こんにちは. マイクロアドで機械学習エンジニアをしている崎下です。 時間によって変わる広告配信リクエスト量に応じて適切に配信量を調整するためのシステムの開発を担当しています。
今回は時間変化するデータの評価手法としてカルマンフィルタについての勉強会を実施したため、その内容をまとめてご紹介します。
本記事の構成
本記事では、時間変化するシステムの状態を評価するための手法として、カルマンフィルタとその拡張手法を取り上げます。 基礎となる状態空間モデルの定式化から始め、以下の流れでまとめます。 参考書として樋口知之『データ同化入門』を主に参照しています。
- 状態空間モデル
時系列観測データの背後に隠れた状態を仮定し、モデル化する「状態空間モデル」の定義や用語、推定手法の概要を説明します - カルマンフィルタ
状態空間モデルに数学的な仮定を加えることで簡単な計算で適用可能となる「カルマンフィルタ」の理論とアルゴリズムを紹介します - 拡張カルマンフィルタとアンサンブルカルマンフィルタ
仮定を緩和し、より広い範囲に適用できる「拡張カルマンフィルタ」や「アンサンブルカルマンフィルタ(EnKF)」の考え方と計算方法を解説します - 粒子フィルタと融合粒子フィルタ
さらに仮定を緩めた「粒子フィルタ(PF)」と、その計算上の課題を解決する「融合粒子フィルタ(MPF)」について説明します - 数値実験
実践例として、シミュレーションデータに対して各手法を適用した結果を紹介します
- 本記事の構成
- 1. 状態空間モデル
- 2. カルマンフィルタ
- 3. 拡張カルマンフィルタとアンサンブルカルマンフィルタ
- 4. 粒子フィルタ(PF)と融合粒子フィルタ(MPF)
- 5. 数値実験
- おわりに
- 参考文献
1. 状態空間モデル
モデル定義
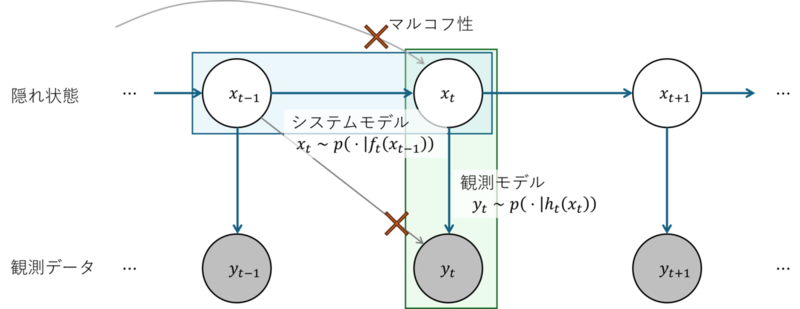
観測データ $\boldsymbol y _ 1, \ldots, \boldsymbol y _ T$ の背後に、観測されない隠れ状態 $\boldsymbol x _ 1, \ldots, \boldsymbol x _ T$ が存在すると考えます。
- システムモデル:隠れ状態 $\boldsymbol x _ t$ は、前時刻の状態 $\boldsymbol x _ {t-1}$ の関数 $f _ t$ と、システムノイズ $\boldsymbol v _ t$ (モデルが考慮しきれていない未知変数の影響や、差分計算による数値誤差など)によって時間発展する $$ \boldsymbol x _ t = f _ t(\boldsymbol x _ {t-1})+\boldsymbol v _ t $$
- 観測モデル:観測データ $\boldsymbol y _ t$ は、同時刻の隠れ状態 $\boldsymbol x _ t$ に依存する関数 $h _ t$ と、観測ノイズ $\boldsymbol w _ t$ で記述される $$ \boldsymbol y _ t=h _ t(\boldsymbol x _ t)+\boldsymbol w _ t $$
この2つを連立したモデルを状態空間モデルと呼びます。 時刻 $t-1$ 以前の隠れ状態が現在時刻$t$の状態に影響したり、観測データが現在時刻以外の隠れ状態から影響したりすることのない櫛状のモデルが特徴です。
ℹ️補足:周期変動、外部パラメータの取り入れ方
周期変動、外部パラメータなどはそれらを含めた多次元の状態空間ベクトルに含めてしまうことで状態空間モデルに当てはめることができます。
$$
\tilde{\boldsymbol {x}} _ t=\begin{pmatrix} x _ t, x _ {t-1}, \cdots, x _ {t-7}, \theta_1, \theta_2, \cdots \end{pmatrix}^\top
$$
一定期間の観測データ $\boldsymbol y _ {1:s}\; (=\{\boldsymbol y _ {t}\} _ {t=1} ^ s)$ から隠れた真の値 $\boldsymbol x _ t$ の分布 $p(\boldsymbol x _ t \,|\, \boldsymbol y _ {1:s})$ を求めることがこのモデルの目的です。
用語
- 予測分布:観測データより先の時刻の分布を予測する $t>s$
- フィルタ分布:観測データと同じ時刻の分布を求める $t=s$
- 平滑化分布:観測データ以前に遡って分布を求める $t<s$
