はじめに
マイクロアドでインフラエンジニアをしている柏木です。
マイクロアドでは広告配信に高速なKVSであるRedisを使用しています。
Redisはシングルスレッドでの高速性、安定性を売りにしていました。しかし6.0でマルチスレッド機能であるThreded I/Oが追加されました。
広告配信で多用している、Redisを高速化できるのであれば積極的に導入したいので検証を行いました。
- はじめに
- Threded I/Oとは
- 今回の検証結果
- 前提条件
- 検証1:I/Oスレッドを増やすと処理できるリクエスト量は増えるか
- 検証2: io-threads-do-readsの有無
- 検証3 Hyper-Threading(HT)の有効、無効によるパフォーマンス変化
- 今回の検証結果(再掲)
- 終わりに
Threded I/Oとは
Threded I/Oは今までシングルスレッドで処理を行っていたコマンドを一部並列化し、高速化する機能です。手軽に、性能を2倍にできるとされています。
io-threadsとio-threads-do-readsを設定できます。
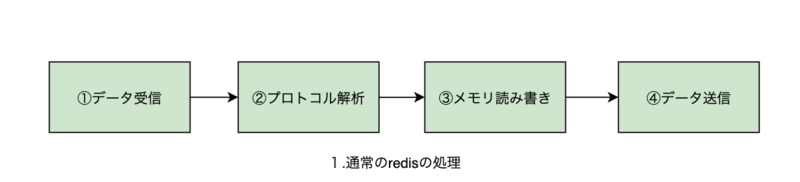
シングルスレッドでのRedisの処理
Redisのコマンドを処理する工程は、主に4つに分けられます。
マルチスレッドでのRedisの処理
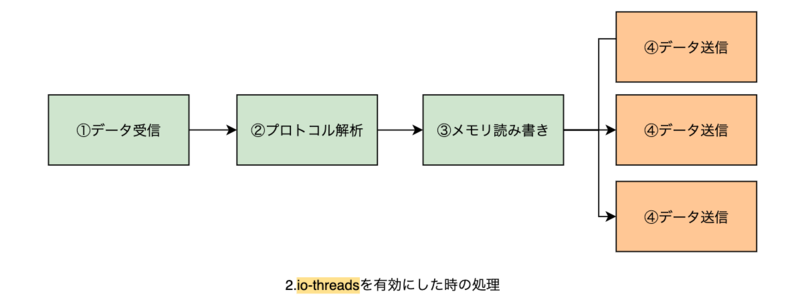
io-threads
io-threadsを有効(2以上)にすると、④データ送信 をスレッドを使い並列化します。ネットワーク・メモリアクセスの待ち時間を減らし、効率改善が見込めます。
以下の特徴があります
- メモリへの読み書きはシングルスレッドで行われているので原子性は保証されている
- redis.confのコメントによると、io-threadsの指定を8スレッド以上に設定しても効果が薄い
- ホストのCPU物理コアのうち、1〜2コアはio-threadsで使用しないことが推奨されている(例: 4物理コア8スレッドのCPUの場合は3スレッド以下を指定)
- 最大128スレッドまで指定できる
io-threads-do-reads + io-threads
io-threads-do-readsを有効にすると、さらに①データの読み込み・②プロトコル解析をスレッドで実行します。
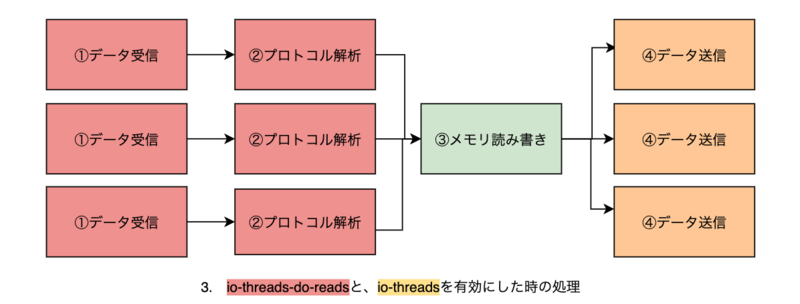
redis.confのコメントによると、読み込みをスレッド化してもあまり変わらないとされています。受信したデータの読み込みは元々epollなどを利用し並行になっているため、と考えます。
検証環境
以下の環境で検証します。
Redis version: 6.2.1 (2021/03/12時点でのstableの最新を使用)
CPU: Intel(R) Xeon(R) CPU E5-2670 V3 @ 2.30GHz(12コア24スレッド)×2
Hyper-Threading(HT): disable
HTは1物理コアを2つに見せかける機能です。有効の場合、OSが1つの物理コアに2つのスレッドを割り当てる時があると考えます。
スレッドの割当によって、パフォーマンスが変化することを防ぐため無効にします。
メモリ: 256GB
OS: CentOS 7.8
OSの追加設定
numactlをインストール(詳細は後述)
rpm -ivh numactl-2.0.12-5.el7.x86_64.rpm
下記の設定を適用
#ターボブーストによる性能の変化を避ける echo 1 > /sys/devices/system/cpu/intel_pstate/no_turbo #CPUクロックが抑制されて性能が変化するのを避ける /bin/cpupower frequency-set -g performance #セキュリティルールによる性能の低下を避ける setenfroce disable #Redisでほぼ必須の設定3つ echo madvise > /sys/kernel/mm/transparent_hugepage/enabled sysctl -w vm.overcommit_memory=1 sysctl -w net.core.somaxconn=65535
今回の検証結果
本文が長くなったので、先に結果を記述します。今回の検証では以下のことがわかりました。
io-threadsを有効にしたときは、性能は最大180%程度上昇するio-threadsとio-threads-do-readsを有効にしたときは、性能は最大300%程度向上するio-threadsに指定する値によっては性能低下が発生するので、物理コア数を目安に余裕を持った値を設定する必要がある- 12物理コアでは、9コアをredis-serverに割り当てるまで、MSETを除くコマンドで性能は上昇した
前提条件
それでは、今回の検証をするにあたって設定した条件を記述します。
指標の取得方法について
性能指標はRedisに標準で含まれているredis-benchmarkのrps(requests per second)とします。 redis.io
loopbackアドレスを利用した検証
ネットワーク越しでの検証を行った際、ネットワークスイッチなどの影響により再現性のある検証を行うことが出来なかったため1台のサーバで検証を行います。
loopbackアドレスに対して検証した場合も、ネットワーク経由のときと同じようにTCPパケット生成・ルーティングなどの通信処理が、サーバ・クライアント間に発生します。そのため、通信を高速化するThreaded I/Oの影響は確認できます。
実行CPUの指定
numactlを利用し、CPU0でredis-server、CPU1でredis-cliを実行するように指定します。
当検証ではCPUを2機搭載したサーバを使用しています。CPUが複数搭載されているサーバは、NUMAというアーキテクチャで動作しています。NUMAを利用している時、メモリへのアクセス速度が低下する事があります。
NUMAでは複数のCPUがメモリを分担して管理しています。プログラムを実行しているCPUが管理していない、遠いメモリへアクセスするとき、メモリへのアクセス速度が低下します。プログラムを実行するCPUが決まっていないとメモリへの距離が変わり、アクセス速度が変動するので、再現性がなくなります。
そこで、以下の様にサーバとクライアントに割り当てるCPUを固定することで、メモリへのアクセスの距離を固定します。
- クライアント⇄メインスレッド・I/Oスレッド(別CPU間の通信)
- メインスレッド⇄I/Oスレッド(同一CPU間の通信)
