はじめに
こんにちは、マイクロアドで機械学習エンジニアをしている大庭です。
前回の記事ではマイクロアドにおけるMLモデルの学習バッチのログ設計とその監視について紹介しました。
マイクロアドでは、学習バッチで定期的にMLモデルを更新し、そのパラメータをAPIが読み込んで配信に利用する構成が主流です。前回は学習バッチ側の監視について紹介しましたが、実際にリクエストを受けて推論を行うAPI側にも監視が必要になります。
今回の記事では予測API側の監視設計について、現在の運用と今後の展望をまとめていこうと思います。
監視要件の整理
MLシステムの監視要件は以下のように整理されます。
| データ収集 / ETLバッチ | 学習バッチ | 予測API | |
|---|---|---|---|
| ソフトウェア層 |
|
|
|
| データ層 |
|
||
| ML層 |
|
|
|
前回は学習バッチのML層(オフライン評価指標・特徴量重要度など)の監視を紹介しました。今回はこの中から予測APIのソフトウェア層とML層の監視を取り上げます。
APIの基本監視
予測APIのソフトウェア層の監視では、ゴールデンシグナル1と呼ばれる4つの指標を確認します。ゴールデンシグナルはGoogleのSRE本で提唱された概念で、サービスの健全性を測るうえで最低限見るべき指標です。
| シグナル | 概要 |
|---|---|
| Latency(レイテンシ) | リクエストへの応答時間 |
| Traffic(トラフィック) | リクエストの量、システムの負荷 |
| Errors(エラー率) | 失敗したリクエストの割合 |
| Saturation(サチュレーション) | CPUやメモリなどリソースの逼迫具合 |
ML予測APIであっても、まずはこれらの基本的なソフトウェア監視が整備されていることが前提になります。モデルの推論自体に問題がなくてもAPIのレイテンシが悪化していたりエラー率が上がっていたりすれば正しい予測を返せないためです。
ML特有の監視
予測APIのML層の監視としてはオンライン評価指標とビジネス指標の2つがあります。
オンライン評価指標
オンライン評価指標は本番環境で実際に推論した結果から算出されるモデルの性能指標です。学習バッチで算出するオフライン評価指標と異なり、実際の配信データに対するモデルの振る舞いを把握できます。
例としてCTR(広告クリック率)予測タスクでは以下のような指標があります。
| 指標 | 概要 |
|---|---|
| 平均CTR予測値 | モデルが出力するCTR予測値の平均 |
| カリブレーションスコア | 予測確率と実際のクリック率の一致度 |
| logloss / normalized entropy | モデルの予測精度を測る指標。予測値と実際に計測されるクリックに乖離がないかを確認する |
ビジネス指標
ビジネス指標はMLモデルの予測がビジネス上の成果にどう結びついているかを測る指標です。CTR予測タスクの例では以下のような指標が該当します。
| 指標 | 概要 |
|---|---|
| クリック数 | 広告のクリック数 |
| CPC(クリック単価) | 1クリックあたりの配信金額 |
| CPM(インプレッション単価) | 1,000インプレッションあたりの配信金額 |
