マイクロアドのアプリケーションエンジニアの x です。数ヶ月前からストリームアプリの開発を担当しています。ある案件を検証する為、Structured Streaming を使ってみました。
マイクロアドでは、Spark Streaming でデータを5~10秒毎に処理しています。Spark Streaming については、順序保証型分散ストリーム処理 と、 Spark Streaming と Kryo シリアライザーの話 でも解説していますので、ご覧ください。
Spark Streaming は強力なストリーミングですが、遅延したデータを簡単に処理する方法がなく、マイクロアドでも問題となっています。さしあたり解決方法として、
処理する時に event time(実際にイベントが発生した時間)ではなく、ingestion time(データがソースに入った時間)を見る
遅延したデータを捨てる
この二つの方法が考えられます。
2.1 バージョンにおける、Spark がもう一つのストリーム処理を提供しています。そのストリーム処理が Structured Streaming です。
Structured Streaming とは
Structured Streaming では、ソースからストリームに入って来るデータの一つ一つは、無制限入力テーブルに追加される新しい行のように扱われます。クエリ(例:集計)が「入力テーブル」に実行されると「結果テーブル」が生成されます。
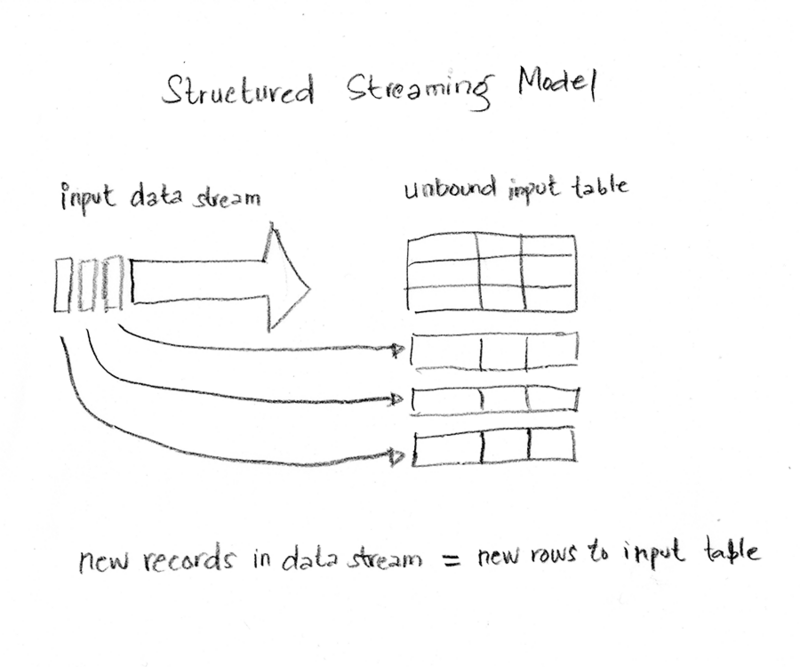
以下のプログラミングモデル図のように、引き起こされる各間隔毎(trigger interval)に、入力テーブルに新しい行が追加され、クエリーが実行され、結果テーブルが更新されます。

Structured Streaming は二つ、三つの出力モードに対応しています。
- Complete - 各トリガーの後で、結果テーブル全体が出力されます。
- Append - 最後のトリガーで、結果テーブルに追加された行が出力されます。
- Update - 最後のトリガーで、結果テーブルに更新された行が表示されます。この出力モードは Apache Spark 2.1.1 から対応されています。
Structured Streaming の詳細はこちらです。
処理
この解説では、10分単位のウィンドウで分割された広告枠インプレッション数を集計します。この10分単位のウィンドウは、要求が発生した時間(event time)に基づいていて、取り込み時間(ingestion time)や処理時間(processing time)には基づいていません。遅延したデータを処理するために、スライド間隔を5分に設定してウィンドウをオーバーラップするように設定します。
動きは図のようになります。

ウィンドウ操作の詳細はこちらです。
簡潔にする為、ソースに入って来るデータフォーマットは
{timestamp: "HH:mm", spotId: xxx}
の JSON 形式です。
サンプルコードは以下になります。
<省略> // ウィンドウの持続時間 val windowDuration: String = "600 seconds" // ウィンドウ操作の間隔 val slidingInterval: String = "300 seconds" val windowedCounts: Dataset[Row] = imp.groupBy( window($"timestamp", windowDuration, slidingInterval) ).count().orderBy("window") // コンソールに出力する val query: StreamingQuery = imp.writeStream .outputMode("complete") .format("console") .option("truncate", "false") .start() <省略>
上記のコードで10分単位でデータが分割され、それが5分毎に行われます。つまり、ウィンドウは12:00-12:10、12:05-12:15、12:10-12:20などの範囲となります。このウィンドウ内のインプレッションを集計します。例えば、広告インプレッションの発生時間が12:06であれば、12:00-12:10と12:05-12:15の集計結果が更新されます。
最後に、結果はウィンドウ範囲と広告枠 ID 毎に分けて、ウィンドウ範囲の順で出力します。
例として、以下のデータを処理しました、
{timestamp: "12:01", spotId: 111}
{timestamp: "12:03", spotId: 222}
{timestamp: "12:06", spotId: 111}
{timestamp: "12:09", spotId: 303}
{timestamp: "12:12", spotId: 222}
{timestamp: "12:14", spotId: 111}
流れは次の図になります。