NUMAに関するこれ以上の説明は割愛します。他のドキュメントを見てもらえればと思います。
Redisの起動コマンド
numactl --cpunodebind=0 ./redis-server /root/redis/redis.conf &
Redisのconfigについて
デフォルトのconfigから、saveを無効化します。
検証に沿いながら、io-threads、 io-threads-do-readsを変更します。
1) "rdbchecksum"
2) "yes"
3) "daemonize"
4) "no"
5) "io-threads-do-reads"
6) "yes"
7) "lua-replicate-commands"
8) "yes"
9) "always-show-logo"
10) "yes"
11) "protected-mode"
12) "yes"
13) "rdbcompression"
14) "yes"
15) "rdb-del-sync-files"
16) "no"
17) "activerehashing"
18) "yes"
19) "stop-writes-on-bgsave-error"
20) "yes"
21) "set-proc-title"
22) "yes"
23) "dynamic-hz"
24) "yes"
25) "lazyfree-lazy-eviction"
26) "no"
27) "lazyfree-lazy-expire"
28) "no"
29) "lazyfree-lazy-server-del"
30) "no"
31) "lazyfree-lazy-user-del"
32) "no"
33) "lazyfree-lazy-user-flush"
34) "no"
35) "repl-disable-tcp-nodelay"
36) "no"
37) "repl-diskless-sync"
38) "no"
39) "gopher-enabled"
40) "no"
41) "aof-rewrite-incremental-fsync"
42) "yes"
43) "no-appendfsync-on-rewrite"
44) "no"
45) "cluster-require-full-coverage"
46) "yes"
47) "rdb-save-incremental-fsync"
48) "yes"
49) "aof-load-truncated"
50) "yes"
51) "aof-use-rdb-preamble"
52) "yes"
53) "cluster-replica-no-failover"
54) "no"
55) "cluster-slave-no-failover"
56) "no"
57) "replica-lazy-flush"
58) "no"
59) "slave-lazy-flush"
60) "no"
61) "replica-serve-stale-data"
62) "yes"
63) "slave-serve-stale-data"
64) "yes"
65) "replica-read-only"
66) "yes"
67) "slave-read-only"
68) "yes"
69) "replica-ignore-maxmemory"
70) "yes"
71) "slave-ignore-maxmemory"
72) "yes"
73) "jemalloc-bg-thread"
74) "yes"
75) "activedefrag"
76) "no"
77) "syslog-enabled"
78) "no"
79) "cluster-enabled"
80) "no"
81) "appendonly"
82) "no"
83) "cluster-allow-reads-when-down"
84) "no"
85) "crash-log-enabled"
86) "yes"
87) "crash-memcheck-enabled"
88) "yes"
89) "use-exit-on-panic"
90) "no"
91) "disable-thp"
92) "yes"
93) "aclfile"
94) ""
95) "unixsocket"
96) ""
97) "pidfile"
98) "/var/run/redis_6379.pid"
99) "replica-announce-ip"
100) ""
101) "slave-announce-ip"
102) ""
103) "masteruser"
104) ""
105) "cluster-announce-ip"
106) ""
107) "syslog-ident"
108) "redis"
109) "dbfilename"
110) "dump.rdb"
111) "appendfilename"
112) "appendonly.aof"
113) "server_cpulist"
114) ""
115) "bio_cpulist"
116) ""
117) "aof_rewrite_cpulist"
118) ""
119) "bgsave_cpulist"
120) ""
121) "ignore-warnings"
122) ""
123) "proc-title-template"
124) "{title} {listen-addr} {server-mode}"
125) "masterauth"
126) ""
127) "requirepass"
128) ""
129) "supervised"
130) "no"
131) "syslog-facility"
132) "local0"
133) "repl-diskless-load"
134) "disabled"
135) "loglevel"
136) "notice"
137) "maxmemory-policy"
138) "noeviction"
139) "appendfsync"
140) "everysec"
141) "oom-score-adj"
142) "no"
143) "acl-pubsub-default"
144) "allchannels"
145) "sanitize-dump-payload"
146) "no"
147) "databases"
148) "16"
149) "port"
150) "6379"
151) "io-threads"
152) "1"
153) "auto-aof-rewrite-percentage"
154) "100"
155) "cluster-replica-validity-factor"