ただし、ビジネス指標はMLモデル以外の要因(案件設定の変更、季節要因、広告主の予算変動など)の影響も大きく受けるため、モデル起因の問題かどうかの切り分けが難しいです。現状ビジネス指標についてはダッシュボードでの体系的な監視にまでは至っておらず、今後の展望として後述します。
監視基盤の構成
マイクロアドの広告配信システムUNIVERSE Adsでは、Elasticsearchにログを集約しKibanaで可視化、アラートをSlackに通知するという構成で監視を行っています。リソース監視(Saturation)についてはPrometheus + Grafanaの監視基盤をインフラチームが統合的に管理しています。
監視基盤の全体像についてはこちらの記事で詳しく紹介しているので、今回は予測APIの監視で利用している各コンポーネントの役割に絞って紹介します。
| コンポーネント | 役割 |
|---|---|
| Elasticsearch | APIのアクセスログや推論ログを集約・蓄積 |
| Kibana | Elasticsearchのデータをもとにダッシュボードを作成・可視化 |
| Grafana | インフラチームが管理するリソース監視ダッシュボード(CPU・メモリなど) |
| Pythonスクリプト | Elasticsearchのログを定期チェックし、閾値超過時にSlackアラートを送信 |
| Slack | アラート通知先 |
以降ではこのうちダッシュボードとアラートの設計について紹介します。
ダッシュボード設計
Latency・Traffic・Errors
ゴールデンシグナルのうちLatency・Traffic・Errorsの3つについてはKibanaダッシュボードで監視しています。APIのアクセスログをElasticsearchに集約し、以下のパネルを上から並べて表示しています。
| パネル | 確認内容 |
|---|---|
| アクセス件数 | リクエスト量(Traffic)の推移 |
| タイムアウト数 | タイムアウト発生数(Errors)の推移 |
| 平均レスポンス時間 | レスポンス時間(Latency)の推移 |
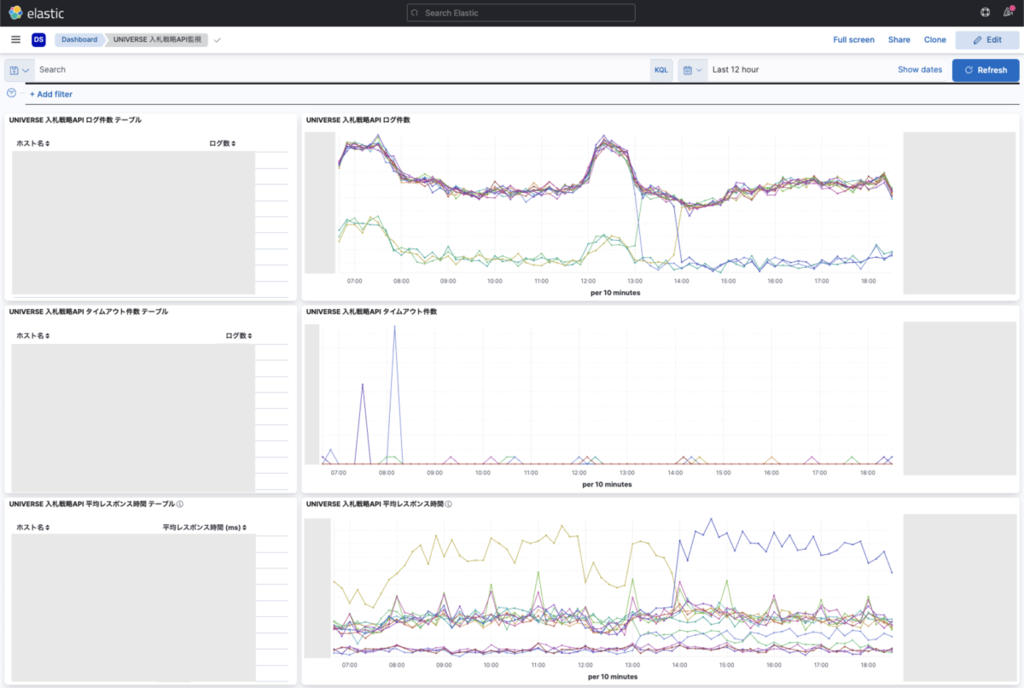
いずれも時系列グラフで表示しており、日常的な傾向と比較して異常がないかを一目で確認できるようにしています。
Saturation
Saturation(サチュレーション)は、CPU使用率やメモリ使用率など監視項目が多岐にわたり、インフラ寄りの要素も強いため、マイクロアドではインフラチームがPrometheus + Grafanaで統合的に管理しています。
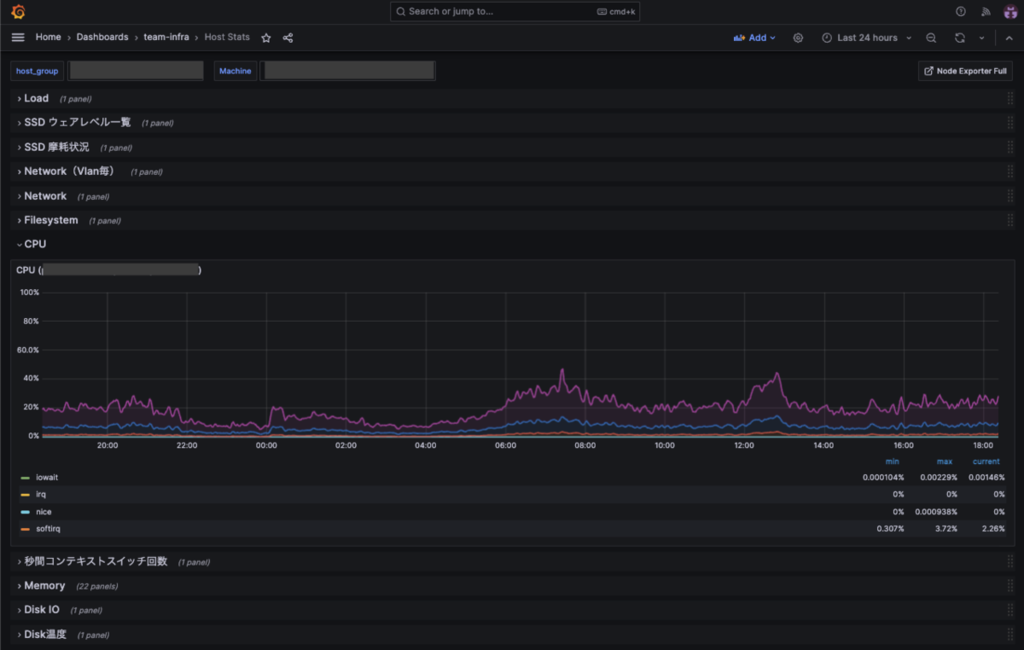
MLエンジニア側からはインフラチームに管理を委ねる形ですが、モデル更新時にメモリ使用量が急増するなどの問題が起きた際にはこのダッシュボードを参照してインフラチームと連携して対応しています。
アラート設計
マイクロアドではメインのコミュニケーションツールとしてSlackを利用しているため、アラートもSlackに通知しています。
予測APIのアラートはElasticsearchに蓄積されたログをPythonスクリプトで定期的にチェックし、閾値を超過した場合にSlackへ通知する仕組みです。