下にいくほど、より多くのデータから分布を求めるため、より高い精度の推定になります。
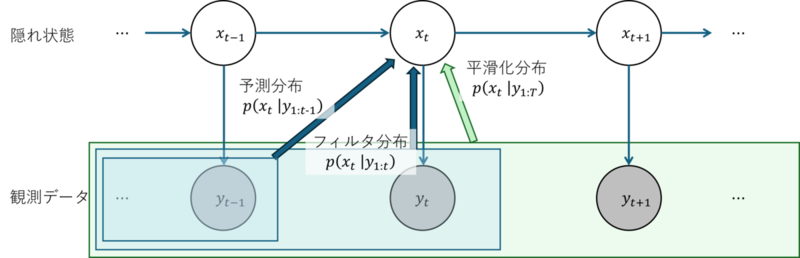
原理的には、任意のモデルで一期ごとに予測・フィルタ・平滑化のステップを繰り返すことで、観測データから隠れ状態の分布を厳密に求めることができます。 しかし、高次元の積分計算が必要になるため、必ずしも解析的に解けるとは限りません。
- 一期先予測
1期前のフィルタ分布 $p(\boldsymbol x _ {t-1}\,|\, \boldsymbol y _ {1:t-1})$ とシステムモデル $p(\boldsymbol{x} _ t\,|\, \boldsymbol x _ {t-1})$
→ 現在時刻の予測分布 $p(\boldsymbol x _ t\,|\, \boldsymbol y _ {1:t-1})$ $$ p(\boldsymbol x _ t\;|\; \boldsymbol y _ {1:t-1})=\int p(\boldsymbol x _ t\;|\; \boldsymbol x _ {t-1})p(\boldsymbol x _ {t-1}\;|\;\boldsymbol y _ {1:t-1})d\boldsymbol x _ {t-1} $$ - フィルタ
現在時刻の予測分布 $p(\boldsymbol x _ t\,|\, \boldsymbol y _ {1:t-1})$と観測モデル $p(\boldsymbol{y} _ t\,|\, \boldsymbol x _ t)$
→ 現在時刻のフィルタ分布 $p(\boldsymbol x _ t\,|\, \boldsymbol y _ {1:t})$ $$ p(\boldsymbol x _ t\;|\;\boldsymbol y _ {1:t})=\frac{p(\boldsymbol y _ t\;|\; \boldsymbol x _ {t})p(\boldsymbol x _ {t}\;|\;\boldsymbol y _ {1:t-1})}{\int p(\boldsymbol y _ t\;|\; \boldsymbol x _ {t})p(\boldsymbol x _ {t}\;|\;\boldsymbol y _ {1:t-1}) d\boldsymbol x _ {t}} $$ - 固定点1平滑化
1期後の平滑化分布 $p(\boldsymbol x _ {t+1}\,|\, \boldsymbol y _ {1:T})$ と各時刻のシステムモデル・観測モデル
→ 現在時刻の平滑化分布 $p(\boldsymbol x _ {t}\,|\, \boldsymbol y _ {1:T})$ $$ \begin{align} p(\boldsymbol x _ t, \boldsymbol x _ s\;|\; \boldsymbol y _ {1:t}) &= \frac{p(\boldsymbol y _ t\;|\; \boldsymbol x _ {t})p(\boldsymbol x _ {t},\boldsymbol x _ s\;|\;\boldsymbol y _ {1:t-1})}{\iint p(\boldsymbol y _ t\;|\; \boldsymbol x _ {t})p(\boldsymbol x _ {t},\boldsymbol x _ s\;|\;\boldsymbol y _ {1:t-1}) d\boldsymbol x _ {t}d\boldsymbol x _ {s}} \\ p(\boldsymbol x _ s\;|\; \boldsymbol y _ {1:t}) &= \int p(\boldsymbol x _ t,\boldsymbol x _ s\;|\; \boldsymbol y _ {1:t}) d\boldsymbol x _ t \end{align} $$
数学的に扱いやすい仮定(線形性、ガウス性)を置くことで、この多重積分を簡単に計算できるようにしたのがカルマンフィルタです。
ℹ️補足:パラメータの推定
補足:パラメータの推定
モデル $f _ t, h _ t$ が持つパラメータやノイズの形状パラメータなどは、状態空間モデルでは固定値として扱います。 そのため、これらのパラメータはモデルの外側で推定する必要があります。