156) "10"
157) "cluster-slave-validity-factor"
158) "10"
159) "list-max-ziplist-size"
160) "-2"
161) "tcp-keepalive"
162) "300"
163) "cluster-migration-barrier"
164) "1"
165) "active-defrag-cycle-min"
166) "1"
167) "active-defrag-cycle-max"
168) "25"
169) "active-defrag-threshold-lower"
170) "10"
171) "active-defrag-threshold-upper"
172) "100"
173) "lfu-log-factor"
174) "10"
175) "lfu-decay-time"
176) "1"
177) "replica-priority"
178) "100"
179) "slave-priority"
180) "100"
181) "repl-diskless-sync-delay"
182) "5"
183) "maxmemory-samples"
184) "5"
185) "maxmemory-eviction-tenacity"
186) "10"
187) "timeout"
188) "0"
189) "replica-announce-port"
190) "0"
191) "slave-announce-port"
192) "0"
193) "tcp-backlog"
194) "511"
195) "cluster-announce-bus-port"
196) "0"
197) "cluster-announce-port"
198) "0"
199) "repl-timeout"
200) "60"
201) "repl-ping-replica-period"
202) "10"
203) "repl-ping-slave-period"
204) "10"
205) "list-compress-depth"
206) "0"
207) "rdb-key-save-delay"
208) "0"
209) "key-load-delay"
210) "0"
211) "active-expire-effort"
212) "1"
213) "hz"
214) "10"
215) "min-replicas-to-write"
216) "0"
217) "min-slaves-to-write"
218) "0"
219) "min-replicas-max-lag"
220) "10"
221) "min-slaves-max-lag"
222) "10"
223) "maxclients"
224) "10000"
225) "active-defrag-max-scan-fields"
226) "1000"
227) "slowlog-max-len"
228) "128"
229) "acllog-max-len"
230) "128"
231) "lua-time-limit"
232) "5000"
233) "cluster-node-timeout"
234) "15000"
235) "slowlog-log-slower-than"
236) "10000"
237) "latency-monitor-threshold"
238) "0"
239) "proto-max-bulk-len"
240) "536870912"
241) "stream-node-max-entries"
242) "100"
243) "repl-backlog-size"
244) "1048576"
245) "maxmemory"
246) "0"
247) "hash-max-ziplist-entries"
248) "512"
249) "set-max-intset-entries"
250) "512"
251) "zset-max-ziplist-entries"
252) "128"
253) "active-defrag-ignore-bytes"
254) "104857600"
255) "hash-max-ziplist-value"
256) "64"
257) "stream-node-max-bytes"
258) "4096"
259) "zset-max-ziplist-value"
260) "64"
261) "hll-sparse-max-bytes"
262) "3000"
263) "tracking-table-max-keys"
264) "1000000"
265) "client-query-buffer-limit"
266) "1073741824"
267) "repl-backlog-ttl"
268) "3600"
269) "auto-aof-rewrite-min-size"
270) "67108864"
271) "logfile"
272) "/var/log/redis/redis.log"
273) "watchdog-period"
274) "0"
275) "dir"
276) "/var/lib/redis"
277) "save"
278) ""
279) "client-output-buffer-limit"
280) "normal 0 0 0 slave 268435456 67108864 60 pubsub 33554432 8388608 60"
281) "unixsocketperm"
282) "0"
283) "slaveof"
284) ""
285) "notify-keyspace-events"
286) ""
287) "bind"
288) "127.0.0.1"
289) "oom-score-adj-values"
290) "0 200 800"
暖機運転
CPUの省電力機能により、アイドル直後のCPUはクロックが低下しています。そのため、ベンチマーク開始直後の性能が低く出ると考えています。
そこで、各テストを実行する前に、集計しないコマンドを実行しています。
検証1:I/Oスレッドを増やすと処理できるリクエスト量は増えるか
予測する結果
- スレッド数を1→2にしたとき、処理できるリクエスト量が大きく増加する
- ボトルネックの通信処理を行うスレッドが倍になるので効果が大きい
- 8スレッドまで山なりに処理量が増加する
- 通信処理の待ち時間にボトルネックがある間はスケールする
- 9スレッドから性能が横ばいになる
