はじめに
初めまして, マイクロアドで機械学習エンジニアをしている福島です. 今年の4月に新卒でマイクロアドに入社し, 現在は UNIVERSE Ads というプロダクトでCTR(Click Through Rate)予測や入札アルゴリズムの開発研究をしています.
今回はCTR予測について共有させていただきたいと思います.
CTR予測ではロジスティック回帰が広く使われてきており, マイクロアドでも長らく利用されてきました.

線形モデルであるため解釈性の高さや推論速度の速さなどのメリットも多く, 現在でも広く使われている手法です. しかし複雑なデータにはフィッティングしづらく, CTR予測のようなカテゴリ変数が多いデータの場合はデータを何らかの方法で連続値に変換する必要もあります. マイクロアドでは, entity embedding1を用いて作った分散表現を利用してカテゴリ変数を連続値に変換していましたが, 各特徴量の次元数などのハイパーパラメータが多く扱いづらいこともあり, この2ヶ月ほどCTR予測アルゴリズムをロジスティック回帰から勾配ブースティングを用いた手法に変更しようと動いていました.
こちら形になってきたので簡単にまとめたいと思います.
勾配ブースティングとは
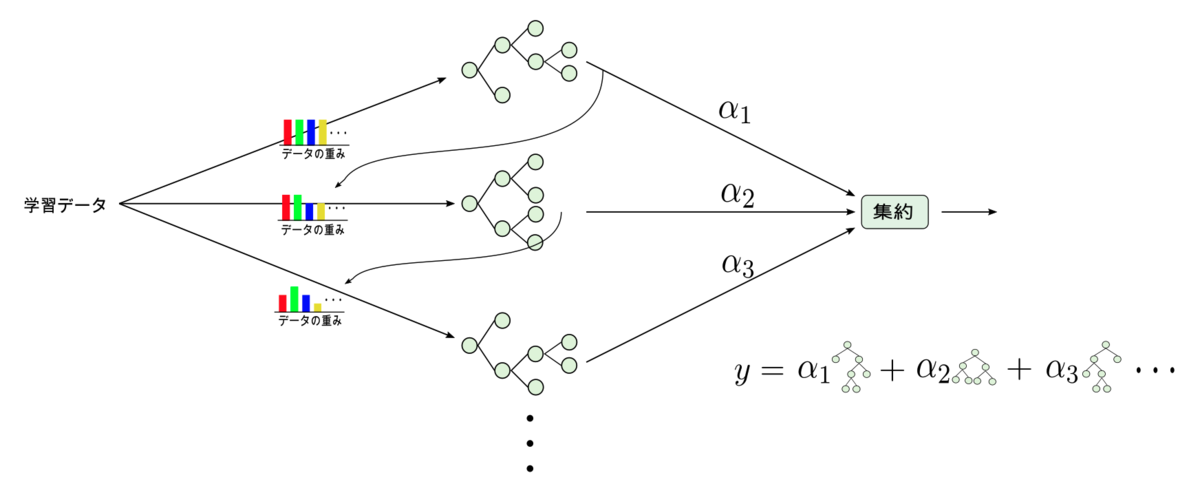
勾配ブースティングとは"ブースティング"と呼ばれるアンサンブル学習の一種です. アンサンブル学習では複数の弱学習器を用いて出力値を得ますが, ブースティングでは弱学習器を学習する際に一つ前までの弱学習器で誤分類したデータを優先的に分類できるように学習していくため, 損失をより小さくできます.
勾配ブースティングとしては以下のフレームワークが有名で, kaggleなどの競技データ分析においても高い性能を出してます.
実際のRTBのデータに適用した結果は以下の通りです. (ハイパーパラメータのtuningは重要ですが, データに大きく依存するのでここでは省略します)
| 手法 | normalized entropy | PR-AUC |
|---|---|---|
| Entity Embedding + logistic redression | 0.890435 | 0.030371 |
| Entity Embedding + XGBoost | 0.842168 | 0.041808 |
| LightGBM | 0.832628 | 0.046433 |
LightGBMが最も予測精度が高い結果となりました. また, 予測精度以外にもLightGBMには以下のメリットがあります.
- 学習速度が速い(大規模データへの適用に耐えうる)
- メモリ効率が高い
- カテゴリ変数の決定木に対応している(XGBoostを用いる場合も特徴量を連続値に変換する必要がある)
RTBは1日に数億のインプレッションが発生するので, その分学習データは膨大になります. 学習速度が速いことでより多くのデータを学習に利用することができるのでこの恩恵は大きいです. また, CTR予測においては特徴量のほとんどがカテゴリ変数です. (ユーザ性別, メディアURLなど) LightGBMではカテゴリ変数をそのまま利用できるため, 分散表現が必要ないので学習結果の解釈がし易くなります. 分散表現の学習にかかっていた時間を短縮できるため, 様々な検証が行いやすいことに加え, データ整形周りの保守性も高くなります.