パラメータ $\boldsymbol\theta$ のもとで観測データが実際に生成する確率の対数尤度 $$ \ell(\boldsymbol\theta)=\log p(\boldsymbol{y} _ {1:T}\,|\, \boldsymbol\theta)=\sum _ {t=1} ^ T \log p(\boldsymbol{y} _ t\,|\,\boldsymbol{y} _ {1:t-1}, \boldsymbol\theta) $$ を最大化するような $\boldsymbol\theta$ を求めます。
尤度がパラメータ空間上で凸であれば勾配降下法で最適値を求めることができます。 しかし、一般には凸でない場合も多いため遺伝的アルゴリズムなどによって探索的に求める必要があります。
他に、パラメータ確率変数と見なして状態ベクトルに追加することでパラメータごと推定するというアプローチや、外部パラメータに対する尤度自体を目的関数としたデータ同化手法として「アジョイント法」が知られています。
2. カルマンフィルタ
状態空間モデルにおいて、システムモデル・観測モデルがともに線形であり、かつ各ノイズがガウス分布であると仮定します。
- 時系列観測データ $\boldsymbol y _ t\in\mathbb{R} ^ l$ ($l$ 次元)
- システムモデル
$$
\boldsymbol x _ t=F _ t \boldsymbol x _ {t-1} + G _ t\boldsymbol v _ t
$$
- 状態ベクトル: $\boldsymbol x _ t\in\mathbb{R} ^ k$ ($k$ 次元)
- 初期状態: $\boldsymbol x _ 0\in\mathbb{R} ^ k$
- システムノイズ: $\boldsymbol v _ t\in\mathbb{R} ^ m \sim \mathcal{N}[{\boldsymbol 0},Q _ t]$
- $F _ t\in \mathbb{R} ^ {k\times k}$, $G _ t\in \mathbb{R} ^ {k\times m}$ 2は時間発展による変換を表す決定的な行列。$f _ t$ に相当する。
- 観測モデル
$$
\boldsymbol y _ t=H _ t\boldsymbol x _ t+\boldsymbol w _ t
$$
- 観測ノイズ: $\boldsymbol w _ t\in\mathbb{R} ^ l \sim \mathcal{N}[{\boldsymbol 0},R _ t]$
- $H _ t\in\mathbb{R} ^ {l\times k}$ は観測による変換を表す決定的な行列。$h _ t$ に相当する。
このとき、ガウス分布の合成である予測分布・フィルタ分布・平滑化分布もすべてガウス分布になることがわかります。 したがって、各分布の平均と分散共分散行列を求めるだけで完全な情報が得られます。
時刻 $s$ までの観測データ $\boldsymbol{y} _ {1:s}$ から求められる時刻 $t$ での隠れ状態 $x _ t$ の分布が期待値 $\overline{\boldsymbol x} _ {t|s}$ と分散共分散行列 ${V _ {t|s}}$ を持つガウス分布 $\mathcal{N}(\overline{\boldsymbol x} _ {t|s}, {V _ {t|s}})$ で表されるとすると、フィルタ分布・予測分布は以下のように表せます。
- フィルタ分布: $$ \boldsymbol x _ {t-1}\,|\,\boldsymbol y _ {1:t-1} \sim\mathcal{N}(\overline{\boldsymbol x} _ {t-1|t-1}, {V _ {t-1|t-1}}) $$
- 予測分布: $$ \boldsymbol x _ {t}\,|\, \boldsymbol y _ {1:t-1} \sim\mathcal{N}(\overline{\boldsymbol x} _ {t|t-1}, {V _ {t|t-1}}) $$
- (平滑化分布は割愛します)
これで、状態空間モデルの隠れ状態の分布関数を求めるという問題が、ベクトル $\overline{\boldsymbol x} _ {t|s}$ と行列 ${V _ {t|s}}$ を求める問題に帰着することができました。 このとき、以下のアルゴリズムで各時刻のパラメータを逐次的に求めることができます。
- 初期条件 $\overline{\boldsymbol x} _ {0|0}, {V _ {0|0}}$ を与える