- メモリアクセスがボトルネックになり、Threaded I/Oでスケールしなくなる
検証方法
変更点
サーバ
io-threadsを1(無効)〜11に値を変えて比較します
クライアント
-dに64と65を指定します
- Redisには、keyのサイズやデータサイズ、エントリー数に応じて内部の保存形式を変更し、メモリ使用量を削減するオプション(
hash-max-ziplist-entriesなど)があります。保存形式によって結果が異なると考えるので、保存形式の境界となる64バイトと、65バイトの2種類を測定します。
実行コマンド
numactl --cpunodebind=1 ./redis-benchmark -h 127.0.0.1 -q -c 50 -d 64 --threads 11 --csv -n 1000000 -P 1 -t "tests"
-c 50: 並列接続数のデフォルト値
-P 1: パイプラインは有効にしない
--thread 11: redis.confによると、redis-serverのthread数に合わせないと、正しく検証できないので、今回の最大に合わせる
-t tests: get,set,mset,hset,lpush,lpop,sadd,spop,zadd: 基本的なコマンド網羅
-n: 1回のベンチマークの実行時間が10秒程度になる値を指定
データのバラツキを確認するため、各テストを3回実行します。
結果
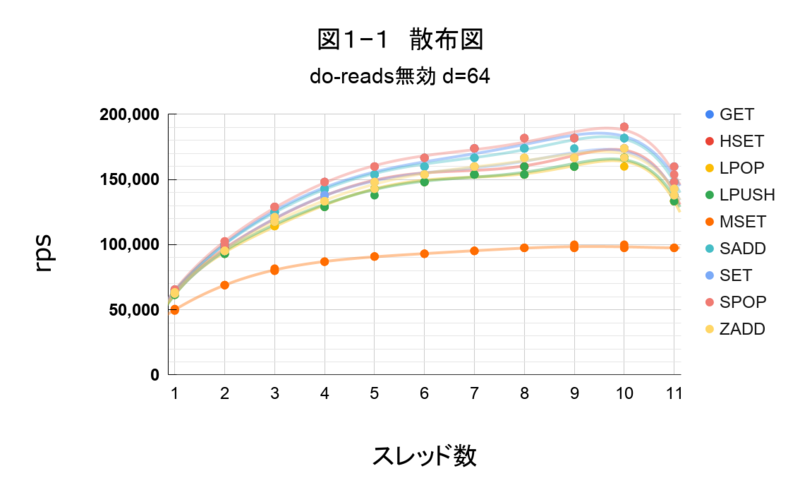
散布図の確認
検証内容の条件でコマンドを実行し、要素をグラフで出力しました。
d=64
図1―1
d=65
図1―2

外れた場所にプロットがなく、同一スレッド数で3回計測した結果に大きなバラツキが無いです。なので、各テストパターンの平均値で性能を確認します。
平均値表
d=64
表1―1
| スレッド数 | GET | HSET | LPOP | LPUSH | MSET | SADD | SET | SPOP | ZADD |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 64521.81 | 62825.44 | 61855.15 | 61855.15 | 50002.71 | 64523.15 | 63156.08 | 65216.97 | 62826.74 |
| 2 | 99993.33 | 96003.16 | 93755.63 | 93755.76 | 68962.35 | 99993.33 | 95232.04 | 101702.39 | 95229.02 |
| 3 | 126333.33 | 121197.42 | 114277.00 | 117633.21 | 80539.95 | 124989.58 | 121202.32 | 129021.16 | 118821.28 |
| 4 | 144614.00 | 137924.69 | 130454.85 | 130460.40 | 86951.48 | 142836.73 | 137912.02 | 148133.51 | 133321.48 |
| 5 | 155873.12 | 148133.51 | 142850.34 | 141195.16 | 90903.58 | 153830.37 | 148133.51 | 159982.94 | 146363.04 |
| 6 | 160153.79 | 153838.27 | 148126.20 | 148126.20 | 93017.49 | 162213.69 | 153822.48 | 166648.15 | 153838.27 |
| 7 | 173882.81 | 159974.41 | 153822.48 | 153830.37 | 95229.02 | 166648.15 | 159991.47 | 173892.89 | 159974.41 |
| 8 | 176537.07 | 159974.41 | 153830.37 | 155881.02 | 97554.63 | 173892.89 | 166638.89 | 181796.14 | 166638.89 |
| 9 | 181796.14 | 166638.89 | 159982.94 | 159991.47 | 98364.30 | 179151.02 | 166648.15 | 181807.17 | 166648.15 |
| 10 | 184682.14 | 173882.81 | 164435.19 | 166648.15 | 98364.30 | 181796.14 | 173892.89 | 190439.92 | 171477.43 |
| 11 | 152075.60 | 139560.39 | 133321.48 | 136386.20 | 97557.80 | 148133.51 | 141201.96 | 153982.26 | 141195.16 |
d=65
表1―2
| スレッド数 | GET | HSET | LPOP | LPUSH | MSET | SADD | SET | SPOP | ZADD |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 64864.46 | 63157.39 | 61856.41 | 61855.15 | 50208.45 | 64511.96 | 63157.39 | 65218.36 | 62496.10 |
| 2 | 100000.00 | 97548.28 | 94490.88 | 93014.60 | 69364.01 | 99993.33 | 97551.45 | 102553.58 | 95229.02 |
| 3 | 124984.37 | 121207.22 | 114272.65 | 115392.84 | 79991.47 | 124984.37 | 121202.32 | 127671.86 | 117637.83 |
| 4 | 142836.73 | 137912.02 | 129021.16 | 131894.09 | 86948.96 | 142843.53 | 137918.36 | 148133.51 | 133315.56 |
| 5 | 153822.48 | 148133.51 | 142843.53 | 142836.73 | 90906.33 | 153838.27 | 148126.20 | 159974.41 | 148126.20 |
| 6 | 162374.65 | 153830.37 | 148140.83 | 148126.20 | 93752.74 | 159982.94 | 153838.27 | 166648.15 | 153838.27 |
