はじめに
機械学習エンジニアの大庭です。普段はマイクロアドが提供する広告配信プラットフォーム UNIVERSE Ads に接続する機械学習 API の研究開発をしています。
マイクロアドでは、機械学習モデルの学習側との連携が容易なこととメンテナンス性を重視して Python で機械学習 API を実装しています。Python は使いやすい反面、基本文法は速いとは言えない言語です。そのため、実行時間制約の厳しい Real Time Bidding (RTB) のなかで使うには高速化を意識しておく必要があります。今回は様々ある Python の高速化手法の理解と整理のため記事にしました。
個人的にですが、Python の高速化は以下の手順で行っていくのがいいと思っています。この記事では、この手順毎に便利なツールやライブラリをまとめました。
- ボトルネックの特定
- 計算量(オーダー)を減らす
- コードを部分的にコンパイルする
- 並行並列処理
- PyPy に処理系を変える
1. ボトルネックの特定
プログラムの実行時間の大部分は繰り返し呼び出される処理が占めています。そのため、高速化を行う際はまずコードのどの部分がボトルネックになっているのかを調べ、優先度をつけて改良していくことが重要です。はじめに、Python のボトルネックの特定に便利なプロファイリングツールについて紹介します。
1-1. cProfile
cProfile は Python 標準のプロファイラです。使用方法として、スクリプト起動時に呼び出す方法と、プログラム内でモジュールとして使う方法の二通りがあり、特に以下のスクリプト起動時に呼び出す方法がコードを書き加える必要がなく便利です。
python -m cProfile [-o output_file] [-s sort_order] hoge.py
実行すると関数毎に以下のような情報を表示してくれます。
- 関数が呼ばれた回数
- 1回毎の実行速度
- トータルの実行速度
$ python -m cProfile hoge.py
123 function calls in 0.718 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.001 0.001 0.718 0.718 hoge.py:1(<module>)
10 0.000 0.000 0.116 0.012 hoge.py:3(func_a)
20 0.000 0.000 0.246 0.012 hoge.py:6(func_b)
30 0.000 0.000 0.355 0.012 hoge.py:9(func_c)
1 0.000 0.000 0.718 0.718 {built-in method builtins.exec}
60 0.717 0.012 0.717 0.012 {built-in method time.sleep}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
さらに細かく行毎でプロファイリングを行いたい場合は、同じく標準ライブラリの profile が使用できます。
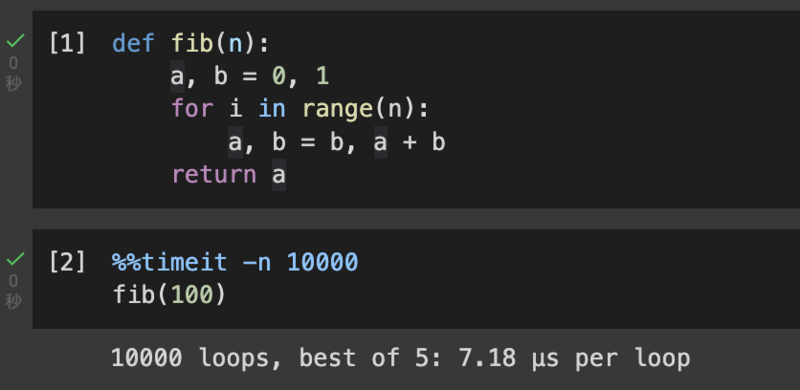
1-2. Jupyter 上での %%timeit
%%timeit は Jupyter のマジックコマンドです。以下のようにコードセルの先頭につけるだけでコードセルの1回あたりの実行時間に応じて回数を調整しながら速度を計測してくれます。
個人的に、ふとコードの実行時間を見たくなったきに Google Colaboratory を立ち上げて %%timeit で実行時間を見るというのをよくやります。
2. 計算量(オーダー)を減らす
アルゴリズムとデータ構造を再検討し計算量を最適化することは高速化において最も重要です。特に Python では dict や set、collections、numpy といったデータ型を手軽に利用でき、適当なものを選ぶだけで実行速度が大きく改善する場合もあります。高速化を行う際は、計算量を減らせる部分がないかを入念に確認しましょう。
データ型で速度が変わる典型例として list と set で「要素が配列に含まれるかの判定処理」を比較した例を紹介します。
L = list(range(10000)) S = set(range(10000)) v = 5000
%%timeit -n 10000 v in L # 10000 loops, best of 5: 71 µs per loop
%%timeit -n 10000 v in S # 10000 loops, best of 5: 129 ns per loop
3. コードを部分的にコンパイルする
3-1. Numba
Numba とは Just in Time (JIT) コンパイラという仕組みを利用した高速化ライブラリです。デコレータをつけた関数を初回実行時にコンパイルし、バイドコードに変換しておくことで以降の呼び出しを高速してくれます。
以下はフィボナッチ数列を求める関数に Numba を使用した例です。
import numba @numba.jit def fib(n): a, b = 0, 1 for i in range(n): a, b = b, a + b return a