- $t=1, \dots, T$ について以下を行う
- 一期先予測 $$ \begin{align} \overline{\boldsymbol x} _ {t|t-1} &= F _ t \overline{\boldsymbol x} _ {t-1|t-1}\\ {V _ {t|t-1}} &= F _ t {V _ {t-1|t-1}}F _ t^\top+G _ tQ _ tG _ t^\top \end{align} $$
- フィルタ $$ \begin{align} K _ t &= {V _ {t|t-1}}H _ t^\top(H _ t {V _ {t|t-1}}H _ t^\top+R _ t) ^ {-1}\\ \overline{\boldsymbol x} _ {t|t} &= \overline{\boldsymbol x} _ {t|t-1}+K _ t(y _ t-H _ t\overline{\boldsymbol x} _ {t|t-1})\\ {V _ {t|t}} &= {V _ {t|t-1}}-K _ tH _ t {V _ {t|t-1}} \end{align} $$
$K _ t$ は計算途中で現れる行列で、カルマンゲインと呼ばれます。
ℹ️補足:データ同化文脈でのカルマンゲインの解釈
補足:データ同化文脈でのカルマンゲインの解釈
データ同化の目的は(同化前の)予測値 $ x ^ b $ を観測データ $y$ と混ぜ合わせて良しなに間を取った予測値 $ x ^ a $ を作ることです。
予測値が分散 $\sigma _ a ^ 2$、観測値が分散 $\sigma _ y ^ 2$ の信頼度を持っていると考えると、統計的に合成することで以下の式が得られます。 $$ \begin{align} x ^ a &= \frac{1/\sigma _ a ^ 2}{1/\hat\sigma ^ 2} x ^ b + \frac{1/\sigma _ y ^ 2}{1/\hat\sigma ^ 2} y = x ^ b+\frac{1/\sigma _ y ^ 2}{1/\hat{\sigma} ^ 2}(y-x ^ b)\\ \hat{\sigma} ^ 2 &= \frac{\sigma _ a ^ 2\sigma _ y ^ 2}{\sigma _ a ^ 2+\sigma _ y ^ 2} \end{align} $$
観測データ、予測値をそれぞれ多次元化すると $$ \boldsymbol x ^ a = \boldsymbol x ^ b+K(\boldsymbol y-h(\boldsymbol x ^ b)) $$ の形になります。 カルマンゲイン $K$ は予測値に対する観測値の係数 $\frac{1/\sigma _ y ^ 2}{1/\sigma _ b ^ 2+1/\sigma _ y ^ 2}$ に対応するものです。
3. 拡張カルマンフィルタとアンサンブルカルマンフィルタ
カルマンフィルタの仮定条件を緩めた拡張手法を紹介します。
拡張カルマンフィルタ
ここではシステムモデルが非線形、観測モデルは線形な状態空間モデルを考えます。
$$ \begin{align} \boldsymbol x _ t &= f _ t(\boldsymbol x _ {t-1}, \boldsymbol v _ t) \tag{System}\\ \boldsymbol y _ t &= H _ t \boldsymbol x _ t + \boldsymbol w _ t \tag{Observation} \end{align} $$
観測ノイズはガウス性を仮定( $\boldsymbol w _ t \sim \mathcal{N}(0, R _ t)$ )しますが、システムモデルは任意の分布でよい( $\boldsymbol v _ t\sim q _ t(\cdot)$ )です。