| 7 | 173902.97 | 159974.41 | 153830.37 | 153822.48 | 95229.02 | 169053.53 | 159974.41 | 173913.05 | 159982.94 |
| 8 | 173892.89 | 166648.15 | 157923.77 | 159982.94 | 97554.63 | 173892.89 | 166648.15 | 181785.12 | 162195.90 |
| 9 | 181796.14 | 166638.89 | 159982.94 | 159974.41 | 99993.33 | 176538.02 | 166638.89 | 181796.14 | 166648.15 |
| 10 | 181796.14 | 173882.81 | 162195.90 | 164426.66 | 99180.48 | 181796.14 | 173892.89 | 190439.92 | 166638.89 |
| 11 | 151931.03 | 141208.77 | 136379.87 | 137924.69 | 96006.19 | 148133.51 | 142843.53 | 157940.83 | 141208.77 |
io-threadsが1の状態を100%としたrps比較表
d=64
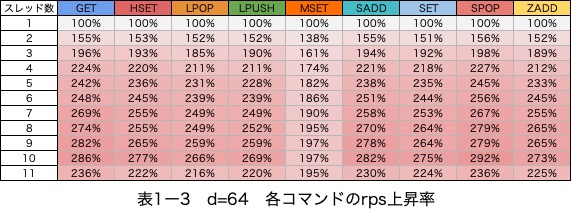
表1―3
d=65
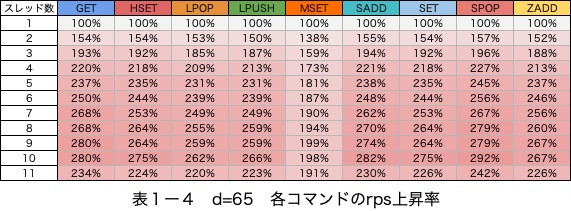
表1―4
考察
結果から、主に2つ気になる点がありました。
1. msetを除いてrpsは10スレッドまで上昇している点
事前の予測通り、山なりにrpsが上昇しています。
mset以外のコマンドで8スレッドの状態で最大190%程度のrpsの上昇が確認できます。
- 読み込み(set)、書き込み(get)の違い
- hash、set、listなどの保存形式
- データサイズによる内部の保存形式の変化
上記の3点による性能への影響は無いと考えます。
msetのみ性能変化のパターンが異なる
msetには以下の特徴があります。
- rps上昇幅が最大100%程度になっており、他のコマンドより低い
- rpsの上昇が、5スレッド程度で頭打ちになっている
- 複数のsetを一つのrequestにまとめているため、通信の回数が少なく、通信効率が良い(rpsが他のコマンドより少なくなる)
- 複数の要素を挿入するため1リクエストのサイズが大きい(メモリR/Wの処理が多め)
「rpsの上昇が、5スレッド程度で頭打ちになっている」点と、「複数のsetを一つのrequestにまとめているため、通信の回数が少なく、通信効率が良い」点から、通信効率が良いとThreaded I/Oの性能上昇は少ないと考えます。
なので、パイプライン1を利用してすでに通信効率が改善されてる場合は、Threaded I/Oを使っても性能はあまり伸びないと言えそうです。
2. 11スレッド目ではrpsが低下している点
io-threadsは8スレッド以上指定した場合、性能変化が横ばいになると予測していました。
しかし、実際は11スレッド目で大きくrpsが低下しました。そこで2つの仮説を立てました。
2.1. redis-server、redis-benchmark以外のプロセスの影響を受けた
redis-server、redis-benchmark以外のプロセスによるCPU負荷(カーネルなど)の影響を受けたと考えます。
よりコアの多いサーバを用意して検証することで確認できると考えますが、用意は厳しいので12コア以上での検証は行いません。(EPYC搭載サーバのご提供お待ちしています)
2.2. スレッド間通信処理のボトルネックが発生している
msetのみ、あまりパフォーマンスが低下していませんでした。そこから、ネットワーク通信部分による影響は少ないと考えます。
また、測定とは別でtopコマンドを利用し、redis-serverのCPU利用率を確認したところ、10スレッドと11スレッドのときだけシステムCPU時間の比重が増えていました。システムCPU時間はメモリR/WやネットワークI/O待ち(epollなど)が行われている時に発生します。
CPU時間の区分目安
- ユーザーCPU時間:ネットワーク書き込み・読み込みで利用される
- システムCPU時間:メモリR/W・epoll(I/O待ち)で利用される
上記を踏まえ、メモリR/Wに関わる場所で速度が低下していると考えます。redis-serverのスレッド間通信に関する部分にボトルネックが発生したと推測します。
この記事の、「2:Redisマルチスレッドはどのように実現されますか?」の4〜5当たりの処理が影響していそうです。
1つのI/O Threadが遅くなると他のスレッドが待たされる実装になっている気がします。
まとめ
io-threadsを有効にしたときは、性能は最大180%程度上昇するio-threadsに指定する値によっては性能低下が発生するので、物理コア数を目安に余裕を持った値を設定する必要がある- 12物理コアでは、9コアをredis-serverに割り当てるまでMSETを除くコマンドで性能は上昇した
検証2: io-threads-do-readsの有無
読み込みのスレッド化はあまり変わらないとされていますが、本当に変化しないのか確認をします。
予測する結果
検証1と同様の山なりの性能変化をする。
また、①データの読み込み・②プロトコル解析が並列化されるので、スレッド数によって検証1の時よりスケールすると考えます。
検証方法
変更点
io-threadsを2〜11に値を変えて比較する- 1の時の挙動は
io-threads無効化時の挙動と同じなので検証1の結果を流用する
- 1の時の挙動は
-dに64と65を指定するio-threads-do-readsをonにする
実行コマンド
numactl --cpunodebind=1 ./redis-benchmark -h 127.0.0.1 -q -c 50 -d 64 --threads 11 --csv -n 1000000 -P 1 -t "tests"
データのバラツキを確認するため、各テストを3回実行します。
結果
散布図の確認
検証内容の条件でコマンドを実行し、要素をグラフで出力しました。
d=64
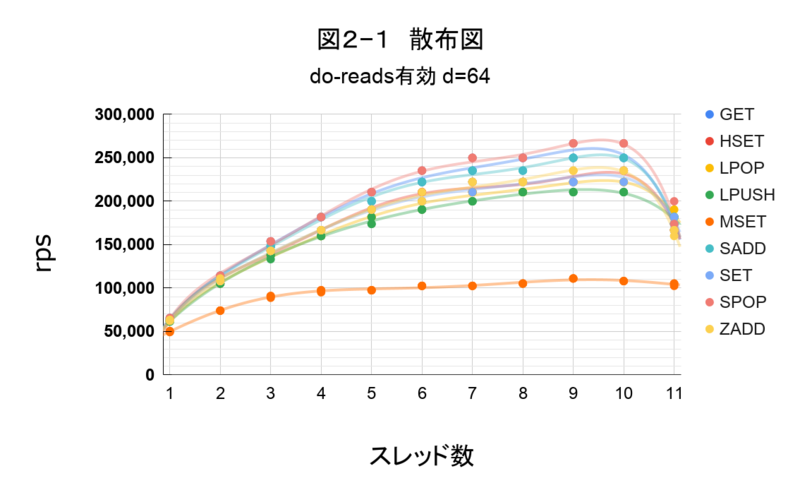
図2―1
d=65
図2―2
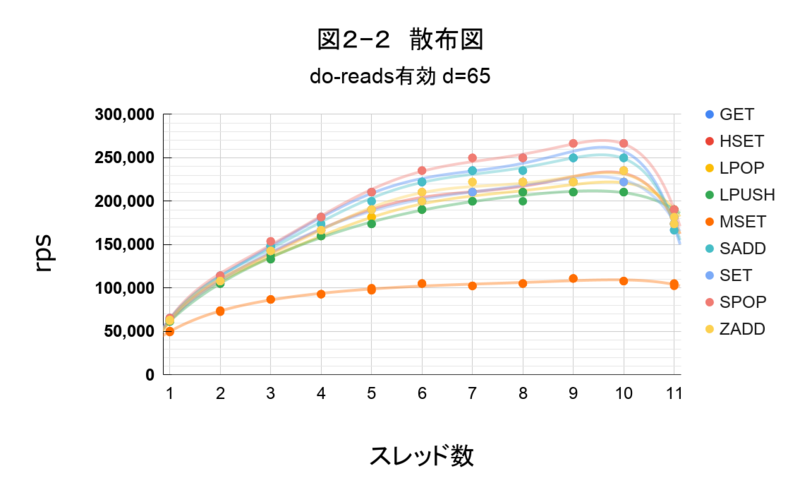