%%timeit -n 10000 fib(100) # Numba なし: 10000 loops, best of 5: 7.48 µs per loop # Numba あり: 10000 loops, best of 5: 308 ns per loop
デコレータをつけただけで、20倍近く高速化してくれています。
Numba には最適化が行われ高速化の効果が大きい no python モードと効果の少ない object モードという2つのコンパイル形式があります。 それらは関数が最適化可能な処理のみで構成されているかで自動的に切り替わります。 なので、Numba を利用する際は以下のような「最適化に対応していない処理」を関数に含まないよう注意が必要です。
- dict
- set
- pandas
@numba.jit の代わりに @numba.njit を使うと object モードでエラーを出すようになります。
3-2. Cython
Cythonを使えば Python ライクな言語でソースコードを書くだけで、C 言語で書いたものと同等に高速なモジュールを生成できます。Cython でモジュールを作成するには、Cython を .pyx ファイルに書く方法、Python で書いたコードにデコレータをつけていくpure Python モードなど複数のインターフェースが存在します。以下では個人的に最も触りやすいと思っている Jupyter からの利用方法について紹介します。
Jupyter では load_ext Cython で Cython 用拡張機能を読み込み、セルの先頭に %%cython をつけるだけで Cython を書くことができます。
%load_ext Cython
%%cython cpdef int fib(int n): cdef int a = 0 cdef int b = 1 for i in range(n): a, b = b, a + b return a
%%timeit -n 10000 fib(100) # Python: 10000 loops, best of 5: 7.48 µs per loop # Cython: 10000 loops, best of 5: 135 ns per loop
書き換えたコードはわずかですが Numba よりさらに上の 50 倍以上高速化されています。
上の例では型をしっかり書いていますが、Cython では型推論が働くのである程度省略できます。
%%cython -a オブションを使用すると処理に時間が掛かっている行を黄色で表示してくれるので、そういった行から徐々に Cython に書き換えるのがおすすめです。

4. 並行並列処理
Python の並行、並列処理を適切に利用するには Global Interpreter Lock(GIL) を理解しておく必要があります。GIL とは CPython にあるスレッドの排他ロックの仕組みで、CPUを使用できるスレッドは1プロセスで1つのみという制約です。この機能はスレッドセーフが保証されていない C 言語のライブラリを利用するために導入されています。
GIL を削除しようという試みも行われていますが、現行の Python 3.11 では導入されていないのでもうしばらくは GIL とうまく付き合っていく必要があります。以下の記事がまとまっていてわかりやすいです。
Python のマルチスレッドは GIL の制約により CPU バウンドなタスクを高速化できません。しかし ファイルの読み込みやAPIへのアクセスのような I/O バウンドなタスクは待機中に他の処理に CPU を利用できるため効果があります。
一方でマルチプロセスではプロセスを増やすことでCPUを使用できるスレッドも増えるので CPU バウンドのタスクに効果的です。しかしプロセスを立ち上げることによるオーバーヘッドはそれなりにあるため、I/O バウンドなタスクには最適とは言い難いです。またシームレスに変数を共有できるスレッドと比べると、プロセス間の変数の共有は制限とコストがそれなりにかかります。
| CPU バウンド | I/O バウンド | メモリ共有 | |
|---|---|---|---|
| マルチスレッド | X | O | O |
| マルチプロセス | O | Δ | Δ |
Python ではボトルネックの性質によって並行並列処理を使い分けることが重要になってきます。
4-1. マルチスレッド(並行処理)
繰り返しになりますが、Python のマルチスレッドは GIL によりCPUバウンドなタスクの高速化は見込めません。I/O に時間がかかっている場合に利用していきましょう。
Python スレッドAPIとして3種類の標準ライブラリを提供しています。
以下では一番新しく個人的に使い勝手がいいと思っている concurrent.futures のサンプルコードを紹介します。
import time from concurrent.futures import ThreadPoolExecutor def io_bound_task(): time.sleep(0.01)
