はじめに
マイクロアドでサーバサイドエンジニアをしているタカギです。
この記事は、JSON形式の生ログをParquet形式へ変換する際に発生する膨大なI/Oを削減した話になります。
背景
マイクロアドではデータ基盤移行プロジェクトを進めてきました。
様々な検証が進められるなか、懸念点として浮上した話が、ストレージI/O問題でした。
当時のデータ基盤の処理をそのまま移行した場合、I/O性能が処理量に追い付かない可能性がありました。
しかしながら、新データ基盤ではS3互換ストレージ(非常に高価)を使用しており、増設は可能な限り避けたい状況でした。
ということで、いかにしてI/Oを減らすことができるかについて、各方面から検討が行われました。
その結果、以下の処理を改善することで高いI/O削減効果が見込めそう、ということになりました。
- JSON形式の生ログをKafkaからストレージに転送する処理
- ストレージから生ログを読み込んでParquet形式へ変換する処理
マイクロアドのデータ基盤について
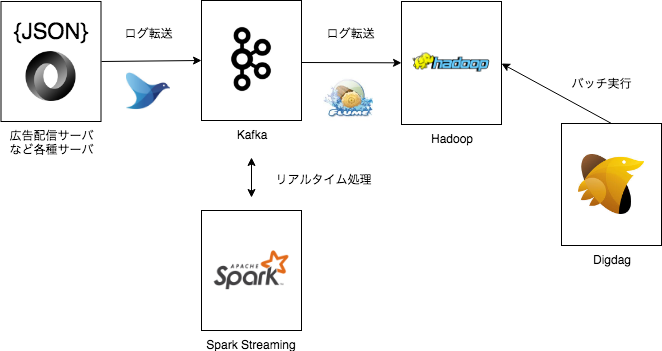
過去の記事で触れているように、広告配信ログ・アクセスログは一旦Kafkaに集約され、その後FlumeでHadoopクラスタへと転送された後、Hadoop内で加工や集計などの処理が行われるという仕組みでした。
マイクロアドのログ蓄積の流れ - MicroAd Developers Blog
新データ基盤も同じような構成で基盤を構築しており、FlumeでログをS3互換ストレージに転送していました。
改善前/改善後のイメージ
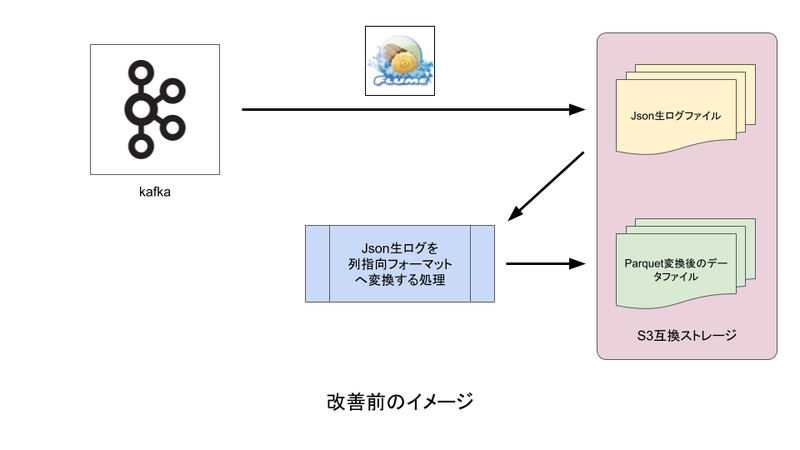
改善前
- Flume:Kafkaからストレージへ生ログ転送
- Parquet形式への変換処理:生ログをストレージから読み込み、Parquet形式に変換したデータをストレージに出力
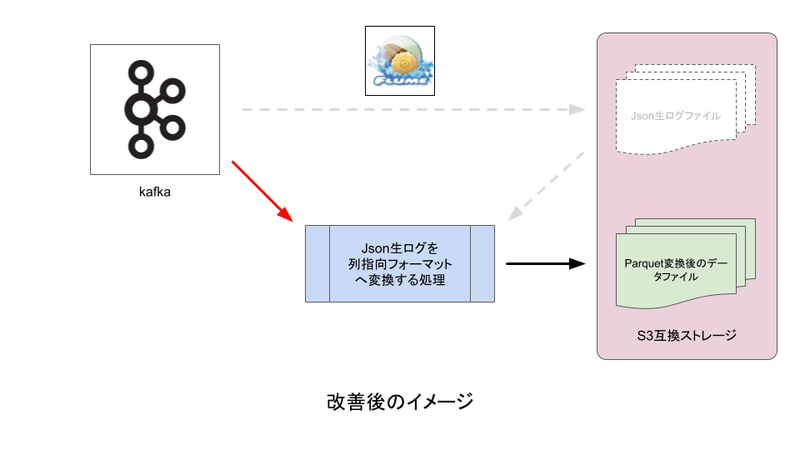
改善後
- Parquet形式への変換処理:生ログをKafkaから読み込み、Parquet形式に変換したデータをストレージに出力
なぜI/O削減効果が高いのか
- マイクロアドで扱うシステムでは日々膨大なデータが発生しており、特にRTBと呼ばれる入札処理、広告配信処理で発生するログのデータ量が非常に大きい
- それらが生ログの状態でストレージに転送される
- 転送された生ログがParquet形式への変換処理に読み込まれる
上記のように、この大きなログの読み書きをいくつかのプロセスに分けて行うことで、非常に大きなI/Oが発生するためです。
生ログの状態でストレージに転送するステップを省略することで、大きなI/O削減に繋がりました。
Parquet形式への変換処理の課題
ストレージI/Oの問題とは別の話ではありますが、Parquet形式への変換処理には、JSON形式として不正な異常ログが発生した場合にバッチ処理が失敗してしまうという課題がありました。
この問題が発生した場合、高い緊急度で異常なログを取り除く運用作業が必要となり、発生頻度は低いものの、無視できない運用負荷となっていました。
新データ基盤ではApache Sparkを用いてデータを処理しますが、Apache Sparkの機能によりこの課題も解決できそうでした。
実装サンプル
PySparkの処理で、Kafkaからログを読み込んで、正常データと異常データに分類する処理の一部を記載しました。
※Pythonのバージョンは3.11、PySparkのバージョンは3.5.5 をそれぞれ使用しています。
""" JSON生ログをParquet形式へ変換する処理 """ from decimal import Decimal from pyspark.sql import DataFrame, SparkSession from pyspark.sql import functions as F from pyspark.sql.types import StructType, StructField, TimestampType, LongType, StringType # from_json()で変換された値(struct型)のカラム名 JSON_STRUCT_COLUMN_NAME = 'json_struct' # 不正フォーマットのJSONログを保持するカラム CORRUPT_RECORD_COLUMN_NAME = 'corrupt_record' KAFKA_JSON_SCHEMA = StructType( [ StructField('time', TimestampType()), StructField('id', LongType()), StructField('host', StringType()) ] ) def read() -> DataFrame: """ Kafkaから生ログを読み込む """ spark_connect_url = "sc://test-k8s:31502" bootstrap_servers = [ 'kafka-host01:9092', 'kafka-host02:9092', 'kafka-host03:9092' ] kafka_topic = 