同一スレッド数で3回計測していますが、11スレッド目のプロットは バラツキが見られました。なので、11スレッドのデータは利用せず、10スレッドまでの各テストパターンの平均値を使い性能を確認します。
平均値表
d=64
表2―1
| スレッド数 | GET | HSET | LPOP | LPUSH | MSET | SADD | SET | SPOP | ZADD |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 64521.81 | 62825.44 | 61855.15 | 61855.15 | 50002.71 | 64523.15 | 63156.08 | 65216.97 | 62826.74 |
| 2 | 113219.04 | 109097.20 | 105259.47 | 105255.77 | 74068.59 | 113219.04 | 109105.21 | 114281.36 | 109101.10 |
| 3 | 151923.72 | 142843.53 | 137918.36 | 136379.87 | 90227.54 | 148133.51 | 142843.53 | 153822.48 | 142850.34 |
| 4 | 181796.14 | 166638.89 | 159982.94 | 159974.41 | 96780.33 | 181818.19 | 166648.15 | 181796.14 | 166648.15 |
| 5 | 206988.00 | 190452.01 | 181807.17 | 176526.99 | 97554.63 | 199973.35 | 190439.92 | 210511.54 | 190464.10 |
| 6 | 226528.16 | 206974.67 | 196786.65 | 190439.92 | 102560.59 | 222172.86 | 199960.02 | 235275.67 | 203480.67 |
| 7 | 240159.18 | 218307.13 | 210496.77 | 199960.02 | 102557.09 | 235257.22 | 218308.81 | 249958.35 | 222189.31 |
| 8 | 249937.52 | 222222.22 | 210496.77 | 210511.54 | 105255.77 | 235257.22 | 222205.77 | 249958.35 | 222189.31 |
| 9 | 255534.73 | 222172.86 | 222189.31 | 210511.54 | 111102.88 | 249937.52 | 222172.86 | 266642.97 | 235238.77 |
| 10 | 255490.21 | 235238.77 | 222189.31 | 210496.77 | 108096.41 | 249958.35 | 230901.92 | 266595.59 | 235275.67 |
| 11 | 174102.27 | 171687.63 | 184670.05 | 179173.06 | 104352.77 | 176736.38 | 176538.02 | 180160.57 | 164426.66 |
d=65
表2―2
| スレッド数 | GET | HSET | LPOP | LPUSH | MSET | SADD | SET | SPOP | ZADD |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 64864.46 | 63157.39 | 61856.41 | 61855.15 | 50208.45 | 64511.96 | 63157.39 | 65218.36 | 62496.10 |
| 2 | 113219.04 | 108096.41 | 107148.30 | 105259.47 | 73619.72 | 112160.84 | 108100.31 | 114277.00 | 108096.41 |
| 3 | 148133.51 | 142843.53 | 136385.79 | 134847.71 | 86954.00 | 148133.51 | 142836.73 | 153822.48 | 142836.73 |
| 4 | 181785.12 | 166648.15 | 159991.47 | 159982.94 | 93017.49 | 176526.99 | 166638.89 | 181796.14 | 166648.15 |
| 5 | 210482.00 | 190452.01 | 181796.14 | 173902.97 | 98364.30 | 199986.67 | 190452.01 | 210482.00 | 190452.01 |
| 6 | 222189.31 | 203467.35 | 193613.29 | 190439.92 | 105259.47 | 222189.31 | 199960.02 | 235294.12 | 206989.44 |
| 7 | 235275.67 | 210511.54 | 210482.00 | 199973.35 | 102557.09 | 235238.77 | 210496.77 | 249937.52 | 222189.31 |
| 8 | 249958.35 | 222189.31 | 210482.00 | 206988.00 | 105252.08 | 235275.67 | 222205.77 | 249958.35 | 222189.31 |
| 9 | 249958.35 | 222172.86 | 218275.91 | 210511.54 | 111102.88 | 249958.35 | 222189.31 | 266595.59 | 222205.77 |
| 10 | 261042.90 | 235238.77 | 222189.31 | 210511.54 | 108100.31 | 249979.17 | 226528.16 | 266595.59 | 235257.22 |
| 11 | 171477.43 | 176526.99 | 190452.01 | 190439.92 | 104352.58 | 174102.27 | 176526.99 | 190452.01 | 176516.91 |
io-threadsが1の状態を100%としたrps比較表
d=64
表2―3

d=65
表2―4
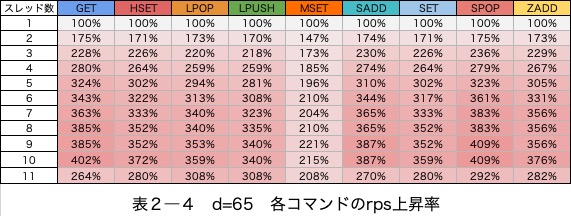
