はじめに
こんにちは、マイクロアドで機械学習エンジニアをしている木村です。
この記事では、マイクロアドにおける ML(Machine Learning)モデル学習バッチのログ設計とその監視について紹介します。
また、後半では実際のダッシュボードを用いた運用事例についても紹介します。
MLOpsとは
MLOps とは、ML システムの開発から運用・監視までのライフサイクル全体を効率的に管理するための手法です。主な要素は以下の通りです。
| 要素 | 内容 |
|---|---|
| データ管理 | 学習データの品質管理やバージョニング |
| 学習の自動化 | 学習パイプラインの構築と自動実行 |
| デプロイ | 学習済みモデルの本番反映 |
| 監視 | 予測精度やデータ分布の変化の継続的モニタリング |
| 再学習 | 再学習のトリガーやスケジュール |
ML システムではモデルの性能がデータに依存するため、デプロイ後の継続的な監視が特に重要です。
監視要件の整理
1. MLシステムの一般的な監視要件の確認
ML システムの監視設計にあたり、まずは書籍1を参考に一般的な監視要件を整理しました。
ML システムにおける監視は、大きく以下のレイヤに分類できます。
| データ収集 / ETLバッチ | 学習バッチ | 予測API | |
|---|---|---|---|
| ソフトウェア層 |
|
|
|
| データ層 |
|
||
| ML 層 |
|
|
|
実際の ML システムはデータ収集・学習・予測といった複数のコンポーネントが異なるサーバ・言語・設計で構成されています。
したがって上記の監視項目すべてを1つのダッシュボードに集約するのは現実的でないため、コンポーネントごとに適切な監視を設ける方針が実用的です。
本記事では、この中で「学習バッチの ML 層部分」(オフライン評価指標、特徴量の重要度など)についての監視を考えます。
2. 実際のインシデントを元にした監視要件の整理
一般的な監視要件に加え、マイクロアドで実際に経験した ML システム関連のインシデントも監視設計において重要です。
代表的なインシデント
| インシデント | 概要 |
|---|---|
| データドリフトによる予測値の急変 | 正例率高騰により予測値が極端に高くなった |
| 特徴量変化で予測が不安定化 | 新ドメイン流入で対応する学習データが存在せず予測値が不安定に |
| 慢性的な予測精度の低下 | リリース後に問題なく運用されていたモデルの予測傾向がいつの間にか大きく変化 |
調査過程で共通していた課題
| フェーズ | 課題 |
|---|---|
| 検知 | ビジネス側からの報告で初めて気づく。学習バッチ自体は正常終了しており、直近の大きな機能改修もない |
| 原因切り分け | 配信結果に影響する要素が多く(配信最適化・案件設定・時間帯等)、学習バッチが原因かの判断が難しい |
| 時系列追跡 | 障害の検知日と実際の傾向変化の発生日にズレがあり、因果関係が曖昧 |
| 共有 | 調査者によりデータ抽出やグラフのフォーマットが異なり、ビジネス側への説明に工数がかかる |
上記を踏まえ、監視に求められる要素を以下のように整理しました。
- 1日〜数週間単位でモデルの傾向変化を監視できる
- インシデント発生時、モデル側に原因があるかを素早く切り分けられる
- チーム全体で同じクエリ結果・同じ図を確認でき、過去との比較ができる
- 事前に障害の兆候を検知できる
1と2から整理した今回の監視要件
上記を組み合わせて、今回の監視要件を以下のように整理しました。
| # | 監視項目 | 目的 |
|---|---|---|
| 1 | データ数、正例数などの統計値 | データ傾向の単純なシフトを確認する |