カルマンフィルタを適用するために、(System)式をテイラー展開して、線形モデルとして近似します。 $\boldsymbol x$、$\boldsymbol v$ に対するヤコビ行列 $$ \begin{align} \hat{F _ t}&=\left.\frac{\partial f _ t}{\partial \boldsymbol{x} _ {t-1}^\top}\right| _ {(\boldsymbol x _ {t-1}, \boldsymbol v _ t)=(\overline{\boldsymbol x} _ {t-1|t-1}, \overline{\boldsymbol v _ t})}\\ \hat{G _ t}&=\left.\frac{\partial f _ t}{\partial \boldsymbol{v} _ {t-1}^\top}\right| _ {(\boldsymbol x _ {t-1}, \boldsymbol v _ t)=(\overline{\boldsymbol x} _ {t-1|t-1}, \overline{\boldsymbol v _ t})} \end{align} $$ を使って、一期先予測を $$ \begin{align} \overline{\boldsymbol x} _ {t|t-1} &= f _ t( \overline{\boldsymbol x} _ {t-1|t-1}, \boldsymbol{v} _ t)\\ {V _ {t|t-1}} &= \hat F _ t {V _ {t-1|t-1}}\hat F _ t^\top+\hat G _ tQ _ t\hat G _ t^\top \end{align} $$ と置き換えればカルマンフィルタと同様に計算できます3。
しかし、$f _ t$ が複雑な場合は微分を数値的に求めるのが難しいこと、行列計算が特異的になることから、拡張カルマンフィルタの適用が難しい場合があります。
アンサンブル近似
以降で扱う近似手法を導入します。 この近似の目的は、無限の情報を持つ確率分布関数 $p(x)$ を $N$ 個のデータで表すことです。 分布 $p(x)$ を、ここから得られた $N$ 個のサンプル $\{x ^ {(i)}\} _ {i=1} ^ N$ を用いて $$ p(x) \mathrel{\dot{=}} \frac{1}{N}\sum _ {i=1} ^ N\delta(x-x ^ {(i)}) $$ と近似します。この近似をアンサンブル近似あるいはモンテカルロ近似と呼びます。
これを用いると、 $$ \begin{align} \mathbb{E} _ p[f(x)] &= \int f(x) p(x)dx\\ &\mathrel{\dot{=}} \int f(x)\left(\frac{1}{N}\sum _ {i=1} ^ N\delta(x-x ^ {(i)})\right)dx\\ &= \frac{1}{N}\sum _ {i=1} ^ N\int f(x)\delta(x-x ^ {(i)}) dx\\ &= \frac{1}{N}\sum _ {i=1} ^ N f(x ^ {(i)}) \end{align} $$ のようにサンプルの関数値の和で期待値を表すことができます。
ℹ️補足:アンサンブル近似のイメージ
補足:アンサンブル近似のイメージ
例えば $p(x)$ が混合ガウス分布であることがわかっていれば、いくつかの正規分布の線形結合で表すことができます。
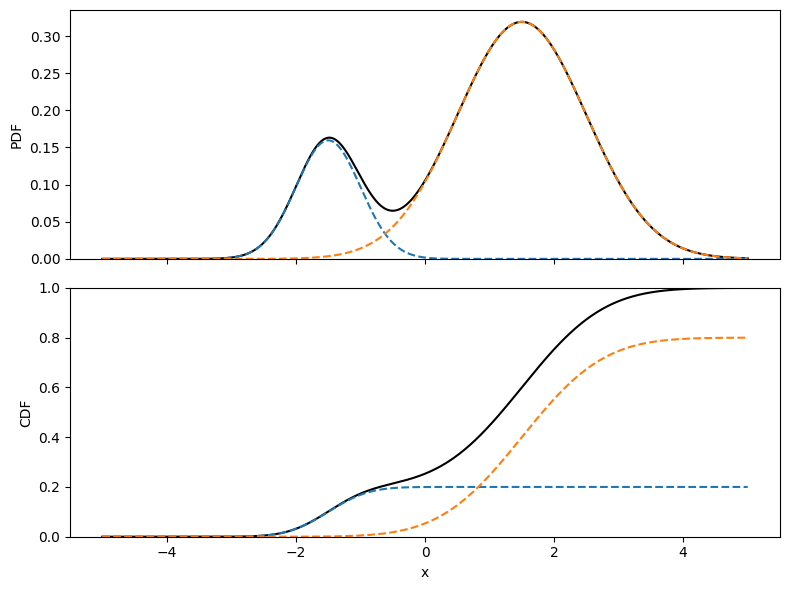
一般に、(性質の良い関数であれば)適当な固定値 $\sigma$ と、適切に決めた $\mu_k$ を中心とする多数の正規分布の線形結合として近似的に表すことができます。 $$ p(x) \approx \frac{1}{N}\sum _ k \mathcal{N}(x; \mu _ k, \sigma ^ 2) $$
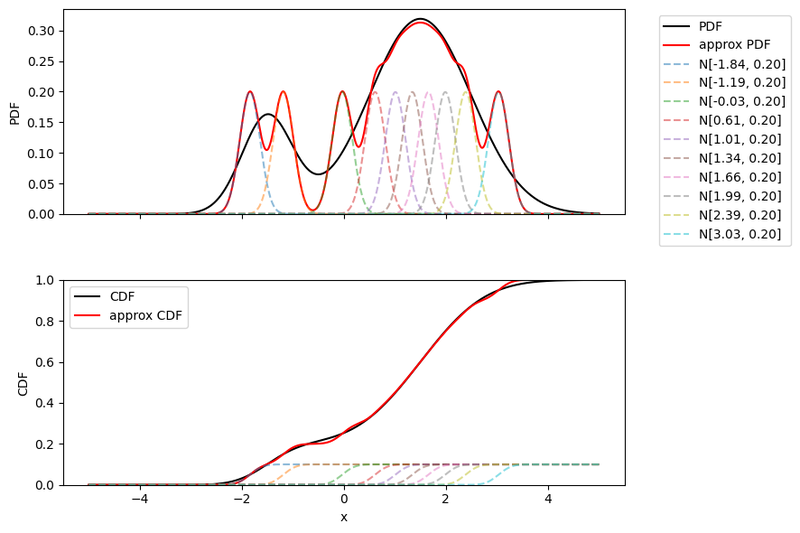
ここで $\sigma\to+0$ の極限をとって、正規分布の代わりにデルタ関数 $\delta(x-\mu _ k)$ を使っても同様の近似ができます。
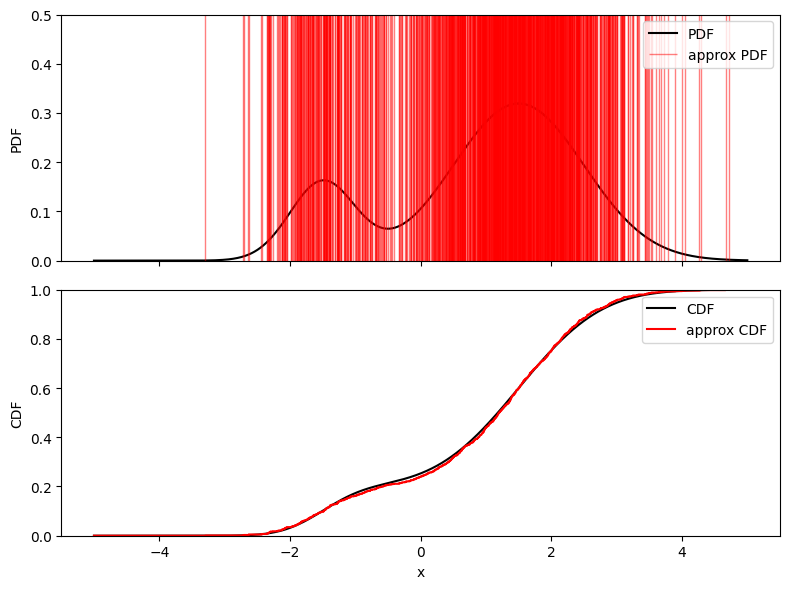
近似が成立するうまい $\{ \mu _ k \}$ の決め方として $p(x)$ からサンプリングするという方法が知られています。 $$ \hat{p}(x)=\frac{1}{N}\sum _ {k=1} ^ N\delta(x-\mu _ k) $$ これがアンサンブル近似あるいはモンテカルロ近似です。 確率分布を逐次更新していく手法と相性が良く、今回紹介するアンサンブルカルマンフィルタやマルコフ連鎖モンテカルロ法4のベースとなっています。
アンサンブルカルマンフィルタ(EnKF)
分布の平均値と分散共分散行列を計算する代わりに、$N$ 個のサンプルで近似的に分布を求める手法です。