io-threads-do-reads有効時・無効時のrpsの上昇率の差を確認
io-threads-do-reads有効の場合と無効の場合のrpsの差を見ることで、io-threads(④データ送信のスレッド化)による高速化を差し引いた、io-threads-do-readsによる高速化を確認できると考えます。
d=64を指定しているとき
表2―5
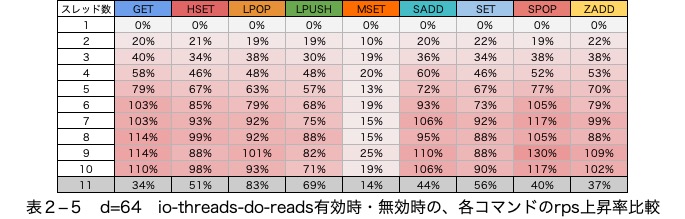
図2―3
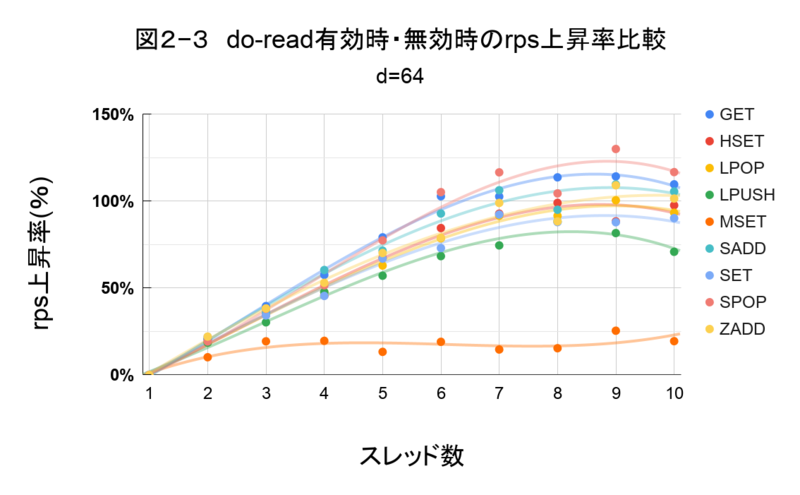
d=65を指定しているとき
表2―6
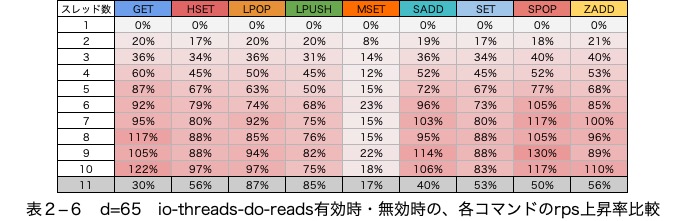
図2―4

考察
予測する結果と異なる性能変化をした
7スレッド目までは性能が伸びている項目もありますが、8スレッド目からはio-threads-do-readsによって性能が変化しない項目があります。
安定してio-threads-do-readsによる性能の向上が見込めるのは7スレッドまでと考えます。
msetを除きrpsは10スレッド目まで増加している
SPOPは、300%程度性能が上昇しています。また、一番伸び幅が小さいLPUSHでも240%の性能の伸びが確認できます。
(表2―5、表2―6)の、io-threads-do-reads有効時・無効時のrpsの差を見ると、io-threads-do-readsを有効にすることで、最大110%程度の高速化が見込めると考えます。
msetのみ変化が異なる
msetは4スレッド目で上昇が頭打ちになっています。
msetでは他のコマンドと比べ、io-threads-do-readsの効果は薄いです。
まとめ
io-threadsとio-threads-do-readsを有効にしたとき、性能は最大300%程度向上するio-threads-do-readsによって、性能は最大100%程度上昇する
- msetコマンドでは、あまり性能は伸びなかった
検証3 Hyper-Threading(HT)の有効、無効によるパフォーマンス変化
検証1、2ではHyper-Threading(HT)を無効化し、検証しました。
redis-benchmarkのドキュメントには、CPUの利用方法に関わるNUMAの考慮事項は記載されていました。しかし、CPUの利用方法に関わるHTのことには触れられていませんでした。
私は、HTの影響で同一コアへRedisのスレッドが割り当てられ、パフォーマンスに悪影響がある可能性があると考えています。
検証3では、本当にHTの有効、無効によってパフォーマンスが変化するか検証します。
検証1、2と同じく、numactlを使いプログラムが利用するCPUを固定します。
予測する結果
1コアに2つのスレッドが割り当てられた時に、パフォーマンスが大きく低下する。
検証方法
変更点
サーバ
Hyper-Threadingを有効にするio-threadsを1(無効)〜11に値を変えて比較するio-threads-do-readsを無効にするio-threadsを有効にする
クライアント
-dに64を指定する
Redisのデータサイズによる圧縮はこの検証では考慮しません。
実行コマンド
numactl --cpunodebind=1 ./redis-benchmark -h 127.0.0.1 -q -c 50 -d 64 --threads 11 --csv -n 1000000 -P 1 -t "tests"
各テストを3回実行します。
散布図の確認
検証内容の条件でコマンドを実行し、すべての要素をグラフで出力しました。
Hyper-Threading 有効
図3―1
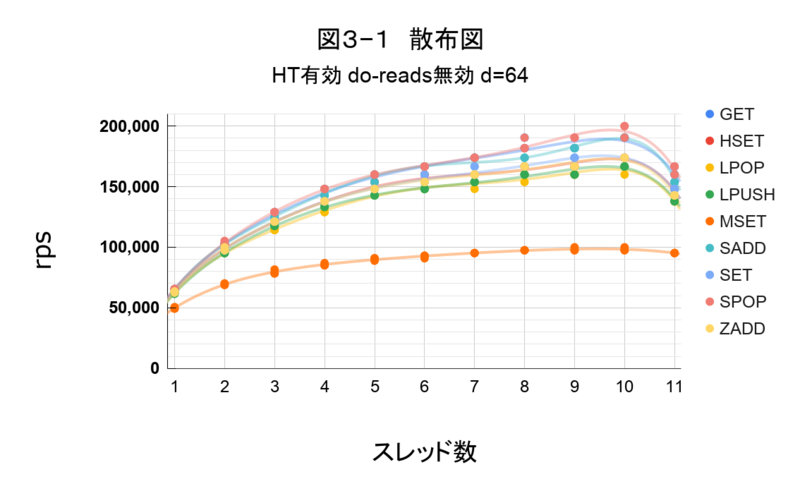
外れた場所にプロットがなく、同一スレッド数で3回計測した結果に大きなバラツキが無いです。なので、各テストパターンの平均値で性能を確認します。
Hyper-Threading 無効(検証1のデータ)
図1―1
平均値表
Hyper-Threading 有効
表3―1
| スレッド数 | GET | HSET | LPOP | LPUSH | MSET | SADD | SET | SPOP | ZADD |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 65570.90 | 63829.34 | 62496.10 | 62175.63 | 49797.78 | 64511.96 | 64170.65 | 65570.90 | 63157.39 |
| 2 | 102553.58 | 98367.48 | 95232.04 | 95232.04 | 69365.65 | 101699.05 | 98367.48 | 103453.08 | 98364.30 |
| 3 | 126328.12 | 121197.42 | 114272.65 | 117633.21 | 79492.14 | 126328.12 | 121207.22 | 129015.61 | 121202.32 |
| 4 | 146363.04 | 137918.36 | 130460.03 | 133321.48 | 85715.75 | 144599.89 | 137918.36 | 148133.51 | 137918.36 |
| 5 | 157931.66 | 150032.27 | 142843.53 | 142836.73 | 90230.18 | 157940.19 | 148133.51 | 159974.41 | 148140.83 |
| 6 | 164417.40 | 155873.12 | 148126.20 | 148133.51 | 92315.65 | 166638.89 | 155881.02 | 166638.89 | 153838.27 |
| 7 | 173882.81 | 159982.94 | 151931.03 | 153822.48 | 95232.04 | 171477.43 | 162205.16 | 173882.81 | 160000.00 |
| 8 | 184682.14 | 166638.89 | 157923.77 | 159982.94 | 97554.63 | 173882.81 | 166638.89 | 184681.08 | 166648.15 |
| 9 | 181796.14 | 166648.15 | 159982.94 | 162195.90 | 98367.48 | 181796.14 | 173913.05 | 190452.01 | 166638.89 |
