub2 (id String); INSERT INTO sub1 SELECT id FROM test_db.test_table WHERE DATE(_PARTITIONTIME) = '2022-04-12' AND xx = xx ; INSERT INTO sub2 SELECT id FROM test_db.test_table WHERE DATE(_PARTITIONTIME) = '2022-04-12' AND xx = xx ; SELECT COUNT(DISTINCT id) AS cnt FROM test_db.test_table WHERE DATE(_PARTITIONTIME) = '2022-04-12' AND ( ( id IN ( SELECT id FROM sub1 ) ) OR ( id IN ( SELECT id FROM sub2 ) ) ) ; """ parent_job = client.query(sql_script) # Wait for the whole script to finish. rows_iterable = parent_job.result() print("Script created {} child jobs.".format(parent_job.num_child_jobs)) # Fetch jobs created by the SQL script. child_jobs_iterable = client.list_jobs(parent_job=parent_job) for child_job in child_jobs_iterable: child_rows = list(child_job.result()) print(len(child_rows))
まとめ
データソースをBigQueryへ切り替えることで、データ転送時間およびapiのレスポンス速度が大幅に改善しました。
BigQueryならではのクエリの制約、コスト的な問題、など難しい点はあるとしても、BigQueryはデータソースとして検討するべきサービスの1つになるのではないでしょうか。
補足
モジュール競合
apiからBigQueryを参照するにあたってapi側でもgoogle-cloud-bigqueryを使用した際、名前空間protoでモジュール競合という現象が起きてしまいました。
要約すると下記のような状況でした。
google-cloud-bigqueryはproto-plus9というライブラリに依存があり、同時にインストールされるが、このライブラリはprotoモジュールを持っている- apiはgRPCサーバとして構築しており、インターフェースを記述したprotoファイルから自動生成するファイルを
protoディレクトリ配下に出力していた
自動生成ファイルの出力先を変更することで対応しましたが、この問題の調査には思ったより時間をとられてしまいました。
リンクなど
-
https://docs.cloudera.com/documentation/enterprise/6/6.3/topics/cdh_intro.html↩
-
https://cloud.google.com/bigquery/docs/reference/standard-sql/subqueries?hl=ja#correlated_subquery_concepts↩
-
https://techblog.gmo-ap.jp/2020/12/10/bigquery_trouble_shoot/↩
-
https://cloud.google.com/bigquery/docs/multi-statement-queries#temporary_tables↩
-
https://cloud.google.com/bigquery/docs/samples/bigquery-query-script?hl=ja#bigquery_query_script-python↩