精度向上以外にもメリットが複数あるのでLightGBMの導入を決定しました.
プロダクトに導入する上での問題点
推論速度の制約
ここが一番のボトルネックですね. RTBの全ての処理はおおよそ100ms以内に完結しなければならないのですが, その中でctrの予測に使える時間は5ms程度しかありません. そのため, 予測精度だけでなく推論速度も重要な指標になります.
実際のRTBのデータを用いて, max_depth=3としその他のハイパーパラメータにはデフォルト値を用い, early stopppingでブースティング回数を決定した場合の推論速度は以下のようになりました.
| 手法 | 1レコードあたりの推論時間(1000回平均) |
|---|---|
| XGBoost | 3.202(ms) |
| LightGBM | 19.8408(ms) |
(Pythonで学習し, 推論はScala)
学習速度が速いと言われているLightGBMですが, 実は推論時間は他の有名な勾配ブースティングの手法と比較すると最も遅いんですね.
これでは求められる推論速度には全く届いていません. まずはこの問題を解決しなければなりません.
パラメータを変化させて推論速度の比較を行ったところ, num_boost_round(ブースト回数, 弱分類器の数)に対して大きく依存していることがわかりました.
| num_boost_round | 推論速度 (ms) |
|---|---|
| 1500 | 19.8408 |
| 300 | 3.856 |
弱分類器の数が多いほど推論には時間がかかるようです. 300程度であれば実用的な速度が出ることが確認できたので, 少ない回数でlossが下がるように学習率を調整し, 本番環境に導入しました.
カテゴリ変数の取り扱い
マイクロアドでは現在, モデルの学習はPythonで行い, 実際のCTRの予測はScalaで行っています. 今回LightGBMを利用するにあたり, Scala側ではMicrosoftが提供しているCライブラリのラッパーを利用しました. PythonのLightGBMライブラリではpandasのカテゴリ変数を利用すれば簡単にカテゴリ変数の決定木を学習することができるのですが, ここに思わぬ落とし穴があったので紹介します.
PythonのLightGBMではpandasのDataFrameをサポートしていて, 以下のようにカラムの型をcategoryにしておくとカテゴリ変数の決定木を学習できます.
(例)
>>> df.dtypes poisonous category cap-shape category cap-surface category cap-color category bruises category
import lightgbm as lgb
X = df.drop(('true_label').astype('category')
y = df['true_label']
d_train = lgb.Dataset(X, y)
model = lgb.train(params, d_train)
これでカテゴリ変数の決定木は学習できるのですが, このモデルをScalaで読み込んで推論すると結果がPythonでpandas.DataFrameを使った時と変わってしまいます. この原因が長らく分からず苦戦していたのですが, 原因はpandas.DataFrameのカテゴリ変数を使っていたことでした.
上記のようにcategory型を用いると, 内部では自動的に元の値を別の整数値にマッピングし, そのマッピング情報をpandas_categoricalという変数に保存します.
推論時に同様にpandas.DataFrameを利用すると保持してあるマッピング情報を利用して元の値をマッピングしなおして利用されるのですが, Scalaでの推論の場合pandasを利用しないのでこのマッピングが
行われず元の値のまま利用されます. このためPythonでpandasを用いた場合と結果が変わってしまうんですね.
つまりpandas.DataFrameを使ったときだけ内部の挙動が違うことが原因でした. (ライブラリの中身をprintデバッグしてようやく気づきました...)
原因がわかれば対処は簡単で, 下記のようにpandasのcategory型を使わず, カテゴリ変数を指定すれば内部での余計なマッピングは発生しません.
X = df.drop(('true_label')
y = df['true_label']
d_train = lgb.Dataset(X.values, y, categorical_feature=X.columns)
model = lgb.train(params, d_train)
逆にこの機能があるおかげで, pandas.DataFrameを使う場合はわざわざ文字列などを整数値にエンコードしなくてもそのままカテゴリ変数として使えるんですね. 今回は罠にハマりましたが勉強になりました.
終わりに
今回CTRの予測手法をロジスティック回帰からLightGBMに変更したことで, 予測精度の向上を確認することができました. RTBで広告効果や利益の向上のためにはCTR予測の正確さ以外にも, 入札戦略や落札額予測など多くの要素が 必要となりますが, CTR予測が正確である事はこれらの基盤であり非常に重要なことですので今後も改善に努めていきたいと思います.