| 10 | 190439.92 | 173892.89 | 164425.93 | 166638.89 | 98367.48 | 190452.01 | 173882.81 | 196799.98 | 173882.81 |
| 11 | 160153.15 | 146369.85 | 137912.02 | 139553.59 | 95232.04 | 155889.55 | 146363.04 | 164426.66 | 142836.73 |
Hyper-Threading 無効(検証1のデータ)
表1―1
| スレッド数 | GET | HSET | LPOP | LPUSH | MSET | SADD | SET | SPOP | ZADD |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 64521.81 | 62825.44 | 61855.15 | 61855.15 | 50002.71 | 64523.15 | 63156.08 | 65216.97 | 62826.74 |
| 2 | 99993.33 | 96003.16 | 93755.63 | 93755.76 | 68962.35 | 99993.33 | 95232.04 | 101702.39 | 95229.02 |
| 3 | 126333.33 | 121197.42 | 114277.00 | 117633.21 | 80539.95 | 124989.58 | 121202.32 | 129021.16 | 118821.28 |
| 4 | 144614.00 | 137924.69 | 130454.85 | 130460.40 | 86951.48 | 142836.73 | 137912.02 | 148133.51 | 133321.48 |
| 5 | 155873.12 | 148133.51 | 142850.34 | 141195.16 | 90903.58 | 153830.37 | 148133.51 | 159982.94 | 146363.04 |
| 6 | 160153.79 | 153838.27 | 148126.20 | 148126.20 | 93017.49 | 162213.69 | 153822.48 | 166648.15 | 153838.27 |
| 7 | 173882.81 | 159974.41 | 153822.48 | 153830.37 | 95229.02 | 166648.15 | 159991.47 | 173892.89 | 159974.41 |
| 8 | 176537.07 | 159974.41 | 153830.37 | 155881.02 | 97554.63 | 173892.89 | 166638.89 | 181796.14 | 166638.89 |
| 9 | 181796.14 | 166638.89 | 159982.94 | 159991.47 | 98364.30 | 179151.02 | 166648.15 | 181807.17 | 166648.15 |
| 10 | 184682.14 | 173882.81 | 164435.19 | 166648.15 | 98364.30 | 181796.14 | 173892.89 | 190439.92 | 171477.43 |
| 11 | 152075.60 | 139560.39 | 133321.48 | 136386.20 | 97557.80 | 148133.51 | 141201.96 | 153982.26 | 141195.16 |
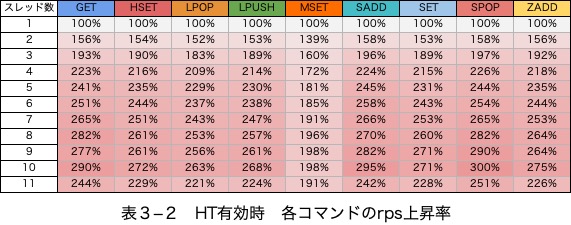
io-threadsが1の状態を100%としたrps比較表
Hyper-Threading 有効
表3―2
Hyper-Threading 無効(検証1のデータ)
表1―3
考察
HT有効と無効で性能は変わっていない
HT有効時(表3―2)と無効時(表1―3)で、ほぼ同じrpsでした。性能に影響は無いと考えます。
linuxで動作しているプロセススケジューラは、サーバが複数CPUで構築されていること、HTによって1物理コアを2論理コアに分割している等を正しく認識できるようです。
少なくともRedisのみを実行し、numactlを使い、同じCPUの中でスレッドが動作できるように制御しているときは、HTによる影響はほとんど無いと言えそうです。
この記事の、ポリシー情報に関する情報を参考にしました。
まとめ
- Hyper-Threadingの有無では、Redisの性能はほぼ変化しない
今回の検証結果(再掲)
検証1〜3を踏まえ、以下のことがわかりました。
io-threadsを有効にしたときは、性能は最大180%程度上昇するio-threadsとio-threads-do-readsを有効にしたときは、性能は最大300%程度向上するio-threadsに指定する値によっては性能低下が発生するので、物理コア数を目安に余裕を持った値を設定する必要がある- 12物理コアでは、9コアをredis-serverに割り当てるまで、MSETを除くコマンドで性能は上昇した
終わりに
今回の検証で、Threded I/OはRedisの高速化に役に立つことが分かりました。今後はバージョンアップに必要な検証を進めて行きたいと思います。
redis-clusterのバージョン3系からのアップグレードなど、ドキュメントがなかなか見つからない部分もあり、これからもRedisとの格闘は続きそうです。release notes頑張って読みます。
この記事を書き出すまで、並列処理のことをしっかり理解を深めていくつもりでした。しかし、蓋を開ければカーネルの挙動や、キャッシュ・CPUの基礎など、PCの基本の学習が中心となり、インフラの奥深さを実感させられました。
また、スケジュールの甘さや、文章の稚拙さから、先輩にレビューの時間をかなり頂いてしまいました......(改めてありがとうございました)
マイクロアドには好奇心や挑戦することを大切にする社風があると感じています。これからもデータ処理基盤など、さまざまな技術に触れ、また学びがあればアウトプットできればと思います。
また、物理サーバの運用からクラウド化・自動化まで幅広い分野の中で、何か突き詰めたい!そんな困難に対し情熱を持って取り組めるインフラエンジニアをマイクロアドでは募集しています。
一緒に働いてみたいと思う方は、 マイクロアド採用情報 ページより応募ください!
-
パイプラインとは: 複数のコマンドを実行する時、個別で送信せず1回の通信にまとめることで、通信による性能低下を軽減する手法 ↩