'test-topic' # SparkSession spark = SparkSession.builder.remote(spark_connect_url).getOrCreate() # 異常な日時フォーマットの文字列をパースした際に例外を発生させないようにする spark.conf.set('spark.sql.legacy.timeParserPolicy', 'CORRECTED') # Kafkaからログを読み込む kafka_df = spark.read.format('kafka') \ .option('kafka.bootstrap.servers', ','.join(bootstrap_servers)) \ .option('subscribe', kafka_topic) \ .load() return kafka_df def parse(kafka_df: DataFrame) -> DataFrame: """ JSONログをparseする """ # JSONをparseする際に異常なログの内容を保持しておく設定 options = { 'mode': 'PERMISSIVE', 'columnNameOfCorruptRecord': CORRUPT_RECORD_COLUMN_NAME } # schemaにはcolumnNameOfCorruptRecordに設定したカラムを追加しておく # KAFKA_JSON_SCHEMAに変更を加えないためにdeepcopyする schema_with_corrupt = copy.deepcopy(KAFKA_JSON_SCHEMA) schema_with_corrupt.add(StructField(CORRUPT_RECORD_COLUMN_NAME, StringType())) # JSONをparseする parsed_df = kafka_df. \ select(F.col('value').cast('string').alias('str_value')) \ .select( F.from_json(F.col('str_value'), schema_with_corrupt, options) \ .alias(JSON_STRUCT_COLUMN_NAME) ) return parsed_df def filter(parsed_df: DataFrame) -> [DataFrame, DataFrame]: """ 異常なログと正常なログに分ける """ # 異常なログの内容が設定されるカラム json_corrupt_record_key = \ f'{JSON_STRUCT_COLUMN_NAME}.{CORRUPT_RECORD_COLUMN_NAME}' # 正常なレコード valid_df = parsed_df.where(F.col(json_corrupt_record_key).isNull()) # 異常なレコード corrupt_df = parsed_df \ .where(F.col(json_corrupt_record_key).isNotNull()) \ .select(F.col(json_corrupt_record_key)) return valid_df, corrupt_df # Kafkaから生ログを読み込む kafka_df = read() # JSONログをparseする parsed_df = parse(kafka_df) parsed_df.cache() # 同じ処理の繰り返しを防ぐためにキャッシュする # 異常なログと正常なログに分ける valid_df, corrupt_df = filter(parsed_df) corrupt_df.cache() # 同じ処理の繰り返しを防ぐためにキャッシュする # 登録処理(省略) # convert_to_parquet(valid_df) # 全体の件数 kafka_count = int(parsed_df.count()) # 異常なログの件数 corrupt_count = int(corrupt_df.count()) # 異常なログの割合 corrupt_rate = \ (Decimal(corrupt_count) / Decimal(kafka_count)) if kafka_count > 0 else Decimal('0') # 異常なログが存在した場合の処理 if corrupt_count: # 異常なログの内容を出力(省略) # output_to_log(corrupt_df) if corrupt_rate > 0.0001: # 異常なログの割合が閾値を超えた場合 # アラートするなど(省略) # send_alert(corrupt_rate) pass
まとめ
生ログをKafkaから直接読み込むことで、I/O(ストレージへのログ転送、ストレージからのログ読み込み)を大幅に削減することができ、副次的な効果として転送ログ分のストレージ容量削減にも繋がりました。
また、異常なログが発生した場合に、運用作業することなくデータを除外し、異常率による挙動の制御もできるようになりました。
この記事が誰かの役に立てば幸いです。