| 2 | モデルの平均予測値、logloss などの精度評価指標 | モデルの予測傾向に問題がないかを確認する |
| 3 | モデル特徴量重要度 | データに対してどの特徴量が大きく影響しているのかを確認する |
上記を一定期間にわたり時系列で確認します。
ポイントは、担当者が毎朝のコーヒータイムにさっと目を通すだけで確認が済むことを目指し、監視項目をできる限り少なく、時系列的な指標の監視のみに収めるようにしたことです。
ログテーブルの設計
マイクロアドの ML モデル学習バッチは Vertex AI Pipelines2 上で動作しており、学習バッチ内のコンポーネントから BigQuery にログを出力しています。
今回は、以下のようなテーブル設計を採用しました。
| キー名 | 形式 | 説明 |
|---|---|---|
| model_version | STRING | 予測モデルのバージョン名。マイクロアドでは複数のversionのモデルを学習する場合があるのでversionごとにログを記録できるようにする。 |
| timestamp | STRING | 学習バッチの実行時タイムスタンプ。YYYYMMDDhhmmss 形式(JST) |
| local_model_name | STRING | モデル分割粒度を _ で連結したモデル分割名。マイクロアドでは予測モデルを特定のセグメントごとに分割して学習することが多いため、その粒度ごとにログを記録できるようにする。 |
| subset_name | STRING | データのサブセット名。学習データ:train / 検証データ:valid / 評価データ:eval / キャリブレーションデータ:calib。データセットごとにログを分けて記録することで、後述のダッシュボードで train・valid・calib を横並びに比較できる |
| setting | JSON | バッチの実行情報(ハイパーパラメータや実行時の設定値など) |
| statistic | JSON | サブセットの統計値(データ数や正例数など) |
| metric | JSON | サブセットでの予測モデルの評価指標 |
| model_info | JSON | モデル情報(特徴量重要度など) |
| ext | JSON | 拡張情報。他のカラムに適切な格納先がない場合にここへ記録できる |
設計上工夫した点は以下です。
- それぞれの指標を 実行時刻 × model_version × local_model_name × subset_name ごとに個別に記録するようにした
- 監視内容を格納するカラムに JSON 型を採用した
指標を個別に記録するようにしたことで、任意の集約キーの組み合わせで指標の比較が行える設計になっています。
また、statistic・metric・model_info・ext といった監視内容カラムをすべて JSON 型とすることで、従来の「監視項目ごとに専用カラムを用意する」方法と比較して下記の利点があります。
- 監視項目の追加・変更時にテーブルのスキーマ変更やマイグレーションが不要になる
- 機能改修時に他モデルへ波及する対応が減り、開発コストを抑えられる
一例として、下記のように異なる構造のメトリクスを同一カラムに格納できます。
-- あるモデルの `metric` のログ例 { "metric": {"pr_auc": 0.712, "logloss": 0.0358, "normalized_entropy": 0.828, "calibration_score": 0.90} } -- 別のモデルの `metric` のログ例 { "metric": {"pr_auc": 0.712, "logloss": 0.0358, "precision": 0.80, "recall": 0.90, "f1": 0.85} }