時刻 $t-1$ でのフィルタ分布が $N$ 個のメンバー $\{\hat{\boldsymbol x} _ {t-1|t-1} ^ {(i)}\} _ {i=1} ^ N$ で表されている $$ p(\hat{\boldsymbol x} _ {t-1}\;|\;\boldsymbol y _ {1:t-1})\mathop{\dot{=}}\frac{1}{N}\sum _ {i=1} ^ N\delta(\boldsymbol x _ {t-1}-\hat{\boldsymbol x} _ {t-1|t-1} ^ {(i)}) $$ とき、このアンサンブルと時刻 $t$ での観測 $\boldsymbol y _ t$ から次の時刻のフィルタ分布を近似的に表せる $$ p(\hat{\boldsymbol x} _ {t}\;|\;\boldsymbol y _ {1:t})\mathop{\dot{=}}\frac{1}{N}\sum _ {i=1} ^ N\delta(\boldsymbol x _ {t}-\hat{\boldsymbol x} _ {t|t} ^ {(i)}) $$ ようなサンプル列 $\{\hat{\boldsymbol x} _ {t|t} ^ {(i)}\} _ {i=1} ^ N$ を求める手続きがアンサンブルカルマンフィルタです。
EnKFアルゴリズム
カルマンフィルタにおける一期先予測、フィルタのステップを以下で置き換えることで同様に計算できるようになります。
- 一期先予測:各サンプルにシステムモデルを適用する $$ \boldsymbol{x} _ {t|t-1} ^ {(i)}=f _ t(\boldsymbol{x} _ {t-1|t-1} ^ {(i)}, \boldsymbol{v} _ t ^ {(i)}),\quad \boldsymbol{v} _ t ^ {(i)}\sim q _ t(\boldsymbol{v} _ t) $$
- フィルタ:アンサンブルが表す分布からカルマンゲインを求め、各サンプルに適用する $$ \begin{align} \check{\boldsymbol{x}} _ {t|t-1} ^ {(i)} &= \boldsymbol{x} _ {t|t-1} ^ {(i)}-\frac{1}{N}\sum _ {j=1} ^ N\boldsymbol{x} _ {t|t-1} ^ {(j)}\\ \hat{V} _ {t|t-1} &= \frac{1}{N-1}\sum _ {j=1} ^ N\check{\boldsymbol{x}} _ {t|t-1} ^ {(j)}\check{\boldsymbol{x}} _ {t|t-1} ^ {(j)\top}\\ \check{\boldsymbol{w}} _ t ^ {(i)} &= \boldsymbol{w} _ t ^ {(i)}-\frac{1}{N}\sum _ {j=1} ^ N \boldsymbol{w} _ t ^ {(j)}\\ \hat{R} _ t &= \frac{1}{N-1}\sum _ {j=1} ^ N \check{\boldsymbol{w}} _ t ^ {(j)}\check{\boldsymbol{w}} _ t ^ {(j)\top}\\ \hat{K} _ t &= \hat{V} _ {t|t-1}H _ t^\top(H _ t\hat{V} _ {t|t-1}H _ t^\top+\hat{R} _ t) ^ {-1}\\ \boldsymbol{x} _ {t|t} ^ {(i)}&= \boldsymbol{x} _ {t|t-1} ^ {(i)}+\hat{K} _ t(\boldsymbol{y} _ t+\check{\boldsymbol{w}} _ t ^ {(i)}-H _ t\boldsymbol{x} _ {t|t-1} ^ {(i)}) \end{align} $$
4. 粒子フィルタ(PF)と融合粒子フィルタ(MPF)
粒子フィルタ(PF)
非ガウス性や、隠れ状態と観測の間が非線形な場合にも適用できるよう、さらにアンサンブル近似を適用して拡張した粒子フィルタ(Particle Filter)を紹介します。 別名としてモンテカルロフィルタ・ブートストラップフィルタ・sampling importance resampling (SIR)などとも呼ばれます。
PFアルゴリズム
- アンサンブル $\{\boldsymbol x _ {0|0} ^ {(i)}\} _ {i=1} ^ N$ を初期分布 $\boldsymbol x ^ {(i)}\sim p(\boldsymbol x _ 0)$ から生成する