以下はCTR予測で運用しているオンライン評価指標アラートの一例です。配信粒度ごとにCTR予測値の推移を確認し、閾値以上の予測平均が計測された場合にアラートが発報されるようにしています。

これにより、モデルの急激な予測傾向の変化による配信事故に早急に気づけるようになっています。例えばある配信粒度でCTR予測値の平均が急上昇した場合、入札価格が高騰し広告主のコスト効率が悪化する可能性がありますが、このようなケースをアラートで早期に検知し、モデルのロールバックや配信停止といった対応を迅速に行えるようにしています。
ただし現在は静的な閾値によるアラート発火のみとなっています。予測傾向の妥当な値は配信粒度や時間軸によって動的に変わるため、今後の展望として時系列的な変化を加味した動的なアラート発火条件を検討しています。
今後の展望
ここまで紹介した監視は現時点で機能していますが、まだ改善の余地がある部分もあります。今後取り組みたいテーマを2つ紹介します。
ビジネス指標のダッシュボード監視
先述のとおりCTR予測に関連するビジネス指標(クリック数・CPC・CPMなど)は現時点ではダッシュボードでの体系的な監視にまでは至っていません。
ビジネス指標はMLモデルの予測がビジネス成果に結びついているかを測る最終的な指標です。これを継続的にモニタリングすることで「モデルの精度は良いのにビジネス成果に繋がっていない」といった問題の早期発見に繋がります。
一方でビジネス指標はモデル以外の要因(案件設定の変更、季節要因など)の影響も大きく受けるため、単純な閾値監視ではなく要因分解を考慮した可視化が必要です。こうした設計を検討し段階的に導入していきたいと考えています。
動的なアラート条件の導入
現在のアラートは静的な閾値に基づいていますが、広告配信の特性上、時間帯や曜日、配信粒度によって予測値の正常な範囲は異なります。例えば深夜帯とピーク時間帯ではCTRの傾向が大きく異なるため、同じ閾値で判定すると誤報や見逃しが発生しやすくなります。
今後は過去の推移をベースにした動的な閾値設定や、時系列的な変化率をトリガーとしたアラート条件の導入を検討しています。
まとめ
今回の記事ではマイクロアドにおけるML予測APIの監視設計について紹介しました。
| ポイント | 内容 |
|---|---|
| 監視要件の整理 | ゴールデンシグナル(ソフトウェア層)とML特有の指標(ML層)に分けて整理 |
| 監視基盤 | Elasticsearch + Kibanaでログ可視化、Grafanaでリソース監視、Pythonスクリプトでアラート |
| ダッシュボード | Kibanaでアクセス件数・タイムアウト数・レスポンス時間を時系列監視 |
| アラート | CTR予測値の閾値超過をSlack通知。配信粒度ごとに監視 |
| 今後の展望 | ビジネス指標のダッシュボード化、動的なアラート条件の導入 |
前回の学習バッチ監視と合わせて、学習からサービングまで一貫した監視体制を構築することでMLシステムの安定運用を目指しています。この記事がML APIの監視設計の参考になれば幸いです。
機械学習エンジニア絶賛採用中
最後に、マイクロアドでは問題設定からサーベイ、開発・運用まで裁量を持ってチャレンジしたい機械学習エンジニアを募集しています。
ご興味あれば是非以下の採用ページからご応募ください!