遅延したデータがあるとどうなるでしょうか。
遅延対応
Structured Streaming では、不完全な集計結果を長時間維持できるので、遅延したデータを処理することが可能となり、その都度結果を更新することができます。
以下の図に、インプレッション発生時間は12:03でしたがソースに入ってくるのは12:12でした。ストリーム処理は12:00-12:10ウィンドウにマップされ、集計結果を更新します。
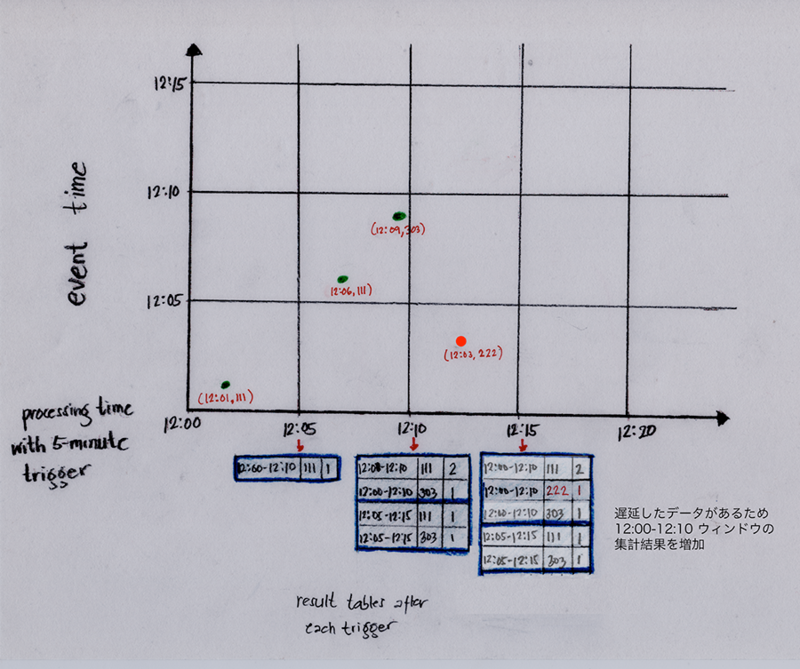
これで遅延したデータを処理することが可能になりますが、インメモリに溜まっている古いデータ、つまり長い時間更新されていないデータがいつまでも削除されないという問題が発生します。それを解決する為にウォーターマーキングという仕組みを使います。
ウォーターマーキングとは
ウォーターマーキングは Spark 2.1 以降から対応しています。ウォーターマーキングではスパークエンジンが event time カラムを認識して、古いデータを除外していきます。
ウォーターマークの計算式は
最大 event time - 遅延閾値
となります。
引き起こされる間隔毎に上記の計算式でウォーターマークが更新されます。
遅延したデータの event time がウォーターマーク以内に限り、そのデータは処理され、それ以外では処理されません。
ウォーターマーキングを使う場合、withWatermark()を呼び出します。ただし、ウォーターマーキングを有効にする為には以下の条件を満たす必要があります。
- sink の出力モードは
appendあるいはupdate - 集計結果またはウィンドウが
event timeカラムをもっている withWatermark()と集計で使用する event time カラムが一致withWatermark()は集計前に呼び出す
前のサンプルコードにwithWatermark()を追加し、実引数としてはtimestamp(ウォーターマークが参照するカラム)と600 seconds(遅延閾値)を渡していましたが、出力モードをappendに変更しました。
<省略> val delayThreshold: String = "600 seconds" val windowedCounts: Dataset[Row] = imp .withWatermark("timestamp", delayThreshold) .groupBy( window($"timestamp", windowDuration, slidingInterval), $"spotId") .count() val query: StreamingQuery = windowedCounts .writeStream .outputMode("append") .format("console") .option("truncate", "false") .start() <省略>

図のように、処理時間12:15のトリガーまで最大 event time は12:13でした。遅延閾値が10分(600 seconds)なので、12:15-12:20のウォーターマークは12:03になります。12:03未満のデータは無視され捨てられ、それ以外は処理されます。
出力モードはappendなので、エンジンでは10分(遅延閾値)後まで遅延データを待ちます。10分を過ぎ、ある条件(watermark > ウィンドウ終了時間)を満たしたら、結果テーブルに集計結果が追加され、メモリからそのウィンドウのデータが削除されます。
つまり、図のように、12:00-12:10ウィンドウの場合、12:20まで遅延データを待ちます。12:25のトリガーで12:25-12:30のウォーターマークを計算しました。12:25-12:30のウォーターマークは、最大 event time が12:21なので遅延閾値を引き12:11になります。12:10(12:00-12:10ウィンドウの終了時間)が12:11より小さいので、12:00-12:10ウィンドウの集計結果が12:30に結果テーブルに追加されます。
これで遅延しているデータを簡単に処理することができました。
出力モードがupdateの場合、ウォーターマークの動きが少し違うので、注意が必要です。
まとめ
この記事では
- Structured Streaming のプログラミングモデル
- Structured Streaming で遅延したデータを処理することが可能になる
- Structured Streaming でのウォーターマークの役割
について話をしました。
リアルタイムデータを処理する時は Structured Streaming の方が適切かと思います。また機会があれば(あるとは言ってない) Structured Streaming の連続処理とチェックポインティングについて話したいと思います。
参照
*1 Spark.apache.org. (2019). Structured Streaming Programming Guide - Spark 2.4.3 Documentation. [online] Available at: https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html#overview [Accessed 24 Jun. 2019].
*2 Spark.apache.org. (2019). Spark Streaming - Spark 2.4.3 Documentation. [online] Available at: https://spark.apache.org/docs/latest/streaming-programming-guide.html#window-operations [Accessed 24 Jun. 2019].