
こんにちは。 マイクロアドでアプリケーションエンジニアをしている新卒1年目の武井です。
今回は私が最近の案件で Redis と MessagePackを使った開発のお話をさせていただければと思います。
Redis と MessagePack
まず題名のRedisとMessagePackのそれぞれの説明を超軽くしたいと思います。
Redisとは、高速に動作するインメモリのキーバリュー型のデータベースです。
そしてMessagePackとは、JSONの置き換えとして利用できる効率の良いバイナリ形式のオブジェクト・シリアライズ フォーマットです。
Redisは有名ですが、MessagePackに関して初めて聞いたという人も少なくないのではないでしょうか。少しだけどのようなものか見ていきます。
MessagePackについて
MessagePackはあらゆるオブジェクトをシリアライズ・デシリアライズできます。
シリアライズは、アプリケーションオブジェクトからMessagePack型システムへの変換です。
デシリアライズは、MessagePack型システムを介してMessagePack形式からアプリケーションオブジェクトへの変換です。
シリアライズはMessagePack特有の表現形式によって置換されます。
小さな整数値はたった1バイト、短い文字列は文字列自体の長さ+1バイトでシリアライズできます。
という公式の言葉からもあるように、シリアライズによって
>>> import msgpack >>> msgpack.packb([1,2,3]) b'\x93\x01\x02\x03' >>> msgpack.unpackb(_) [1, 2, 3]
- [1,2,3] : 7バイト
- x93x01x02x03 : 4バイト
と圧縮することができます。
もちろん日本語もシリアライズできます。
>>> msgpack.packb("マイクロアド") b'\xb2\xe3\x83\x9e\xe3\x82\xa4\xe3\x82\xaf\xe3\x83\xad\xe3\x82\xa2\xe3\x83\x89' >>> msgpack.unpackb(_).decode('utf-8') 'マイクロアド'
MessagePackについては、以下のqiitaの記事が非常に参考になります。
また、MessagePack公式はこちらです。
MessagePack: It's like JSON. but fast and small.
それぞれの採用経緯
やりたかったこととしては、毎秒数千から最大数万件のデータをインプットとして、それら全てのデータの一部を別のデータとして高速なキーバリューストアにJSON形式で貯蓄していきたいということです。貯蓄するデータの件数は最終的に約数億件にもなります。
毎秒数千のデータの取得と更新をほぼほぼリアルタイムで処理する、更にコスト的な問題やマイクロアドでの開発実績、更に検証を含む開発完了までの期間などの要件から総合的にもっと良いミドルウェアはマイクロアドの中ではRedisでした。
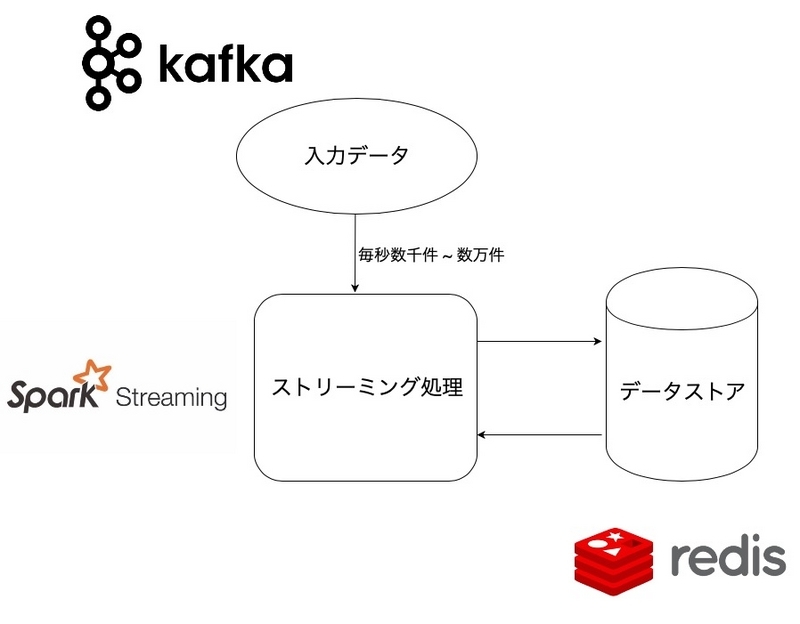
ここで問題になってくるのは、数億件のデータを貯蓄するRedisの容量です。
Redisはインメモリなので、貯蓄する容量が大きければ大きくなるほどメモリ容量が大きくなるのでコストがかかります。データの件数は変えることができないので、データを圧縮することになります。
そこで登場するのがMessagePackです。
gzipやProtocolBuffersも検討しましたが、以下の点でMessagePackはそれらに比べて有用でした。
- リアルタイム処理における解凍・圧縮コスト
- カラムの変更・追加に強い
- 圧縮された状態でもRedisの中の生データも簡単にみれる
- 格納するJSON形式の文字列に相性が良い
これらの理由からMessagePackを使う運びになりました。
MessagePackで圧縮
それでは、実際に生データとMessagePackの容量の差に関して見ていきたいと思います。
例えば少し複雑な構造のログをほぼほぼリアルタイムに記録したいとします。
通常、RedisでJSONのようなデータを使用する場合、hashをJSONのキーとして扱い、hashに紐づくvalueをJSONのキーに対するvalueにする使い方が一般的ですが、
今回は、hashに識別する情報を格納して、そのhash値毎にJSONのvalueを蓄積したいと仮定します。
JSONは以下のようなものを想定します。
{
"total_log1_count" : 123,
"total_log2_count" : 234,
"total_log3_count" : 345,
"daily_log1_count" : [1,2,3],
"daily_log2_count" : [1,2,3],
"daily_log3_count" : [1,2,3],
"last_time" : 1543636800,
"first_time" : 1541041200
}
このようなデータを数千件から数億件蓄積しなければならないとします。
当然ながらデータの量が気になるので、一旦ローカル環境で100万件格納してみてどの程度の容量になるかみてみます。