Looker Studio によるダッシュボード設計
監視ダッシュボードとして、Google 提供の無料 BI ツール Looker Studio を採用しました。 採用理由は下記です。
| 利点 | 内容 |
|---|---|
| 連携 | BigQuery との連携が容易 |
| コスト | 無料で利用可能 |
| 共有 | ブラウザからチーム全員がいつでも確認可能 |
| 運用 | ノーコードでグラフやフィルタを作成でき、運用コストが低い |
ダッシュボードの設計方針
設計方針としてのポイントは、任意の指標について時系列でのシフト(変化)がないかを確認することに特化した点です。
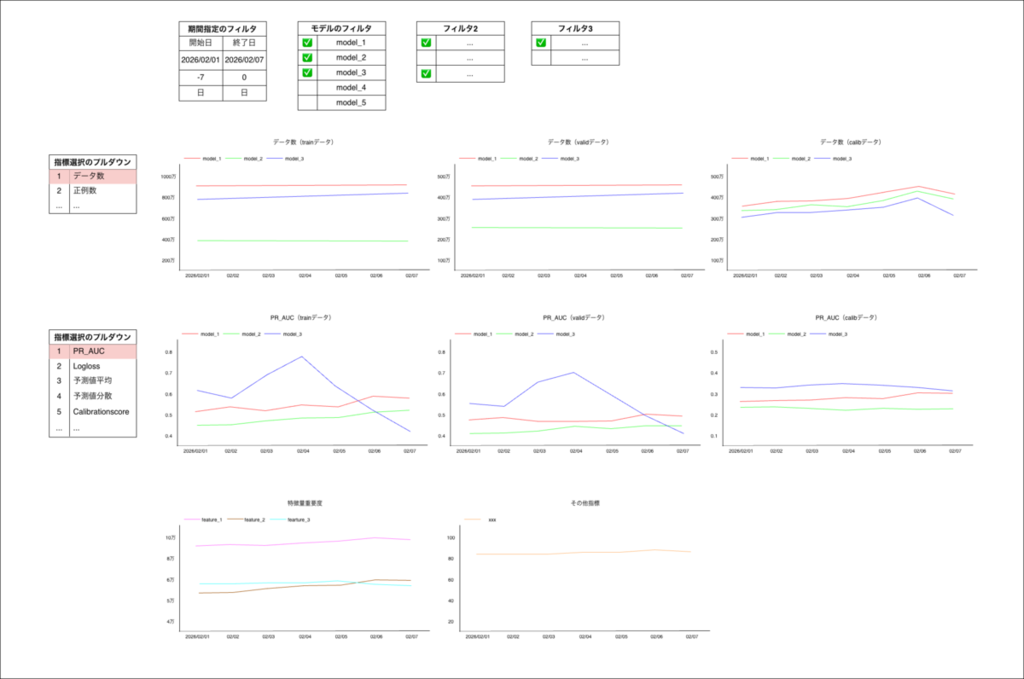
ダッシュボードの主な機能は以下の通りです。
- 各指標を train / valid / calib で横並び表示し、汎化性能やキャリブレーション後の過学習を確認
- 日付範囲フィルタで直近1週間〜1ヶ月など任意の期間を指定可能
- モデルの分割粒度や学習設定によるフィルタ機能
- 各指標をプルダウン選択で切り替え(全指標を網羅的に羅列せず監視コスト、保守コストを低減)
- デフォルトではデータ数や PR_AUC など重要指標のみ表示
- 特徴量重要度はモデル指定で表示(この値の変動 = 学習データのシフトを疑う)
これにより、数日に1回1分程度の確認で事前検知として十分な設計になっています。
実際のダッシュボード運用例
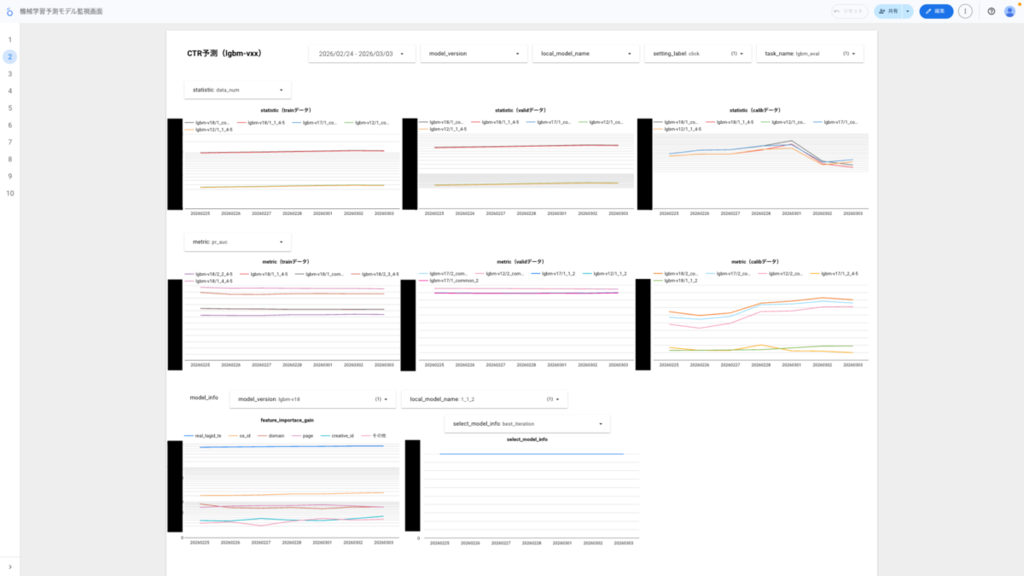
実運用上、このダッシュボードは、日々の傾向変化の事前確認と、障害発生時の初動調査の2つの目的で機能しています。
障害発生時の実際の活用事例として、ある学習データの正例数が数件にまで減少しアラートが通知されたケースを紹介します。
正例数減少のアラートが通知された場合、原因は以下2パターンに分かれ、それぞれ対応が異なります。
| # | 原因パターン | 対応 |
|---|---|---|
| 1 | 上流のデータ集計処理の障害 | ログ集計チーム・ビジネス側への発報と全面的な障害調査 |
| 2 | 案件が徐々になくなった結果の自然減少 | 該当の分割粒度での学習停止のみで対応 |
ダッシュボードで過去のデータ件数推移を確認し、1日で急激に下がった場合はパターン1、数週間かけて徐々に少なくなっていた場合はパターン2と判断するなど、上記の対応判断が即座に行え、迅速に対応方針を決定できました。
まとめ
| ポイント | 内容 |
|---|---|
| 監視の分割 | コンポーネントごとに適切な粒度で分割し、必要な項目を監視 |
| 要件整理 | 一般的な監視要件 × 実際のインシデント経験の両面から整理 |
| ログ記録 | 分割粒度ごとの個別ログ記録、JSON型カラムでスキーマ変更なしで監視項目の追加・変更が可能 |
| ダッシュボード | 簡潔に保ち、時系列でのシフト確認に特化 |
今後はアラートの自動化やより高度な異常検知の仕組みなど、改善を進めていきたいと考えています。本記事が MLOps における監視設計の参考になれば幸いです。
機械学習エンジニア絶賛採用中
最後に、マイクロアドでは問題設定からサーベイ、開発・運用まで裁量を持ってチャレンジしたい機械学習エンジニアを募集しています。
ご興味あれば是非以下の採用ページからご応募ください!
- Cathy Chen ほか『信頼性の高い機械学習 ― SRE原則を活用したMLOps』(井伊篤彦 ほか訳)、オライリー・ジャパン、2024年↩
- Google Cloud 上で ML パイプラインを構築できるワークフロー実行サービス。↩