- 時間ステップ $t=1, \dots, T$ について以下を繰り返す
- 一期先予測:各 $i$ について、予測分布のアンサンブル $\boldsymbol x _ {t|t-1} ^ {(i)}\sim p(\boldsymbol x _ t \;|\; \boldsymbol x _ {t-1|t-1} ^ {(i)} )$ を生成する
- 観測の尤度 $\lambda _ t ^ {(i)}=p(\boldsymbol y _ t \;|\; \boldsymbol x _ {t|t-1} ^ {(i)})$ を計算する
- フィルタ:各粒子が $\beta _ t ^ {(i)}=\lambda _ t ^ {(i)}/(\sum _ j \lambda _ t ^ {(j)})$ の確率で抽出されるよう $N$ 回の復元抽出を行い、得られた $N$ 個のサンプルをフィルタ分布のアンサンブル $\{\boldsymbol x _ {t|t} ^ {(i)}\} _ i$ とする
観測分布からのサンプリングを尤度からのブートストラップサンプリング5で近似することで、ガウス分布に限らない一般の分布を扱えるようになります。
融合粒子フィルタ(MPF)
粒子フィルタは復元抽出を繰り返すため、徐々に元々同じサンプルであった粒子の複製が増えていき、分布の近似精度が低下していく「アンサンブルの退化」という問題があります。 この問題に対処するための方策として様々なものが提案されていますが、その1つとして『データ同化入門』の筆者らが提案した「融合粒子フィルタ(Merging Particle Filter)」を紹介します。
MPFアルゴリズム
- アンサンブル $\{\boldsymbol x _ {0|0} ^ {(i)}\} _ {i=1} ^ N$ を初期分布 $\boldsymbol x ^ {(i)}\sim p(\boldsymbol x _ 0)$ から生成する
- 時間ステップ $t=1, \dots, T$ について以下を繰り返す
- 一期先予測:各 $i$ について、予測分布のアンサンブル $\boldsymbol x _ {t|t-1} ^ {(i)}\sim p(\boldsymbol x _ t \;|\; \boldsymbol x _ {t-1|t-1} ^ {(i)} )$ を生成する
- 観測の尤度 $\lambda _ t ^ {(i)}=p(\boldsymbol y _ t \;|\; \boldsymbol x _ {t|t-1} ^ {(i)})$ を計算する
- 各粒子が $\beta _ t ^ {(i)}=\lambda _ t ^ {(i)}/(\sum _ j \lambda _ t ^ {(j)})$ の確率で抽出されるよう $n\times N$ 回の復元抽出を行い、サンプル列 $\{ \grave{\boldsymbol x} ^ {(1,1)}, \dots, \grave{\boldsymbol x} ^ {(n,1)}, \dots, \grave{\boldsymbol x} ^ {(1,N)}, \dots, \grave{\boldsymbol x} ^ {(n,N)} \}$ を生成する
- フィルタ:$\{ \grave{\boldsymbol x} ^ {(j,i)} \}$ から $n$ 個ずつサンプルを取り出し、その”重み付き平均”6を取ったものをフィルタ分布のアンサンブル $\{\boldsymbol x _ {t|t} ^ {(i)}\} _ {i=1} ^ N$ とする。 $$ \boldsymbol x _ {t|t} ^ {(i)} = \sum _ {j=1} ^ n\alpha _ j \grave{\boldsymbol x} ^ {(j,i)} $$ ここで、平均の重み $\alpha _ j$ は以下を満たすように定める。 $$ \sum _ {j=1} ^ n \alpha _ j = 1, \ \sum _ {j=1} ^ n \alpha ^ 2 _ j = 1 $$ (例えば $n=3$ なら $(1/3-1/\sqrt3, 1/3, 1/3+1/\sqrt3)$ などがこれを満たす)
5. 数値実験
簡単なモデルのシミュレーションデータにデータ同化手法を適用して手法を比較します。
シミュレーションデータの生成