ローカル環境でランダムに値を生成してRedisに格納していくPythonのコードです。
json_dict = json.loads(base_json) r = redis.StrictRedis(host='localhost', port=6379, db=0) pbar = tqdm(total=1000000) for i in range(1000000): for j in json_dict: if type(json_dict[j]) == list: if len(json_dict[j]) > 10: json_dict[j].clear() json_dict[j].append(random.randrange(1000)) elif j != 'last_time' and j != 'first_time': json_dict[j] = random.randrange(1000) redis_key = 'aid' + str(i) + '_' + str(random.randrange(500)) redis_field = random.choice(action_type) + '_' + str(random.randrange(10000)) r.hset(redis_key, redis_field, json_dict) pbar.update(1)
すると結果(Redisの容量)は
127.0.0.1:6379> info ... # Memory ... used_memory:592095712 used_memory_human:564.67M ...
次に、MessagePackで圧縮してからRedisに格納します。
やり方としては上記のコードにmsgpackをインポートして 、Redisに格納する前に
packed_json = msgpack.packb(json_dict) r.hset(redis_key, redis_field, packed_json)
とするだけです。これだけで15%以上圧縮できてしまうのです。
127.0.0.1:6379> info ... # Memory ... used_memory_peak:494268096 used_memory_peak_human:471.37M ...
MessagePack と JSON
更にMessagePackの良い点として、JSON形式の文字列をMessagePackで圧縮し保存したバイトコードについてはJava や Scala の class に値をアンパックして容易に格納することができます。
これはJacksonのインスタンスにMessagePackのシリアライザを渡すことでMessagePackを取り扱えるようになっているようです。
以下は先ほどのJSONをScalaのcase classに格納する例です。
(ちなみになぜScalaなのかというと、このログの蓄積はSpark Streaming で行うことを仮定しているからです)
- case class を用意
case class CountData ( @BeanProperty totalLog1Count: Int, @BeanProperty totalLog2Count: Int, @BeanProperty totalLog3Count: Int, @BeanProperty dailyLog1Count: Option[Seq[Int]], @BeanProperty dailyLog2Count: Option[Seq[Int]], @BeanProperty dailyLog3Count: Option[Seq[Int]], @BeanProperty lastTime: Long, @BeanProperty firstTime: Long ) object CountData { def apply(value: Array[Byte]): CountData = { val mapper = new ObjectMapper(new MessagePackFactory) mapper.registerModule(DefaultScalaModule) mapper.readValue(value, classOf[CountData]) } }
- Redisから取得
val jedis = new Jedis("localhost", 6379) val byteData = jedis.hget("redis_key".getBytes, "hash_value".getBytes) CountData(byteData)
このようにして、Redisからの値をcase classに展開して取得することができます。
case classに展開することにより、そこからはscalaの強力な機能をフルに使って処理を行うことができます。
また、仕様変更によるJSONカラムの増加にも容易に対応できるなどの柔軟性もあります。
最後に
簡単でしたが、マイクロアドでのRedisとMessagePackを組み合わせて使った事例を紹介させていただきました。
何かの参考になれば幸いです。