%%timeit -n 100 for i in range(4): io_bound_task() # 100 loops, best of 5: 40.7 ms per loop
%%timeit -n 100 with ThreadPoolExecutor(max_workers=4) as e: for i in range(4): e.submit(io_bound_task) # 100 loops, best of 5: 11 ms per loop
time.sleep のようなCPUを利用しない処理がスレッドの数だけ高速化されています。
4-2. マルチプロセス(並列処理)
Python のマルチプロセスはマルチスレッドで高速化できない CPU バウンドタスクに有効です。マルチプロセスでも標準ライブラリが複数提供されています。
以下ではマルチスレッドと同様に concurrent.futures のサンプルコードを紹介します。
import time from concurrent.futures import ProcessPoolExecutor def cpu_bound_task(): sum(range(1_000_000))
%%timeit -n 100 for i in range(4): cpu_bound_task() # 100 loops, best of 5: 87 ms per loop
%%timeit -n 100 with ProcessPoolExecutor(max_workers=4) as e: for i in range(4): e.submit(cpu_bound_task) # 100 loops, best of 5: 52.1 ms per loop
プロセスを立ち上げるコストにより I/O バウンドタスクでのマルチスレッドほどは高速化できませんが、それでもある程度は早くなっています。使う際はCPUのコア数に合わせてプロセス数を調整すればそれなりに高速化できそうです。
ちなみに同様の処理をマルチスレッドで行なった場合は、ほぼシングルスレッドにオーバーヘッドが乗っただけの速度になってしまいます。
%%timeit -n 100 with ThreadPoolExecutor(max_workers=4) as e: for i in range(4): e.submit(cpu_bound_task) # 100 loops, best of 5: 90.5 ms per loop
5. PyPy に処理系を変える
Python の処理系にはPython3 標準の CPython や JVM で動作する Jython、C# で実装された IronPython などいくつか種類があります。なかでも PyPy は CPython に JIT コンパイラ機能を持たせることで高速化した処理系です。Python のコードを書き換えることなく高速化できることから、競技プログラミングで重宝されています。
def fib(n): a, b = 0, 1 for i in range(n): a, b = b, a + b return a
%%timeit fib(100) # CPython: 10000 loops, best of 5: 7.48 µs per loop # PyPy : 10000 loops, best of 5: 635 ns per loop
PyPy は Numba や Cython 以上にコードに手を加えることなく高速化できますが、以下のような明確な欠点も存在します。
- C 言語で書かれた一部のライブラリが利用できない
- コードをキャッシュする分メモリ消費量が多くなる
これらが、気にならない場合のみ導入することをおすすめします。
おわりに
この記事では、Python 高速化に関するツールやライブラリとして以下を紹介しました。
- ボトルネックの特定
- cProfile
- Jupyter 上での %%timeit
- 計算量(オーダー)を減らす
- コードを部分的にコンパイルする
- Numba
- Cython
- 並行並列処理
- マルチスレッド(並行処理)
- マルチプロセス(並列処理)
- PyPy に処理系を変える
Python の言語としての特徴を理解し、今日紹介したようなツールを適切に使いわけていければ、Python は遅い言語ではなくなると思ってます。 この記事が皆さんのストレスフリーな Python ライフの助けになれば幸いです!
参考
この記事を書くにあたり以下の記事を参考にさせていただきました。
- Pythonプログラムが遅い!高速化したい!そんな時は... - Qiita
- 深入りしないCython入門 - Qiita
- 深入りしないCython入門 -2- - Qiita
- Pythonのthreadingとmultiprocessingを完全理解 - Qiita
- python マルチスレッド マルチプロセス - Qiita
機械学習エンジニア絶賛採用中
マイクロアドでは、問題設定からサーベイ、開発・運用まで裁量を持って挑戦したい機械学習エンジニアを募集しています! また、機械学習エンジニアだけでなく、サーバサイド、フロントエンド、インフラエンジニアなどの職種も募集しています! 気になった方は、以下の採用サイトからご応募ください!