ローレンツモデル7による模擬実験を行います。 これは以下のような微分方程式で表される時間発展系です。 $$ \begin{align} \frac{dx}{dt} &= -s(x-y)\\ \frac{dy}{dt} &= rx-y-xz\\ \frac{dz}{dt} &= xy-bz \end{align} $$
例として、$s=10, r=28, b=8/3$ とします。
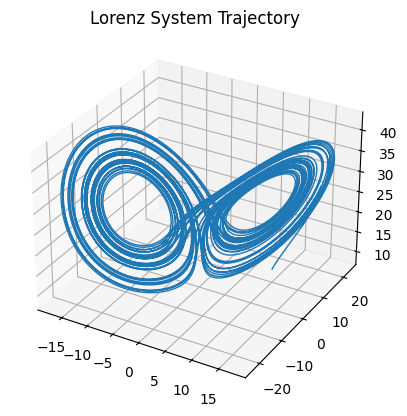
シミュレーションデータを $t=0.2$ 間隔で取得し、 $\mathcal{N}(\boldsymbol{0}, 2.0 ^ 2\cdot I _ 3)$ のノイズを加えたものを観測データとします。
同化モデル
状態空間モデルとして以下の時間発展系を用いて、EnKF、PF、MPFを適用した結果を比較します。 $$ \begin{align} \boldsymbol{x} _ t &= \boldsymbol{x} _ {t-1}+\int _ {\tau _ {t-1}} ^ {\tau _ {t}} \frac{d\boldsymbol{x}}{d\tau} d\tau +\boldsymbol{v} _ t,\ \boldsymbol{v} _ t\sim\mathcal{N}(\boldsymbol{0}, 0.1 ^ 2\cdot I _ 3)\\ \boldsymbol{y} _ t &= \boldsymbol{x} _ t + \boldsymbol{w} _ t,\ \boldsymbol{w} _ t\sim\mathcal{N}(\boldsymbol{0}, 4.0 ^ 2\cdot I _ 3) \end{align} $$ ※ここでは積分の精度を $\Delta t=0.001\to 0.01$ に落としています。システムモデルは完全でないことの表現です。
システムモデルが線形ではないのでカルマンフィルタは適用できませんが、観測モデルは線形・ガウスなのでEnKF以降の拡張手法が適用可能です。 PFはアンサンブル退化によって推定がうまくいかない一方、MPFにすることで解決することを確認します。
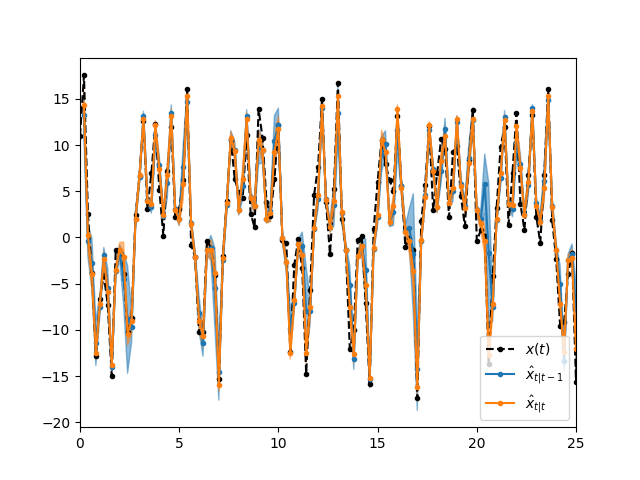
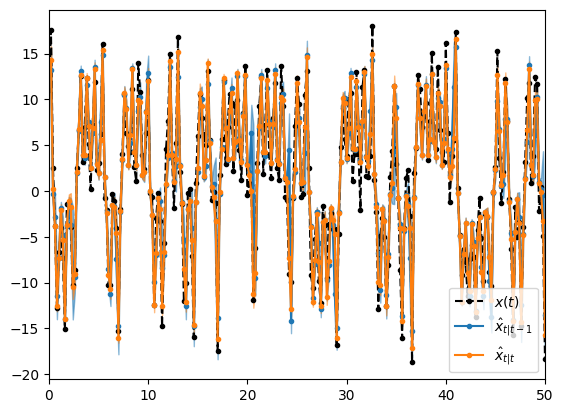
結果
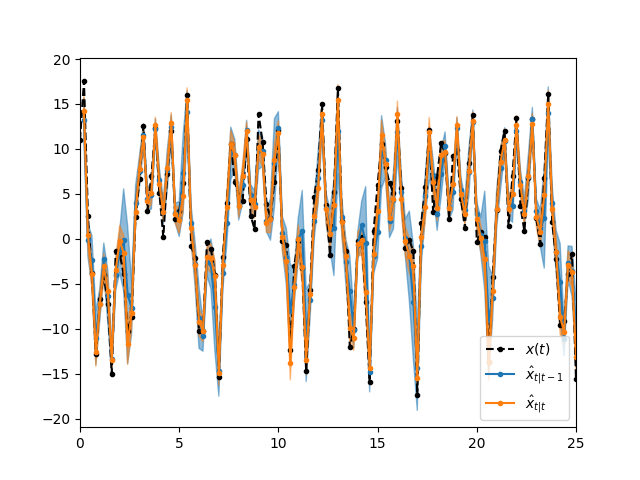
EnKFではデータにフィットしつつノイズによる誤差の広がりを分布として推定できています。
予測分布よりもフィルタ分布の方が、情報が増えて精度が向上している(分布の幅が狭くなっている)ことが見て取れます。
EnKFの場合はそもそも粒子の退化が起こらないため $T$ が長くなっても問題なく分布推定が可能です。
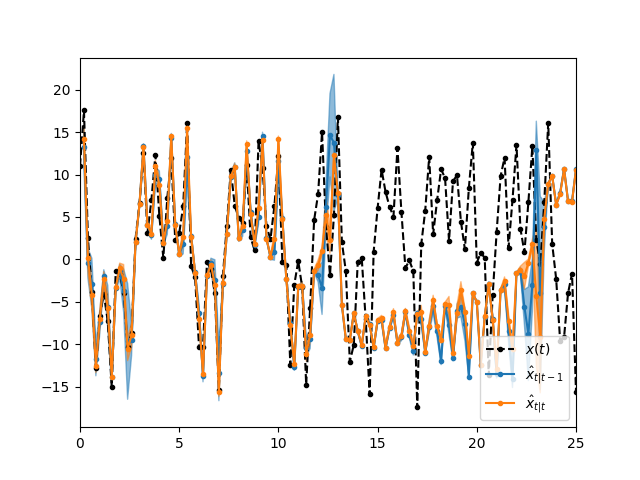
PFは $t>10$ あたりから大きくズレていますが、MPFでは $t=50$ まで良くデータ通りの推論が得られていて、アンサンブル退化による精度悪化を改善できていることがわかります。
おわりに
本記事では、時間変動を捉えるためのモデルとして状態空間モデルと各種フィルタ手法について、理論から数値実験までを概観しました。 最後までお読みいただき、ありがとうございました。
参考文献
- 樋口知之『データ同化入門』朝倉書店 2011.
- 淡路敏之ほか『データ同化―観測・実験とモデルを融合するイノベーション』京都大学学術出版会 2009.
- 江崎貴裕『データ分析のための数理モデル入門 本質をとらえた分析のために』ソシム 2020.
- 全データ $t=1,\dots, T$ が揃ってから1期分遡るのを固定点平滑化と呼び、他の遡り方もいくつか存在する。↩
- $G _ t\boldsymbol v _ t$ もガウスノイズなのでまとめてノイズ項としてもよいが、のちの拡張と記号を合わせるため分けている。↩
- ここではシステムモデルが非線形の場合を扱ったが、観測モデルが非線形の場合でも同様に線形近似することもできる。↩
- ランダムな移動を繰り返すことで複雑な確率分布をサンプリングする手法。ベイズ推定や機械学習の分野で広く使われている。↩
- 得られているサンプルから繰り返し再抽出することで元の分布の統計量を推定する手法↩
- $\alpha _ j<0 $ を含むので重み付き平均と呼ぶには語弊があるかもしれない。また、$n\leq2$ では自明な解しか無いので $n\geq 3$ とする必要がある。↩
- 気候変動を簡易的に表すシミュレーションモデル。カオス的な振る舞いをするため数値計算のデモンストレーションとしても用いられる。↩